 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Information-Decomposition Analysis of Large Vision-Language Models
Mar 31, 2026Large vision-language models (LVLMs) achieve impressive performance, yet their internal decision-making processes remain opaque, making it difficult to determine if the success stems from true multimodal fusion or from reliance on unimodal priors. To address this attribution gap, we introduce a novel framework using partial information decomposition (PID) to quantitatively measure the "information spectrum" of LVLMs -- decomposing a model's decision-relevant information into redundant, unique, and synergistic components. By adapting a scalable estimator to modern LVLM outputs, our model-agnostic pipeline profiles 26 LVLMs on four datasets across three dimensions -- breadth (cross-model & cross-task), depth (layer-wise information dynamics), and time (learning dynamics across training). Our analysis reveals two key results: (i) two task regimes (synergy-driven vs. knowledge-driven) and (ii) two stable, contrasting family-level strategies (fusion-centric vs. language-centric). We also uncover a consistent three-phase pattern in layer-wise processing and identify visual instruction tuning as the key stage where fusion is learned. Together, these contributions provide a quantitative lens beyond accuracy-only evaluation and offer insights for analyzing and designing the next generation of LVLMs. Code and data are available at https://github.com/RiiShin/pid-lvlm-analysis .
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Mar 25, 2026Self-distillation has emerged as an effective post-training paradigm for LLMs, often improving performance while shortening reasoning traces. However, in mathematical reasoning, we find that it can reduce response length while degrading performance. We trace this degradation to the suppression of epistemic verbalization - the model's expression of uncertainty during reasoning. Through controlled experiments varying conditioning context richness and task coverage, we show that conditioning the teacher on rich information suppresses uncertainty expression, enabling rapid in-domain optimization with limited task coverage but harming OOD performance, where unseen problems benefit from expressing uncertainty and adjusting accordingly. Across Qwen3-8B, DeepSeek-Distill-Qwen-7B, and Olmo3-7B-Instruct, we observe performance drops of up to 40%. Our findings highlight that exposing appropriate levels of uncertainty is crucial for robust reasoning and underscore the importance of optimizing reasoning behavior beyond merely reinforcing correct answer traces.
SortedRL: Accelerating RL Training for LLMs through Online Length-Aware Scheduling
Mar 24, 2026Scaling reinforcement learning (RL) has shown strong promise for enhancing the reasoning abilities of large language models (LLMs), particularly in tasks requiring long chain-of-thought generation. However, RL training efficiency is often bottlenecked by the rollout phase, which can account for up to 70% of total training time when generating long trajectories (e.g., 16k tokens), due to slow autoregressive generation and synchronization overhead between rollout and policy updates. We propose SortedRL, an online length-aware scheduling strategy designed to address this bottleneck by improving rollout efficiency and maintaining training stability. SortedRL reorders rollout samples based on output lengths, prioritizing short samples forming groups for early updates. This enables large rollout batches, flexible update batches, and near on-policy micro-curriculum construction simultaneously. To further accelerate the pipeline, SortedRL incorporates a mechanism to control the degree of off-policy training through a cache-based mechanism, and is supported by a dedicated RL infrastructure that manages rollout and update via a stateful controller and rollout buffer. Experiments using LLaMA-3.1-8B and Qwen-2.5-32B on diverse tasks, including logical puzzles, and math challenges like AIME 24, Math 500, and Minerval, show that SortedRL reduces RL training bubble ratios by over 50%, while attaining 3.9% to 18.4% superior performance over baseline given same amount of data.
Understanding Reasoning in LLMs through Strategic Information Allocation under Uncertainty
Mar 16, 2026LLMs often exhibit Aha moments during reasoning, such as apparent self-correction following tokens like "Wait," yet their underlying mechanisms remain unclear. We introduce an information-theoretic framework that decomposes reasoning into procedural information and epistemic verbalization - the explicit externalization of uncertainty that supports downstream control actions. We show that purely procedural reasoning can become informationally stagnant, whereas epistemic verbalization enables continued information acquisition and is critical for achieving information sufficiency. Empirical results demonstrate that strong reasoning performance is driven by uncertainty externalization rather than specific surface tokens. Our framework unifies prior findings on Aha moments and post-training experiments, and offers insights for future reasoning model design.
Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization
Feb 26, 2026Exploration remains the key bottleneck for large language model agents trained with reinforcement learning. While prior methods exploit pretrained knowledge, they fail in environments requiring the discovery of novel states. We propose Exploratory Memory-Augmented On- and Off-Policy Optimization (EMPO$^2$), a hybrid RL framework that leverages memory for exploration and combines on- and off-policy updates to make LLMs perform well with memory while also ensuring robustness without it. On ScienceWorld and WebShop, EMPO$^2$ achieves 128.6% and 11.3% improvements over GRPO, respectively. Moreover, in out-of-distribution tests, EMPO$^2$ demonstrates superior adaptability to new tasks, requiring only a few trials with memory and no parameter updates. These results highlight EMPO$^2$ as a promising framework for building more exploratory and generalizable LLM-based agents.
pMoE: Prompting Diverse Experts Together Wins More in Visual Adaptation
Feb 26, 2026Parameter-efficient fine-tuning has demonstrated promising results across various visual adaptation tasks, such as classification and segmentation. Typically, prompt tuning techniques have harnessed knowledge from a single pre-trained model, whether from a general or a specialized medical domain. However, this approach typically overlooks the potential synergies that could arise from integrating diverse domain knowledge within the same tuning process. In this work, we propose a novel Mixture-of-Experts prompt tuning method called pMoE, which leverages the strengths of multiple expert domains through expert-specialized prompt tokens and the learnable dispatcher, effectively combining their expertise in a unified model framework. Our pMoE introduces expert-specific prompt tokens and utilizes a dynamic token dispatching mechanism at various prompt layers to optimize the contribution of each domain expert during the adaptation phase. By incorporating both domain knowledge from diverse experts, the proposed pMoE significantly enhances the model's versatility and applicability to a broad spectrum of tasks. We conduct extensive experiments across 47 adaptation tasks, including both classification and segmentation in general and medical domains. The results demonstrate that our pMoE not only achieves superior performance with a large margin of improvements but also offers an optimal trade-off between computational efficiency and adaptation effectiveness compared to existing methods.
$ΔL$ Normalization: Rethink Loss Aggregation in RLVR
Sep 09, 2025We propose $\Delta L$ Normalization, a simple yet effective loss aggregation method tailored to the characteristic of dynamic generation lengths in Reinforcement Learning with Verifiable Rewards (RLVR). Recently, RLVR has demonstrated strong potential in improving the reasoning capabilities of large language models (LLMs), but a major challenge lies in the large variability of response lengths during training, which leads to high gradient variance and unstable optimization. Although previous methods such as GRPO, DAPO, and Dr. GRPO introduce different loss normalization terms to address this issue, they either produce biased estimates or still suffer from high gradient variance. By analyzing the effect of varying lengths on policy loss both theoretically and empirically, we reformulate the problem as finding a minimum-variance unbiased estimator. Our proposed $\Delta L$ Normalization not only provides an unbiased estimate of the true policy loss but also minimizes gradient variance in theory. Extensive experiments show that it consistently achieves superior results across different model sizes, maximum lengths, and tasks. Our code will be made public at https://github.com/zerolllin/Delta-L-Normalization.
Do Not Let Low-Probability Tokens Over-Dominate in RL for LLMs
May 19, 2025Reinforcement learning (RL) has become a cornerstone for enhancing the reasoning capabilities of large language models (LLMs), with recent innovations such as Group Relative Policy Optimization (GRPO) demonstrating exceptional effectiveness. In this study, we identify a critical yet underexplored issue in RL training: low-probability tokens disproportionately influence model updates due to their large gradient magnitudes. This dominance hinders the effective learning of high-probability tokens, whose gradients are essential for LLMs' performance but are substantially suppressed. To mitigate this interference, we propose two novel methods: Advantage Reweighting and Low-Probability Token Isolation (Lopti), both of which effectively attenuate gradients from low-probability tokens while emphasizing parameter updates driven by high-probability tokens. Our approaches promote balanced updates across tokens with varying probabilities, thereby enhancing the efficiency of RL training. Experimental results demonstrate that they substantially improve the performance of GRPO-trained LLMs, achieving up to a 46.2% improvement in K&K Logic Puzzle reasoning tasks. Our implementation is available at https://github.com/zhyang2226/AR-Lopti.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025



Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
MMInference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention
Apr 22, 2025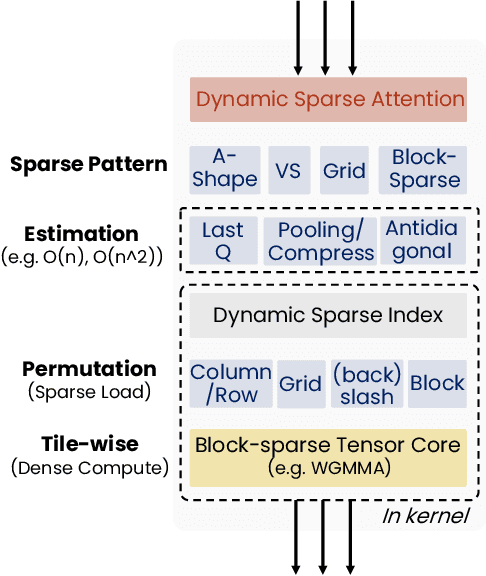
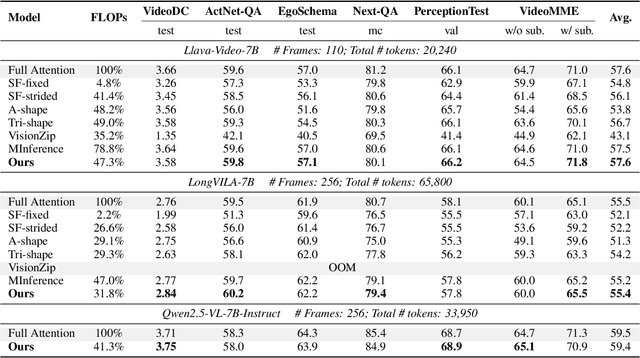
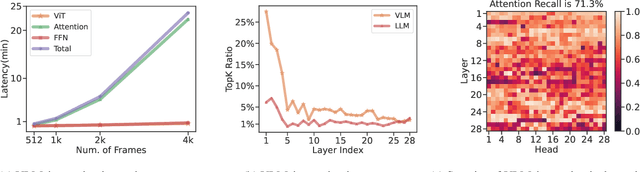

The integration of long-context capabilities with visual understanding unlocks unprecedented potential for Vision Language Models (VLMs). However, the quadratic attention complexity during the pre-filling phase remains a significant obstacle to real-world deployment. To overcome this limitation, we introduce MMInference (Multimodality Million tokens Inference), a dynamic sparse attention method that accelerates the prefilling stage for long-context multi-modal inputs. First, our analysis reveals that the temporal and spatial locality of video input leads to a unique sparse pattern, the Grid pattern. Simultaneously, VLMs exhibit markedly different sparse distributions across different modalities. We introduce a permutation-based method to leverage the unique Grid pattern and handle modality boundary issues. By offline search the optimal sparse patterns for each head, MMInference constructs the sparse distribution dynamically based on the input. We also provide optimized GPU kernels for efficient sparse computations. Notably, MMInference integrates seamlessly into existing VLM pipelines without any model modifications or fine-tuning. Experiments on multi-modal benchmarks-including Video QA, Captioning, VisionNIAH, and Mixed-Modality NIAH-with state-of-the-art long-context VLMs (LongVila, LlavaVideo, VideoChat-Flash, Qwen2.5-VL) show that MMInference accelerates the pre-filling stage by up to 8.3x at 1M tokens while maintaining accuracy. Our code is available at https://aka.ms/MMInference.