 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Distill Not Only Data but Also Rewards: Can Smaller Language Models Surpass Larger Ones?
Feb 26, 2025



Distilling large language models (LLMs) typically involves transferring the teacher model's responses through supervised fine-tuning (SFT). However, this approach neglects the potential to distill both data (output content) and reward signals (quality evaluations). Extracting reliable reward signals directly from teacher models is challenging, as LLMs are optimized for generation rather than evaluation, often resulting in biased or inconsistent assessments. To address this limitation, we propose a novel distillation pipeline that transfers both responses and rewards. Our method generates pseudo-rewards through a self-supervised mechanism that leverages the inherent structure of both teacher and student responses, enabling reward learning without explicit external evaluation. The reward model subsequently guides reinforcement learning (RL), allowing iterative refinement of the student model after an SFT warm-up phase. Experiments on GSM8K and MMLU-PRO demonstrate that our method consistently outperforms traditional SFT-based approaches, enabling student models to surpass the performance of their teachers. This work highlights the potential for scalable, efficient distillation through structured self-supervised reward learning, reducing dependence on external reward supervision.
Lean and Mean: Decoupled Value Policy Optimization with Global Value Guidance
Feb 24, 2025Proximal Policy Optimization (PPO)-based Reinforcement Learning from Human Feedback (RLHF) is essential for aligning large language models (LLMs) with human preferences. It requires joint training of an actor and critic with a pretrained, fixed reward model for guidance. This approach increases computational complexity and instability due to actor-critic interdependence. Additionally, PPO lacks access to true environment rewards in LLM tasks, limiting its adaptability. Under such conditions, pretraining a value model or a reward model becomes equivalent, as both provide fixed supervisory signals without new ground-truth feedback. To address these issues, we propose \textbf{Decoupled Value Policy Optimization (DVPO)}, a lean framework that replaces traditional reward modeling with a pretrained \emph{global value model (GVM)}. The GVM is conditioned on policy trajectories and predicts token-level return-to-go estimates. By decoupling value model from policy training (via frozen GVM-driven RL objectives), DVPO eliminates actor-critic interdependence, reducing GPU memory usage by 40\% and training time by 35\% compared to conventional RLHF. Experiments across benchmarks show DVPO outperforms efficient RLHF methods (e.g., DPO) while matching state-of-the-art PPO in performance.
Token-level Proximal Policy Optimization for Query Generation
Nov 01, 2024Query generation is a critical task for web search engines (e.g. Google, Bing) and recommendation systems. Recently, state-of-the-art query generation methods leverage Large Language Models (LLMs) for their strong capabilities in context understanding and text generation. However, they still face challenges in generating high-quality queries in terms of inferring user intent based on their web search interaction history. In this paper, we propose Token-level Proximal Policy Optimization (TPPO), a noval approach designed to empower LLMs perform better in query generation through fine-tuning. TPPO is based on the Reinforcement Learning from AI Feedback (RLAIF) paradigm, consisting of a token-level reward model and a token-level proximal policy optimization module to address the sparse reward challenge in traditional RLAIF frameworks. To evaluate the effectiveness and robustness of TPPO, we conducted experiments on both open-source dataset and an industrial dataset that was collected from a globally-used search engine. The experimental results demonstrate that TPPO significantly improves the performance of query generation for LLMs and outperforms its existing competitors.
Self-Evolved Reward Learning for LLMs
Nov 01, 2024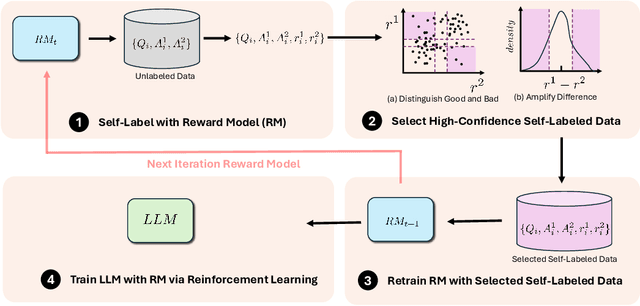
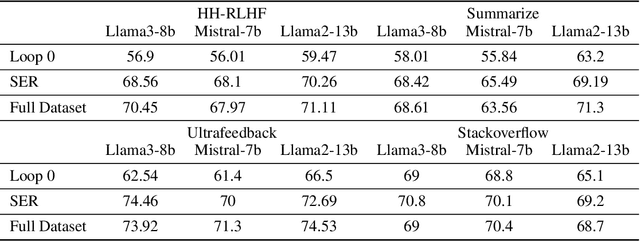
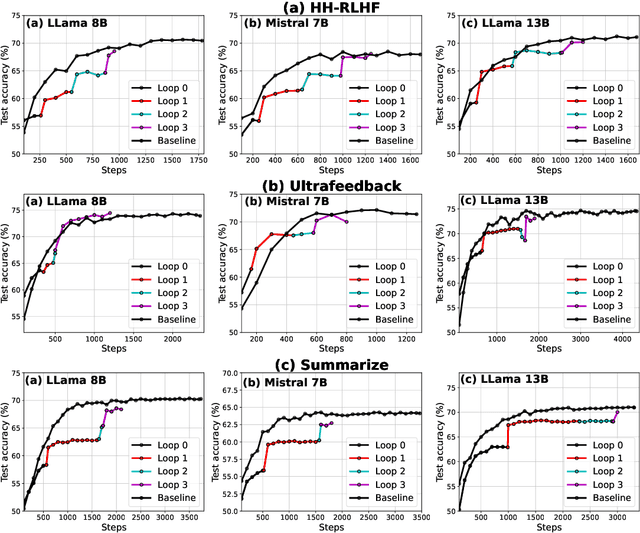
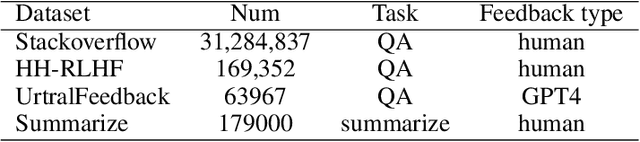
Reinforcement Learning from Human Feedback (RLHF) is a crucial technique for aligning language models with human preferences, playing a pivotal role in the success of conversational models like GPT-4, ChatGPT, and Llama 2. A core challenge in employing RLHF lies in training a reliable reward model (RM), which relies on high-quality labels typically provided by human experts or advanced AI system. These methods can be costly and may introduce biases that affect the language model's responses. As language models improve, human input may become less effective in further enhancing their performance. In this paper, we propose Self-Evolved Reward Learning (SER), a novel approach where the RM generates additional training data to iteratively improve itself. We conducted extensive experiments on multiple datasets such as HH-RLHF and UltraFeedback, using models like Mistral and Llama 3, and compare SER against various baselines. Our results demonstrate that even with limited human-annotated data, learning from self-feedback can robustly enhance RM performance, thereby boosting the capabilities of large language models (LLMs).