 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Open-source LLMs Enhance Data Synthesis for Toxic Detection?: An Experimental Study
Dec 03, 2024
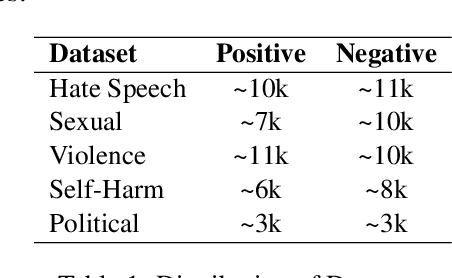


Effective toxic content detection relies heavily on high-quality and diverse data, which serves as the foundation for robust content moderation models. This study explores the potential of open-source LLMs for harmful data synthesis, utilizing prompt engineering and fine-tuning techniques to enhance data quality and diversity. In a two-stage evaluation, we first examine the capabilities of six open-source LLMs in generating harmful data across multiple datasets using prompt engineering. In the second stage, we fine-tune these models to improve data generation while addressing challenges such as hallucination, data duplication, and overfitting. Our findings reveal that Mistral excels in generating high-quality and diverse harmful data with minimal hallucination. Furthermore, fine-tuning enhances data quality, offering scalable and cost-effective solutions for augmenting datasets for specific toxic content detection tasks. These results emphasize the significance of data synthesis in building robust, standalone detection models and highlight the potential of open-source LLMs to advance smaller downstream content moderation systems. We implemented this approach in real-world industrial settings, demonstrating the feasibility and efficiency of fine-tuned open-source LLMs for harmful data synthesis.
Can Open-source LLMs Enhance Data Augmentation for Toxic Detection?: An Experimental Study
Nov 18, 2024High-quality, diverse harmful data is essential to addressing real-time applications in content moderation. Current state-of-the-art approaches to toxic content detection using GPT series models are costly and lack explainability. This paper investigates the use of prompt engineering and fine-tuning techniques on open-source LLMs to enhance harmful data augmentation specifically for toxic content detection. We conduct a two-stage empirical study, with stage 1 evaluating six open-source LLMs across multiple datasets using only prompt engineering and stage 2 focusing on fine-tuning. Our findings indicate that Mistral can excel in generating harmful data with minimal hallucination. While fine-tuning these models improves data quality and diversity, challenges such as data duplication and overfitting persist. Our experimental results highlight scalable, cost-effective strategies for enhancing toxic content detection systems. These findings not only demonstrate the potential of open-source LLMs in creating robust content moderation tools. The application of this method in real industrial scenarios further proves the feasibility and efficiency of the fine-tuned open-source LLMs for data augmentation. We hope our study will aid in understanding the capabilities and limitations of current models in toxic content detection and drive further advancements in this field.
Protecting the Future: Neonatal Seizure Detection with Spatial-Temporal Modeling
Jul 02, 2023A timely detection of seizures for newborn infants with electroencephalogram (EEG) has been a common yet life-saving practice in the Neonatal Intensive Care Unit (NICU). However, it requires great human efforts for real-time monitoring, which calls for automated solutions to neonatal seizure detection. Moreover, the current automated methods focusing on adult epilepsy monitoring often fail due to (i) dynamic seizure onset location in human brains; (ii) different montages on neonates and (iii) huge distribution shift among different subjects. In this paper, we propose a deep learning framework, namely STATENet, to address the exclusive challenges with exquisite designs at the temporal, spatial and model levels. The experiments over the real-world large-scale neonatal EEG dataset illustrate that our framework achieves significantly better seizure detection performance.
Learning Timestamp-Level Representations for Time Series with Hierarchical Contrastive Loss
Jun 19, 2021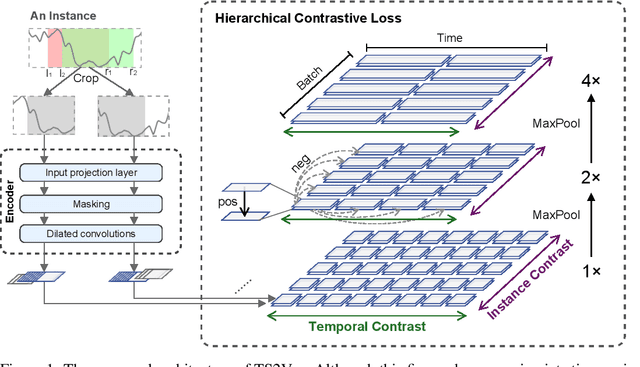

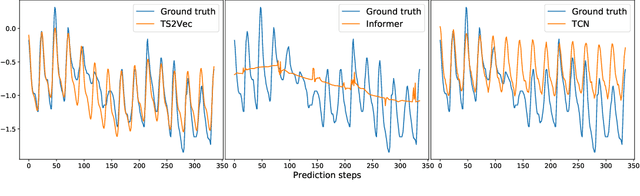
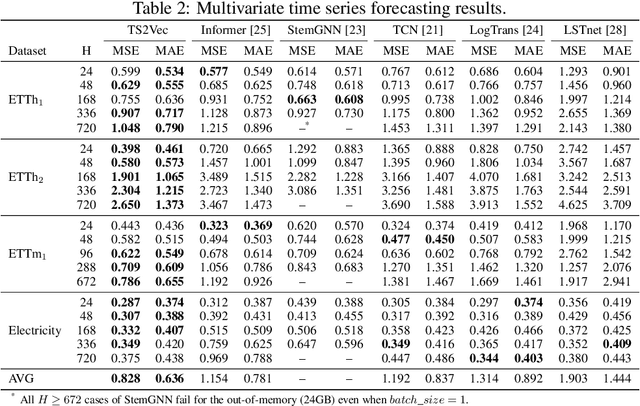
This paper presents TS2Vec, a universal framework for learning timestamp-level representations of time series. Unlike existing methods, TS2Vec performs timestamp-wise discrimination, which learns a contextual representation vector directly for each timestamp. We find that the learned representations have superior predictive ability. A linear regression trained on top of the learned representations outperforms previous SOTAs for supervised time series forecasting. Also, the instance-level representations can be simply obtained by applying a max pooling layer on top of learned representations of all timestamps. We conduct extensive experiments on time series classification tasks to evaluate the quality of instance-level representations. As a result, TS2Vec achieves significant improvement compared with existing SOTAs of unsupervised time series representation on 125 UCR datasets and 29 UEA datasets. The source code is publicly available at https://github.com/yuezhihan/ts2vec.
Spectral Temporal Graph Neural Network for Multivariate Time-series Forecasting
Mar 13, 2021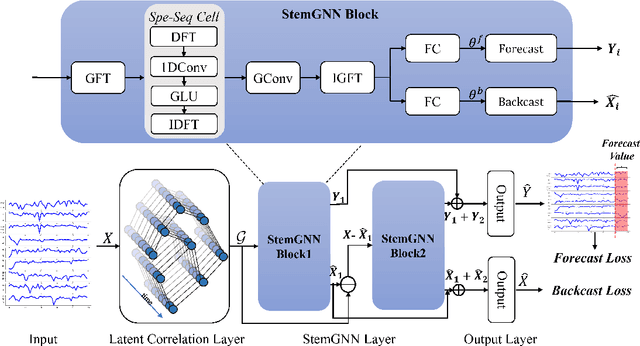

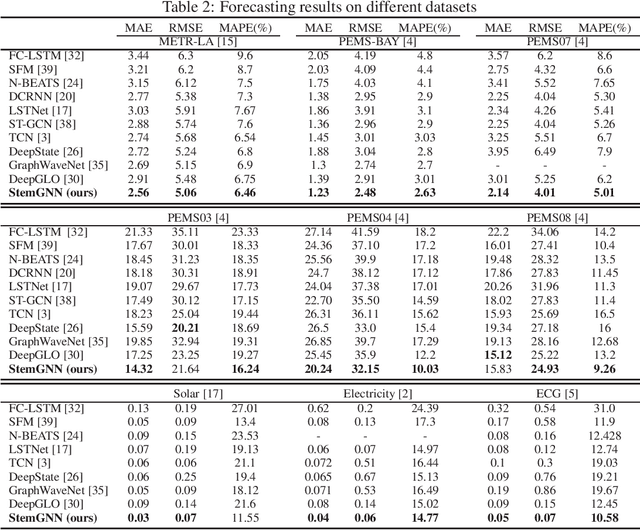
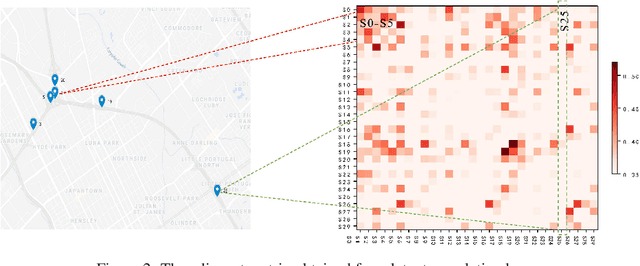
Multivariate time-series forecasting plays a crucial role in many real-world applications. It is a challenging problem as one needs to consider both intra-series temporal correlations and inter-series correlations simultaneously. Recently, there have been multiple works trying to capture both correlations, but most, if not all of them only capture temporal correlations in the time domain and resort to pre-defined priors as inter-series relationships. In this paper, we propose Spectral Temporal Graph Neural Network (StemGNN) to further improve the accuracy of multivariate time-series forecasting. StemGNN captures inter-series correlations and temporal dependencies \textit{jointly} in the \textit{spectral domain}. It combines Graph Fourier Transform (GFT) which models inter-series correlations and Discrete Fourier Transform (DFT) which models temporal dependencies in an end-to-end framework. After passing through GFT and DFT, the spectral representations hold clear patterns and can be predicted effectively by convolution and sequential learning modules. Moreover, StemGNN learns inter-series correlations automatically from the data without using pre-defined priors. We conduct extensive experiments on ten real-world datasets to demonstrate the effectiveness of StemGNN. Code is available at https://github.com/microsoft/StemGNN/
Multivariate Time-series Anomaly Detection via Graph Attention Network
Sep 04, 2020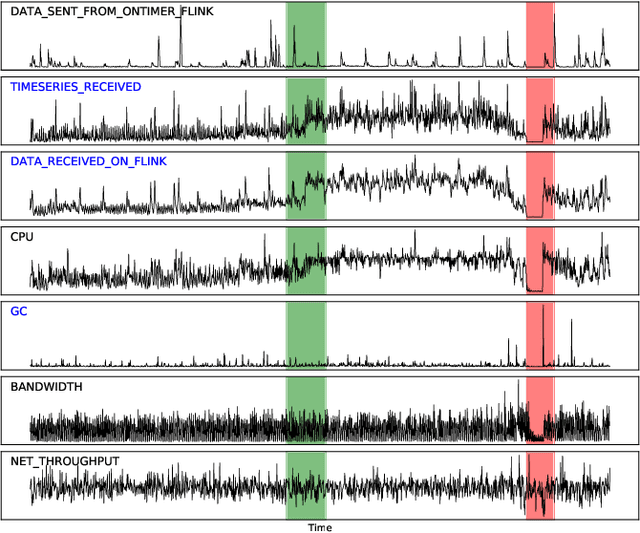
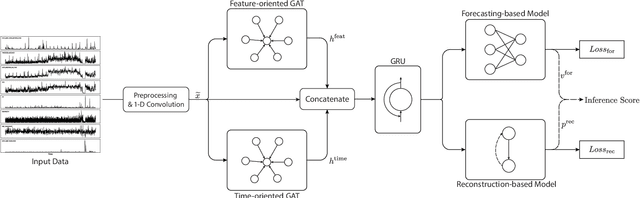
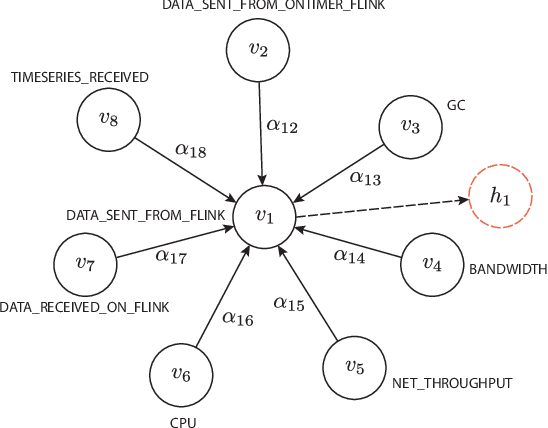
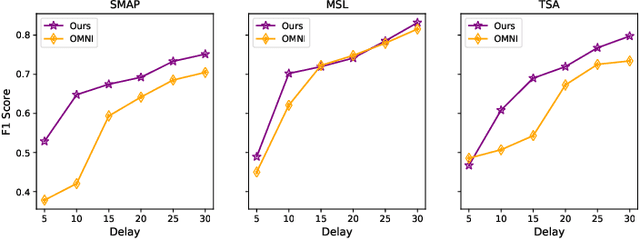
Anomaly detection on multivariate time-series is of great importance in both data mining research and industrial applications. Recent approaches have achieved significant progress in this topic, but there is remaining limitations. One major limitation is that they do not capture the relationships between different time-series explicitly, resulting in inevitable false alarms. In this paper, we propose a novel self-supervised framework for multivariate time-series anomaly detection to address this issue. Our framework considers each univariate time-series as an individual feature and includes two graph attention layers in parallel to learn the complex dependencies of multivariate time-series in both temporal and feature dimensions. In addition, our approach jointly optimizes a forecasting-based model and are construction-based model, obtaining better time-series representations through a combination of single-timestamp prediction and reconstruction of the entire time-series. We demonstrate the efficacy of our model through extensive experiments. The proposed method outperforms other state-of-the-art models on three real-world datasets. Further analysis shows that our method has good interpretability and is useful for anomaly diagnosis.
Automated Model Selection for Time-Series Anomaly Detection
Aug 25, 2020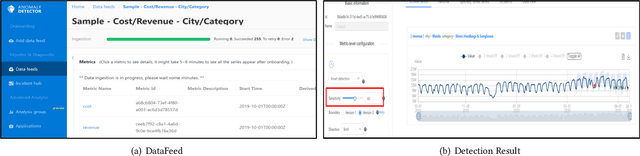

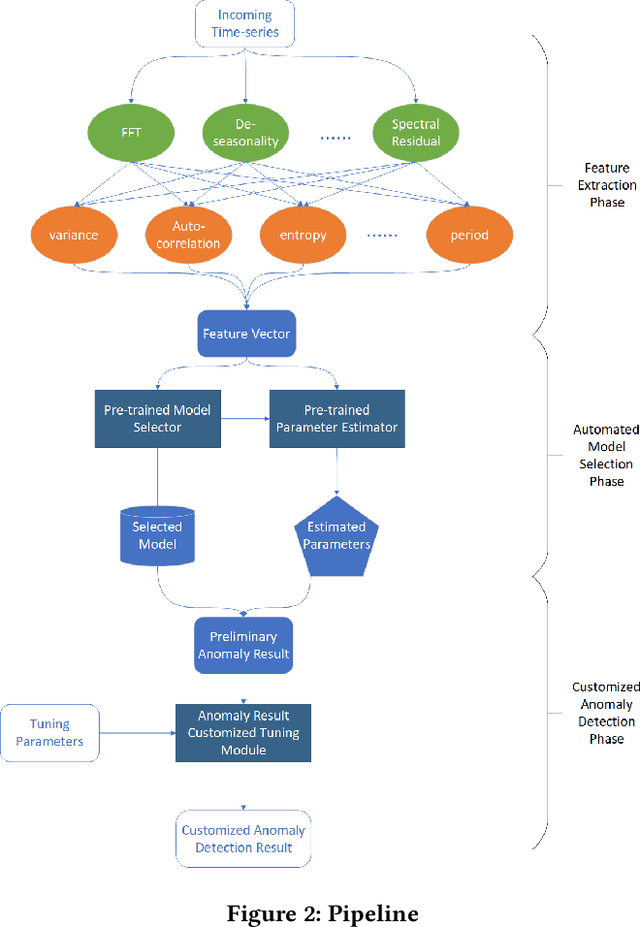

Time-series anomaly detection is a popular topic in both academia and industrial fields. Many companies need to monitor thousands of temporal signals for their applications and services and require instant feedback and alerts for potential incidents in time. The task is challenging because of the complex characteristics of time-series, which are messy, stochastic, and often without proper labels. This prohibits training supervised models because of lack of labels and a single model hardly fits different time series. In this paper, we propose a solution to address these issues. We present an automated model selection framework to automatically find the most suitable detection model with proper parameters for the incoming data. The model selection layer is extensible as it can be updated without too much effort when a new detector is available to the service. Finally, we incorporate a customized tuning algorithm to flexibly filter anomalies to meet customers' criteria. Experiments on real-world datasets show the effectiveness of our solution.
Human Annotations Improve GAN Performances
Nov 15, 2019

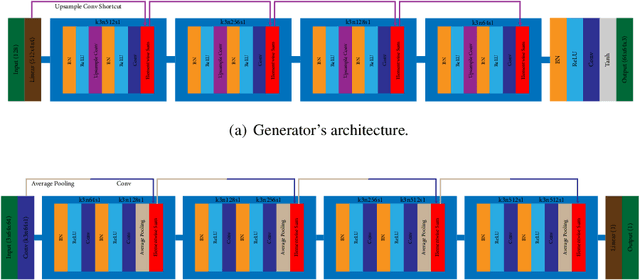
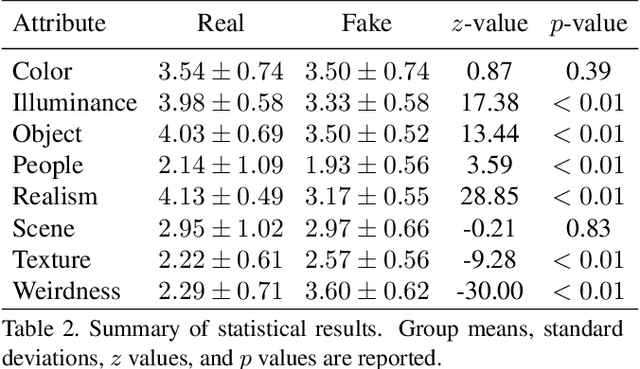
Generative Adversarial Networks (GANs) have shown great success in many applications. In this work, we present a novel method that leverages human annotations to improve the quality of generated images. Unlike previous paradigms that directly ask annotators to distinguish between real and fake data in a straightforward way, we propose and annotate a set of carefully designed attributes that encode important image information at various levels, to understand the differences between fake and real images. Specifically, we have collected an annotated dataset that contains 600 fake images and 400 real images. These images are evaluated by 10 workers from the Amazon Mechanical Turk (AMT) based on eight carefully defined attributes. Statistical analyses have revealed different distributions of the proposed attributes between real and fake images. These attributes are shown to be useful in discriminating fake images from real ones, and deep neural networks are developed to automatically predict the attributes. We further utilize the information by integrating the attributes into GANs to generate better images. Experimental results evaluated by multiple metrics show performance improvement of the proposed model.