 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAND-Guard: A Small Task-Adaptive Content Moderation Model
Nov 07, 2024

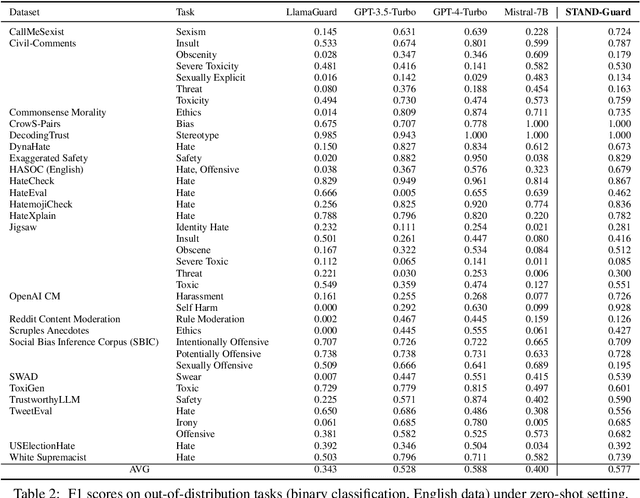

Content moderation, the process of reviewing and monitoring the safety of generated content, is important for development of welcoming online platforms and responsible large language models. Content moderation contains various tasks, each with its unique requirements tailored to specific scenarios. Therefore, it is crucial to develop a model that can be easily adapted to novel or customized content moderation tasks accurately without extensive model tuning. This paper presents STAND-GUARD, a Small Task-Adaptive coNtent moDeration model. The basic motivation is: by performing instruct tuning on various content moderation tasks, we can unleash the power of small language models (SLMs) on unseen (out-of-distribution) content moderation tasks. We also carefully study the effects of training tasks and model size on the efficacy of cross-task fine-tuning mechanism. Experiments demonstrate STAND-Guard is comparable to GPT-3.5-Turbo across over 40 public datasets, as well as proprietary datasets derived from real-world business scenarios. Remarkably, STAND-Guard achieved nearly equivalent results to GPT-4-Turbo on unseen English binary classification tasks
CMMD: Cross-Metric Multi-Dimensional Root Cause Analysis
Mar 30, 2022
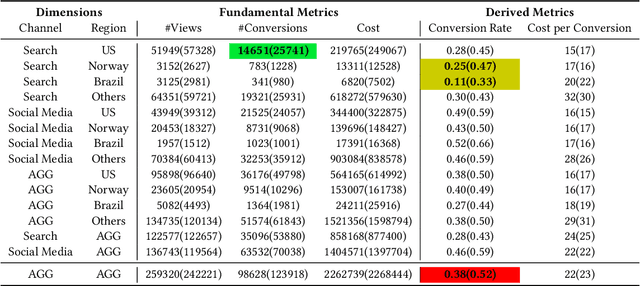


In large-scale online services, crucial metrics, a.k.a., key performance indicators (KPIs), are monitored periodically to check their running statuses. Generally, KPIs are aggregated along multiple dimensions and derived by complex calculations among fundamental metrics from the raw data. Once abnormal KPI values are observed, root cause analysis (RCA) can be applied to identify the reasons for anomalies, so that we can troubleshoot quickly. Recently, several automatic RCA techniques were proposed to localize the related dimensions (or a combination of dimensions) to explain the anomalies. However, their analyses are limited to the data on the abnormal metric and ignore the data of other metrics which may be also related to the anomalies, leading to imprecise or even incorrect root causes. To this end, we propose a cross-metric multi-dimensional root cause analysis method, named CMMD, which consists of two key components: 1) relationship modeling, which utilizes graph neural network (GNN) to model the unknown complex calculation among metrics and aggregation function among dimensions from historical data; 2) root cause localization, which adopts the genetic algorithm to efficiently and effectively dive into the raw data and localize the abnormal dimension(s) once the KPI anomalies are detected. Experiments on synthetic datasets, public datasets and online production environment demonstrate the superiority of our proposed CMMD method compared with baselines. Currently, CMMD is running as an online service in Microsoft Azure.
Learning Timestamp-Level Representations for Time Series with Hierarchical Contrastive Loss
Jun 19, 2021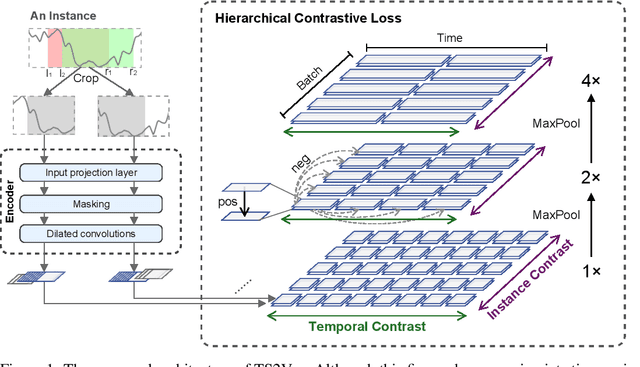

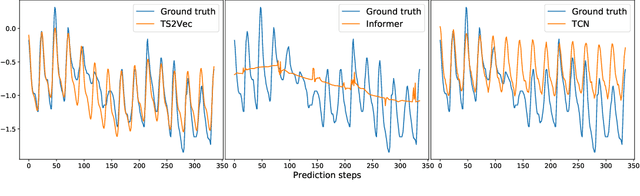
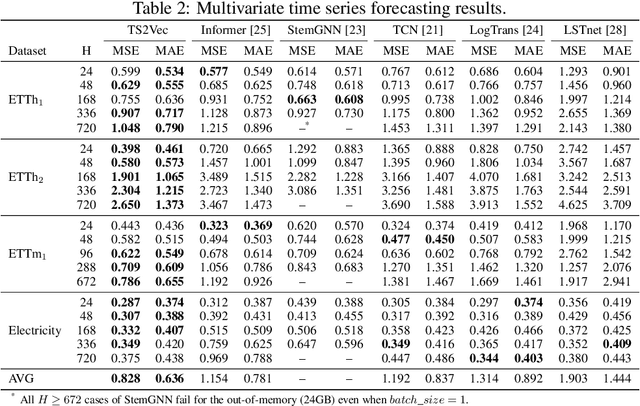
This paper presents TS2Vec, a universal framework for learning timestamp-level representations of time series. Unlike existing methods, TS2Vec performs timestamp-wise discrimination, which learns a contextual representation vector directly for each timestamp. We find that the learned representations have superior predictive ability. A linear regression trained on top of the learned representations outperforms previous SOTAs for supervised time series forecasting. Also, the instance-level representations can be simply obtained by applying a max pooling layer on top of learned representations of all timestamps. We conduct extensive experiments on time series classification tasks to evaluate the quality of instance-level representations. As a result, TS2Vec achieves significant improvement compared with existing SOTAs of unsupervised time series representation on 125 UCR datasets and 29 UEA datasets. The source code is publicly available at https://github.com/yuezhihan/ts2vec.
Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting
Mar 13, 2021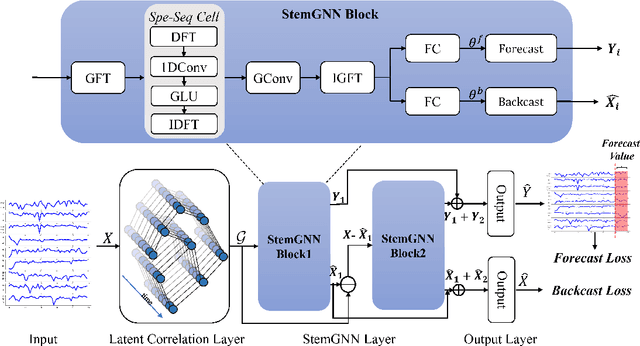

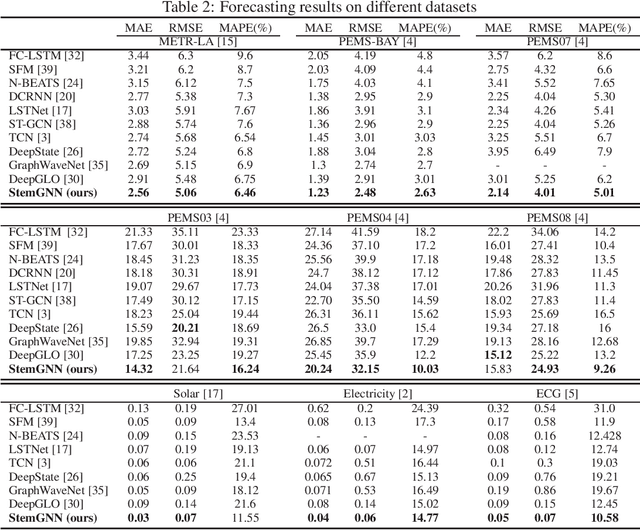
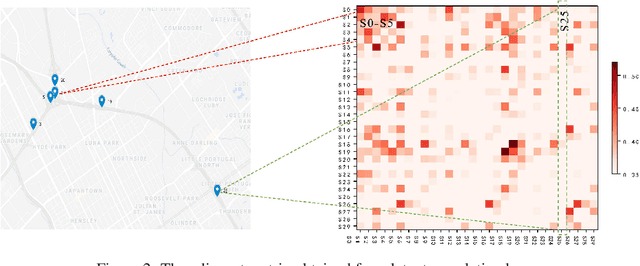
Multivariate time-series forecasting plays a crucial role in many real-world applications. It is a challenging problem as one needs to consider both intra-series temporal correlations and inter-series correlations simultaneously. Recently, there have been multiple works trying to capture both correlations, but most, if not all of them only capture temporal correlations in the time domain and resort to pre-defined priors as inter-series relationships. In this paper, we propose Spectral Temporal Graph Neural Network (StemGNN) to further improve the accuracy of multivariate time-series forecasting. StemGNN captures inter-series correlations and temporal dependencies \textit{jointly} in the \textit{spectral domain}. It combines Graph Fourier Transform (GFT) which models inter-series correlations and Discrete Fourier Transform (DFT) which models temporal dependencies in an end-to-end framework. After passing through GFT and DFT, the spectral representations hold clear patterns and can be predicted effectively by convolution and sequential learning modules. Moreover, StemGNN learns inter-series correlations automatically from the data without using pre-defined priors. We conduct extensive experiments on ten real-world datasets to demonstrate the effectiveness of StemGNN. Code is available at https://github.com/microsoft/StemGNN/
Multivariate Time-series Anomaly Detection via Graph Attention Network
Sep 04, 2020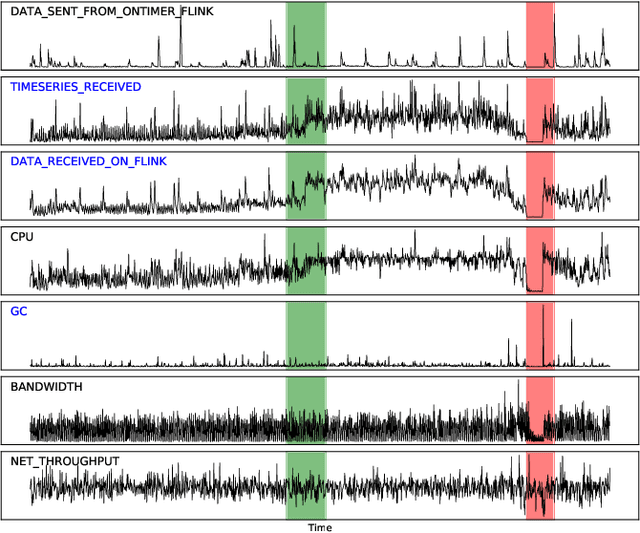
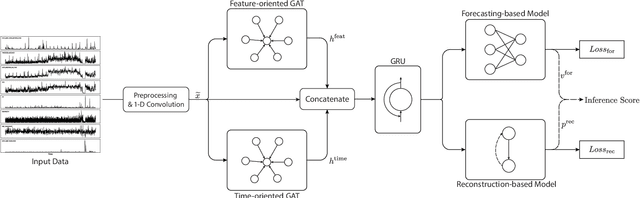
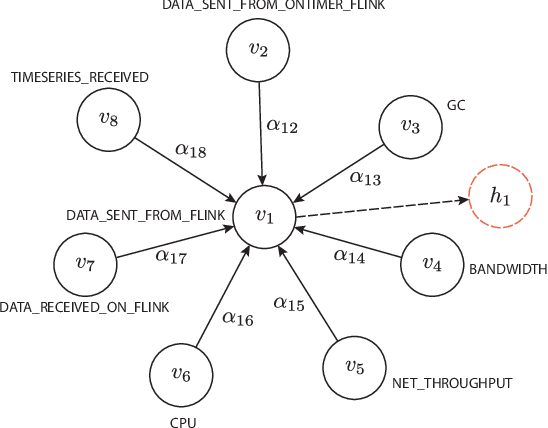
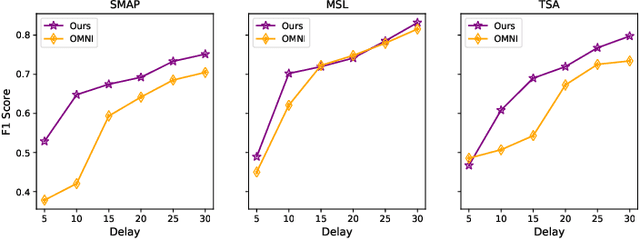
Anomaly detection on multivariate time-series is of great importance in both data mining research and industrial applications. Recent approaches have achieved significant progress in this topic, but there is remaining limitations. One major limitation is that they do not capture the relationships between different time-series explicitly, resulting in inevitable false alarms. In this paper, we propose a novel self-supervised framework for multivariate time-series anomaly detection to address this issue. Our framework considers each univariate time-series as an individual feature and includes two graph attention layers in parallel to learn the complex dependencies of multivariate time-series in both temporal and feature dimensions. In addition, our approach jointly optimizes a forecasting-based model and are construction-based model, obtaining better time-series representations through a combination of single-timestamp prediction and reconstruction of the entire time-series. We demonstrate the efficacy of our model through extensive experiments. The proposed method outperforms other state-of-the-art models on three real-world datasets. Further analysis shows that our method has good interpretability and is useful for anomaly diagnosis.
Automated Model Selection for Time-Series Anomaly Detection
Aug 25, 2020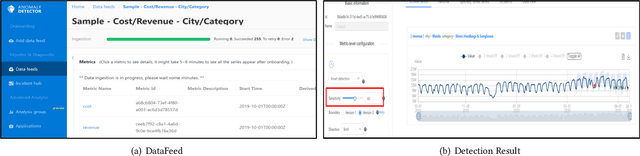

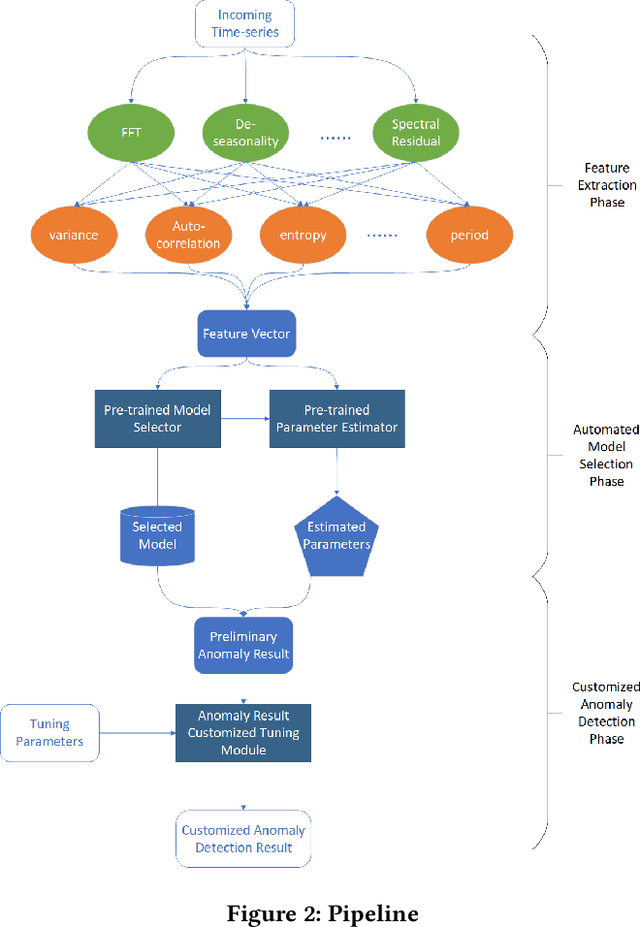

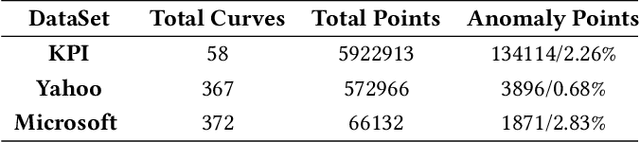
Time-series anomaly detection is a popular topic in both academia and industrial fields. Many companies need to monitor thousands of temporal signals for their applications and services and require instant feedback and alerts for potential incidents in time. The task is challenging because of the complex characteristics of time-series, which are messy, stochastic, and often without proper labels. This prohibits training supervised models because of lack of labels and a single model hardly fits different time series. In this paper, we propose a solution to address these issues. We present an automated model selection framework to automatically find the most suitable detection model with proper parameters for the incoming data. The model selection layer is extensible as it can be updated without too much effort when a new detector is available to the service. Finally, we incorporate a customized tuning algorithm to flexibly filter anomalies to meet customers' criteria. Experiments on real-world datasets show the effectiveness of our solution.
Time-Series Anomaly Detection Service at Microsoft
Jun 10, 2019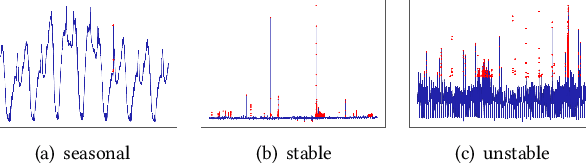
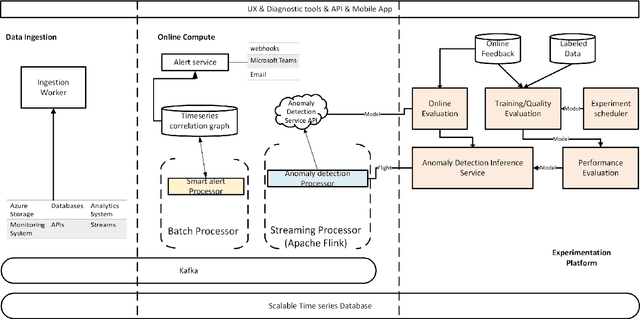

Large companies need to monitor various metrics (for example, Page Views and Revenue) of their applications and services in real time. At Microsoft, we develop a time-series anomaly detection service which helps customers to monitor the time-series continuously and alert for potential incidents on time. In this paper, we introduce the pipeline and algorithm of our anomaly detection service, which is designed to be accurate, efficient and general. The pipeline consists of three major modules, including data ingestion, experimentation platform and online compute. To tackle the problem of time-series anomaly detection, we propose a novel algorithm based on Spectral Residual (SR) and Convolutional Neural Network (CNN). Our work is the first attempt to borrow the SR model from visual saliency detection domain to time-series anomaly detection. Moreover, we innovatively combine SR and CNN together to improve the performance of SR model. Our approach achieves superior experimental results compared with state-of-the-art baselines on both public datasets and Microsoft production data.