 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
Repository Structure-Aware Training Makes SLMs Better Issue Resolver
Dec 26, 2024Language models have been applied to various software development tasks, but the performance varies according to the scale of the models. Large Language Models (LLMs) outperform Small Language Models (SLMs) in complex tasks like repository-level issue resolving, but raise concerns about privacy and cost. In contrast, SLMs are more accessible but under-perform in complex tasks. In this paper, we introduce ReSAT (Repository Structure-Aware Training), construct training data based on a large number of issues and corresponding pull requests from open-source communities to enhance the model's understanding of repository structure and issue resolving ability. We construct two types of training data: (1) localization training data, a multi-level progressive localization data to improve code understanding and localization capability; (2) code edit training data, which improves context-based code editing capability. The evaluation results on SWE-Bench-verified and RepoQA demonstrate that ReSAT effectively enhances SLMs' issue-resolving and repository-level long-context understanding capabilities.
Dehallucinating Parallel Context Extension for Retrieval-Augmented Generation
Dec 19, 2024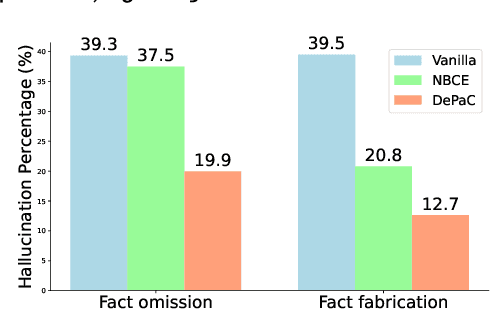
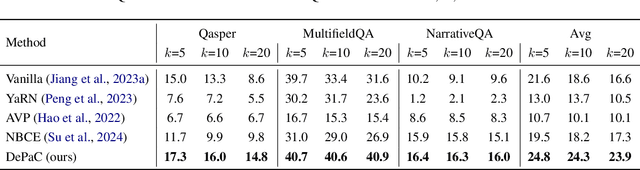

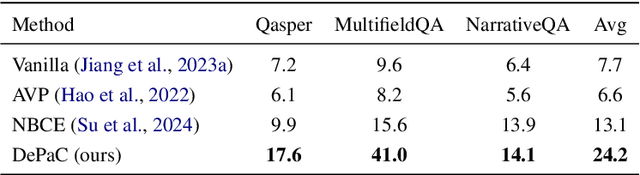
Large language models (LLMs) are susceptible to generating hallucinated information, despite the integration of retrieval-augmented generation (RAG). Parallel context extension (PCE) is a line of research attempting to effectively integrating parallel (unordered) contexts, while it still suffers from hallucinations when adapted to RAG scenarios. In this paper, we propose DePaC (Dehallucinating Parallel Context Extension), which alleviates the hallucination problem with context-aware negative training and information-calibrated aggregation. DePaC is designed to alleviate two types of in-context hallucination: fact fabrication (i.e., LLMs present claims that are not supported by the contexts) and fact omission (i.e., LLMs fail to present claims that can be supported by the contexts). Specifically, (1) for fact fabrication, we apply the context-aware negative training that fine-tunes the LLMs with negative supervisions, thus explicitly guiding the LLMs to refuse to answer when contexts are not related to questions; (2) for fact omission, we propose the information-calibrated aggregation which prioritizes context windows with higher information increment from their contexts. The experimental results on nine RAG tasks demonstrate that DePaC significantly alleviates the two types of hallucination and consistently achieves better performances on these tasks.
STAND-Guard: A Small Task-Adaptive Content Moderation Model
Nov 07, 2024

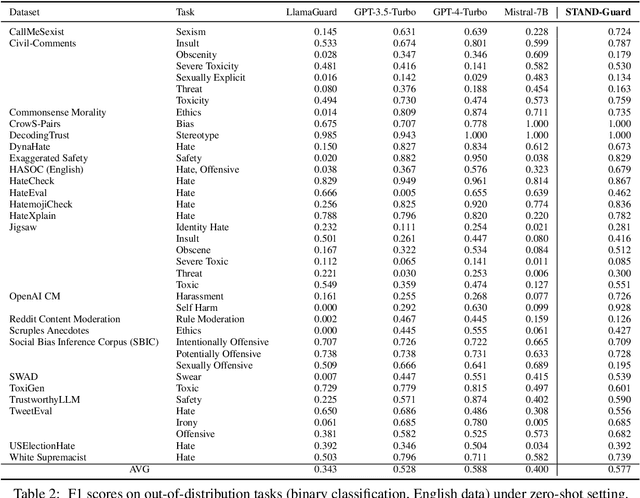

Content moderation, the process of reviewing and monitoring the safety of generated content, is important for development of welcoming online platforms and responsible large language models. Content moderation contains various tasks, each with its unique requirements tailored to specific scenarios. Therefore, it is crucial to develop a model that can be easily adapted to novel or customized content moderation tasks accurately without extensive model tuning. This paper presents STAND-GUARD, a Small Task-Adaptive coNtent moDeration model. The basic motivation is: by performing instruct tuning on various content moderation tasks, we can unleash the power of small language models (SLMs) on unseen (out-of-distribution) content moderation tasks. We also carefully study the effects of training tasks and model size on the efficacy of cross-task fine-tuning mechanism. Experiments demonstrate STAND-Guard is comparable to GPT-3.5-Turbo across over 40 public datasets, as well as proprietary datasets derived from real-world business scenarios. Remarkably, STAND-Guard achieved nearly equivalent results to GPT-4-Turbo on unseen English binary classification tasks
Self-Evolved Reward Learning for LLMs
Nov 01, 2024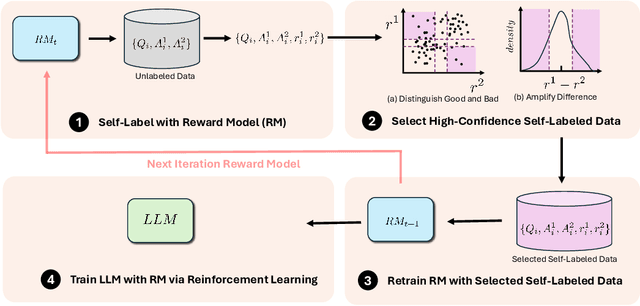
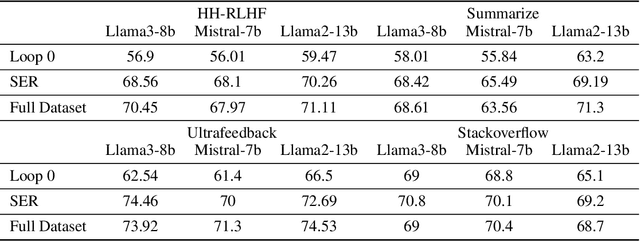
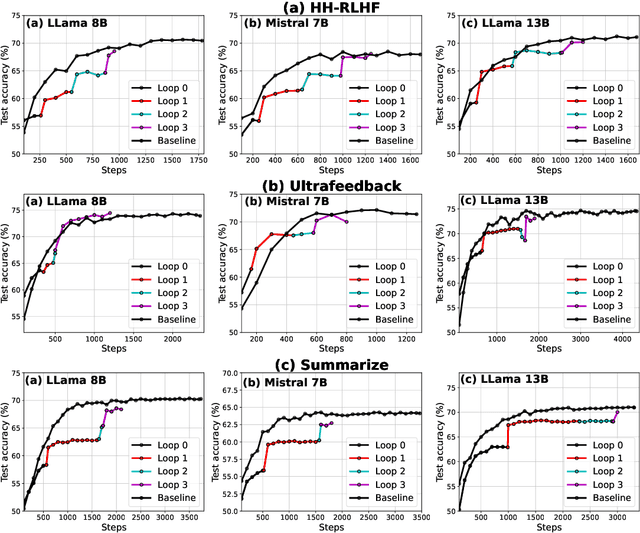
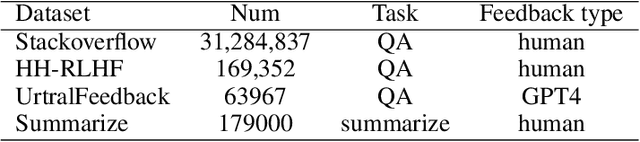
Reinforcement Learning from Human Feedback (RLHF) is a crucial technique for aligning language models with human preferences, playing a pivotal role in the success of conversational models like GPT-4, ChatGPT, and Llama 2. A core challenge in employing RLHF lies in training a reliable reward model (RM), which relies on high-quality labels typically provided by human experts or advanced AI system. These methods can be costly and may introduce biases that affect the language model's responses. As language models improve, human input may become less effective in further enhancing their performance. In this paper, we propose Self-Evolved Reward Learning (SER), a novel approach where the RM generates additional training data to iteratively improve itself. We conducted extensive experiments on multiple datasets such as HH-RLHF and UltraFeedback, using models like Mistral and Llama 3, and compare SER against various baselines. Our results demonstrate that even with limited human-annotated data, learning from self-feedback can robustly enhance RM performance, thereby boosting the capabilities of large language models (LLMs).
GRIN: GRadient-INformed MoE
Sep 18, 2024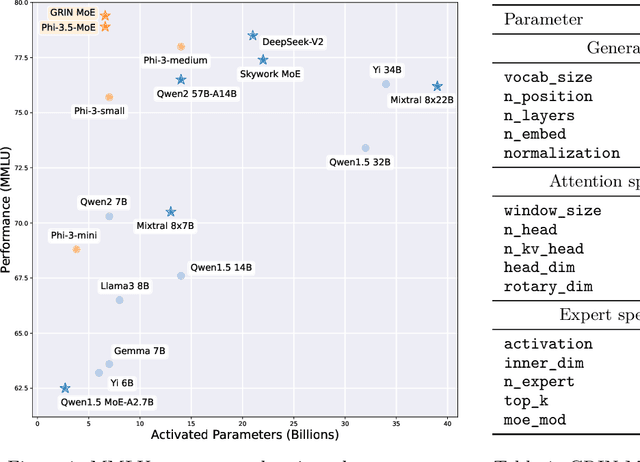
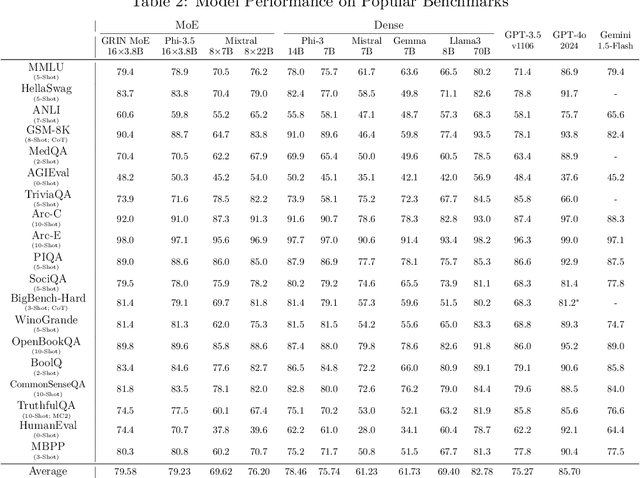
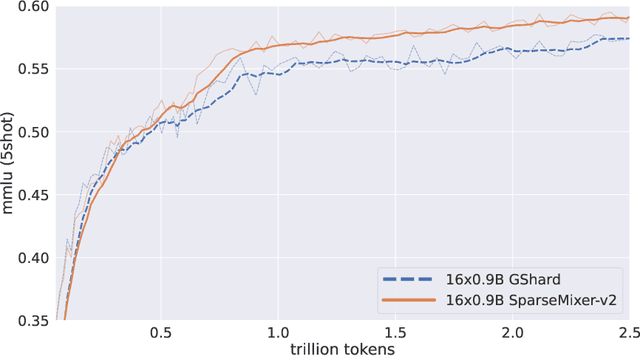

Mixture-of-Experts (MoE) models scale more effectively than dense models due to sparse computation through expert routing, selectively activating only a small subset of expert modules. However, sparse computation challenges traditional training practices, as discrete expert routing hinders standard backpropagation and thus gradient-based optimization, which are the cornerstone of deep learning. To better pursue the scaling power of MoE, we introduce GRIN (GRadient-INformed MoE training), which incorporates sparse gradient estimation for expert routing and configures model parallelism to avoid token dropping. Applying GRIN to autoregressive language modeling, we develop a top-2 16$\times$3.8B MoE model. Our model, with only 6.6B activated parameters, outperforms a 7B dense model and matches the performance of a 14B dense model trained on the same data. Extensive evaluations across diverse tasks demonstrate the potential of GRIN to significantly enhance MoE efficacy, achieving 79.4 on MMLU, 83.7 on HellaSwag, 74.4 on HumanEval, and 58.9 on MATH.
Make Your LLM Fully Utilize the Context
Apr 26, 2024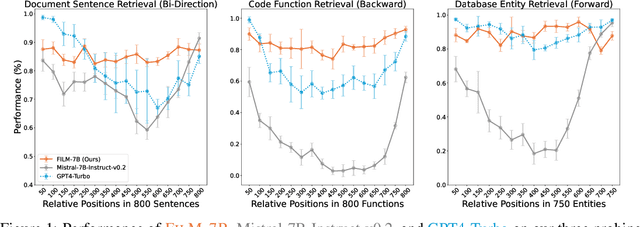
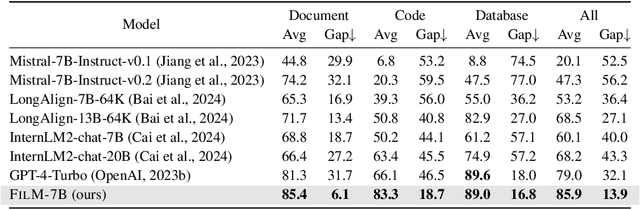
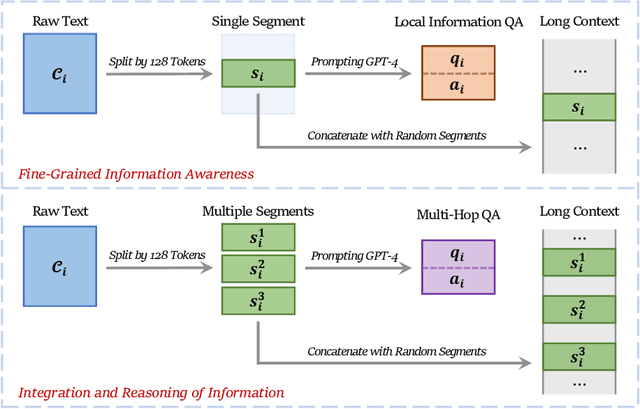
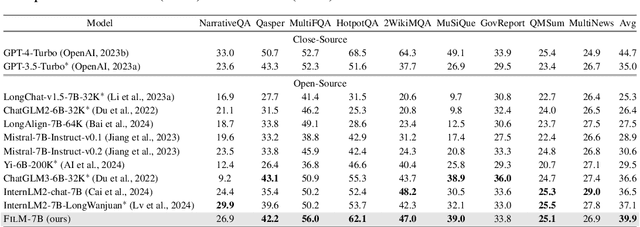
While many contemporary large language models (LLMs) can process lengthy input, they still struggle to fully utilize information within the long context, known as the lost-in-the-middle challenge. We hypothesize that it stems from insufficient explicit supervision during the long-context training, which fails to emphasize that any position in a long context can hold crucial information. Based on this intuition, our study presents information-intensive (IN2) training, a purely data-driven solution to overcome lost-in-the-middle. Specifically, IN2 training leverages a synthesized long-context question-answer dataset, where the answer requires (1) fine-grained information awareness on a short segment (~128 tokens) within a synthesized long context (4K-32K tokens), and (2) the integration and reasoning of information from two or more short segments. Through applying this information-intensive training on Mistral-7B, we present FILM-7B (FILl-in-the-Middle). To thoroughly assess the ability of FILM-7B for utilizing long contexts, we design three probing tasks that encompass various context styles (document, code, and structured-data context) and information retrieval patterns (forward, backward, and bi-directional retrieval). The probing results demonstrate that FILM-7B can robustly retrieve information from different positions in its 32K context window. Beyond these probing tasks, FILM-7B significantly improves the performance on real-world long-context tasks (e.g., 23.5->26.9 F1 score on NarrativeQA), while maintaining a comparable performance on short-context tasks (e.g., 59.3->59.2 accuracy on MMLU). Github Link: https://github.com/microsoft/FILM.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
Compositional API Recommendation for Library-Oriented Code Generation
Feb 29, 2024
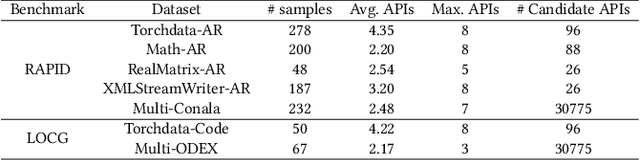
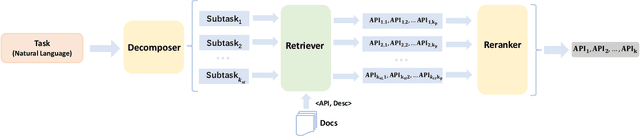
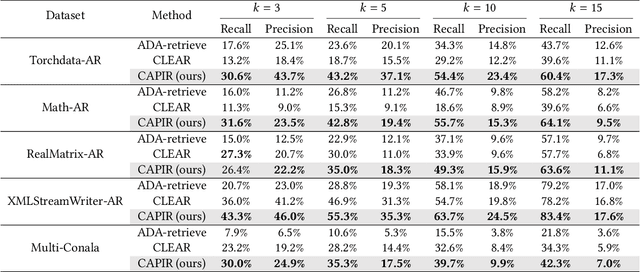
Large language models (LLMs) have achieved exceptional performance in code generation. However, the performance remains unsatisfactory in generating library-oriented code, especially for the libraries not present in the training data of LLMs. Previous work utilizes API recommendation technology to help LLMs use libraries: it retrieves APIs related to the user requirements, then leverages them as context to prompt LLMs. However, developmental requirements can be coarse-grained, requiring a combination of multiple fine-grained APIs. This granularity inconsistency makes API recommendation a challenging task. To address this, we propose CAPIR (Compositional API Recommendation), which adopts a "divide-and-conquer" strategy to recommend APIs for coarse-grained requirements. Specifically, CAPIR employs an LLM-based Decomposer to break down a coarse-grained task description into several detailed subtasks. Then, CAPIR applies an embedding-based Retriever to identify relevant APIs corresponding to each subtask. Moreover, CAPIR leverages an LLM-based Reranker to filter out redundant APIs and provides the final recommendation. To facilitate the evaluation of API recommendation methods on coarse-grained requirements, we present two challenging benchmarks, RAPID (Recommend APIs based on Documentation) and LOCG (Library-Oriented Code Generation). Experimental results on these benchmarks, demonstrate the effectiveness of CAPIR in comparison to existing baselines. Specifically, on RAPID's Torchdata-AR dataset, compared to the state-of-the-art API recommendation approach, CAPIR improves recall@5 from 18.7% to 43.2% and precision@5 from 15.5% to 37.1%. On LOCG's Torchdata-Code dataset, compared to code generation without API recommendation, CAPIR improves pass@100 from 16.0% to 28.0%.
Learning From Mistakes Makes LLM Better Reasoner
Nov 14, 2023Large language models (LLMs) recently exhibited remarkable reasoning capabilities on solving math problems. To further improve this capability, this work proposes Learning from Mistakes (LeMa), akin to human learning processes. Consider a human student who failed to solve a math problem, he will learn from what mistake he has made and how to correct it. Mimicking this error-driven learning process, LeMa fine-tunes LLMs on mistake-correction data pairs generated by GPT-4. Specifically, we first collect inaccurate reasoning paths from various LLMs and then employ GPT-4 as a "corrector" to (1) identify the mistake step, (2) explain the reason for the mistake, and (3) correct the mistake and generate the final answer. Experimental results demonstrate the effectiveness of LeMa: across five backbone LLMs and two mathematical reasoning tasks, LeMa consistently improves the performance compared with fine-tuning on CoT data alone. Impressively, LeMa can also benefit specialized LLMs such as WizardMath and MetaMath, achieving 85.4% pass@1 accuracy on GSM8K and 27.1% on MATH. This surpasses the SOTA performance achieved by non-execution open-source models on these challenging tasks. Our code, data and models will be publicly available at https://github.com/microsoft/LEMA.