 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Harness Engineering: Observability-Driven Automatic Evolution of Coding-Agent Harnesses
Apr 28, 2026Harnesses have become a central determinant of coding-agent performance, shaping how models interact with repositories, tools, and execution environments. Yet automating harness engineering is hard: a heterogeneous action space, sparse and noisy evaluation signal, multi-million-token trajectories, and edits whose effect is hard to attribute to the next round's outcomes. We introduce Agentic Harness Engineering (AHE), a framework that automates harness-level evolution by instrumenting the three stages of any engineering loop (component editing, trajectory inspection, and decision making) with matched observability pillars: (1) component observability gives every editable harness component a file-level representation so the action space is explicit and revertible; (2) experience observability distills millions of raw trajectory tokens into a layered, drill-down evidence corpus that an evolving agent can actually consume; and (3) decision observability pairs every edit with a self-declared prediction, later verified against the next round's task-level outcomes. Together, these pillars turn every edit into a falsifiable contract, so harness evolution proceeds autonomously without collapsing into trial-and-error. Empirically, ten AHE iterations lift pass@1 on Terminal-Bench 2 from 69.7% to 77.0%, surpassing the human-designed harness Codex-CLI (71.9%) and the self-evolving baselines ACE and TF-GRPO. The frozen harness transfers without re-evolution: on SWE-bench-verified it tops aggregate success at 12% fewer tokens than the seed, and on Terminal-Bench 2 it yields +5.1 to +10.1pp cross-family gains across three alternate model families, indicating the evolved components encode general engineering experience rather than benchmark-specific tuning. These results position observability-driven evolution as a practical pathway to keep coding-agent harnesses continually improving.
EVPO: Explained Variance Policy Optimization for Adaptive Critic Utilization in LLM Post-Training
Apr 21, 2026Reinforcement learning (RL) for LLM post-training faces a fundamental design choice: whether to use a learned critic as a baseline for policy optimization. Classical theory favors critic-based methods such as PPO for variance reduction, yet critic-free alternatives like GRPO have gained widespread adoption due to their simplicity and competitive performance. We show that in sparse-reward settings, a learned critic can inject estimation noise that exceeds the state signal it captures, increasing rather than reducing advantage variance. By casting baseline selection as a Kalman filtering problem, we unify PPO and GRPO as two extremes of the Kalman gain and prove that explained variance (EV), computable from a single training batch, identifies the exact boundary: positive EV indicates the critic reduces variance, while zero or negative EV signals that it inflates variance. Building on this insight, we propose Explained Variance Policy Optimization (EVPO), which monitors batch-level EV at each training step and adaptively switches between critic-based and batch-mean advantage estimation, provably achieving no greater variance than the better of the two at every step. Across four tasks spanning classical control, agentic interaction, and mathematical reasoning, EVPO consistently outperforms both PPO and GRPO regardless of which fixed baseline is stronger on a given task. Further analysis confirms that the adaptive gating tracks critic maturation over training and that the theoretically derived zero threshold is empirically optimal.
MM-Doc-R1: Training Agents for Long Document Visual Question Answering through Multi-turn Reinforcement Learning
Apr 15, 2026Conventional Retrieval-Augmented Generation (RAG) systems often struggle with complex multi-hop queries over long documents due to their single-pass retrieval. We introduce MM-Doc-R1, a novel framework that employs an agentic, vision-aware workflow to address long document visual question answering through iterative information discovery and synthesis. To incentivize the information seeking capabilities of our agents, we propose Similarity-based Policy Optimization (SPO), addressing baseline estimation bias in existing multi-turn reinforcement learning (RL) algorithms like GRPO. Our core insight is that in multi-turn RL, the more semantically similar two trajectories are, the more accurate their shared baseline estimation becomes. Leveraging this, SPO calculates a more precise baseline by similarity-weighted averaging of rewards across multiple trajectories, unlike GRPO which inappropriately applies the initial state's baseline to all intermediate states. This provides a more stable and accurate learning signal for our agents, leading to superior training performance that surpasses GRPO. Our experiments on the MMLongbench-Doc benchmark show that MM-Doc-R1 outperforms previous baselines by 10.4%. Furthermore, SPO demonstrates superior performance over GRPO, boosting results by 5.0% with Qwen3-8B and 6.1% with Qwen3-4B. These results highlight the effectiveness of our integrated framework and novel training algorithm in advancing the state-of-the-art for complex, long-document visual question answering.
Building Self-Evolving Agents via Experience-Driven Lifelong Learning: A Framework and Benchmark
Aug 26, 2025As AI advances toward general intelligence, the focus is shifting from systems optimized for static tasks to creating open-ended agents that learn continuously. In this paper, we introduce Experience-driven Lifelong Learning (ELL), a framework for building self-evolving agents capable of continuous growth through real-world interaction. The framework is built on four core principles: (1) Experience Exploration: Agents learn through continuous, self-motivated interaction with dynamic environments, navigating interdependent tasks and generating rich experiential trajectories. (2) Long-term Memory: Agents preserve and structure historical knowledge, including personal experiences, domain expertise, and commonsense reasoning, into a persistent memory system. (3) Skill Learning: Agents autonomously improve by abstracting recurring patterns from experience into reusable skills, which are actively refined and validated for application in new tasks. (4) Knowledge Internalization: Agents internalize explicit and discrete experiences into implicit and intuitive capabilities as "second nature". We also introduce StuLife, a benchmark dataset for ELL that simulates a student's holistic college journey, from enrollment to academic and personal development, across three core phases and ten detailed sub-scenarios. StuLife is designed around three key paradigm shifts: From Passive to Proactive, From Context to Memory, and From Imitation to Learning. In this dynamic environment, agents must acquire and distill practical skills and maintain persistent memory to make decisions based on evolving state variables. StuLife provides a comprehensive platform for evaluating lifelong learning capabilities, including memory retention, skill transfer, and self-motivated behavior. Beyond evaluating SOTA LLMs on the StuLife benchmark, we also explore the role of context engineering in advancing AGI.
Efficient Serving of LLM Applications with Probabilistic Demand Modeling
Jun 17, 2025Applications based on Large Language Models (LLMs) contains a series of tasks to address real-world problems with boosted capability, which have dynamic demand volumes on diverse backends. Existing serving systems treat the resource demands of LLM applications as a blackbox, compromising end-to-end efficiency due to improper queuing order and backend warm up latency. We find that the resource demands of LLM applications can be modeled in a general and accurate manner with Probabilistic Demand Graph (PDGraph). We then propose Hermes, which leverages PDGraph for efficient serving of LLM applications. Confronting probabilistic demand description, Hermes applies the Gittins policy to determine the scheduling order that can minimize the average application completion time. It also uses the PDGraph model to help prewarm cold backends at proper moments. Experiments with diverse LLM applications confirm that Hermes can effectively improve the application serving efficiency, reducing the average completion time by over 70% and the P95 completion time by over 80%.
Efficient Unified Caching for Accelerating Heterogeneous AI Workloads
Jun 14, 2025Modern AI clusters, which host diverse workloads like data pre-processing, training and inference, often store the large-volume data in cloud storage and employ caching frameworks to facilitate remote data access. To avoid code-intrusion complexity and minimize cache space wastage, it is desirable to maintain a unified cache shared by all the workloads. However, existing cache management strategies, designed for specific workloads, struggle to handle the heterogeneous AI workloads in a cluster -- which usually exhibit heterogeneous access patterns and item storage granularities. In this paper, we propose IGTCache, a unified, high-efficacy cache for modern AI clusters. IGTCache leverages a hierarchical access abstraction, AccessStreamTree, to organize the recent data accesses in a tree structure, facilitating access pattern detection at various granularities. Using this abstraction, IGTCache applies hypothesis testing to categorize data access patterns as sequential, random, or skewed. Based on these detected access patterns and granularities, IGTCache tailors optimal cache management strategies including prefetching, eviction, and space allocation accordingly. Experimental results show that IGTCache increases the cache hit ratio by 55.6% over state-of-the-art caching frameworks, reducing the overall job completion time by 52.2%.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025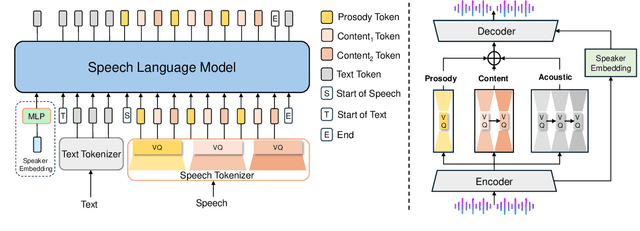
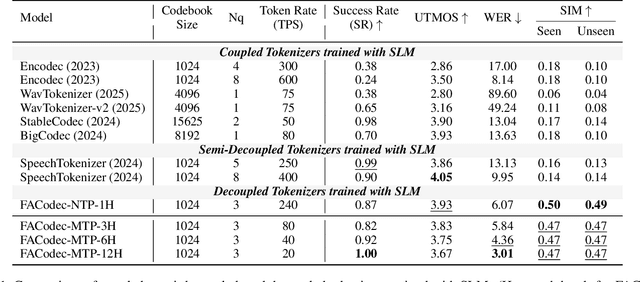
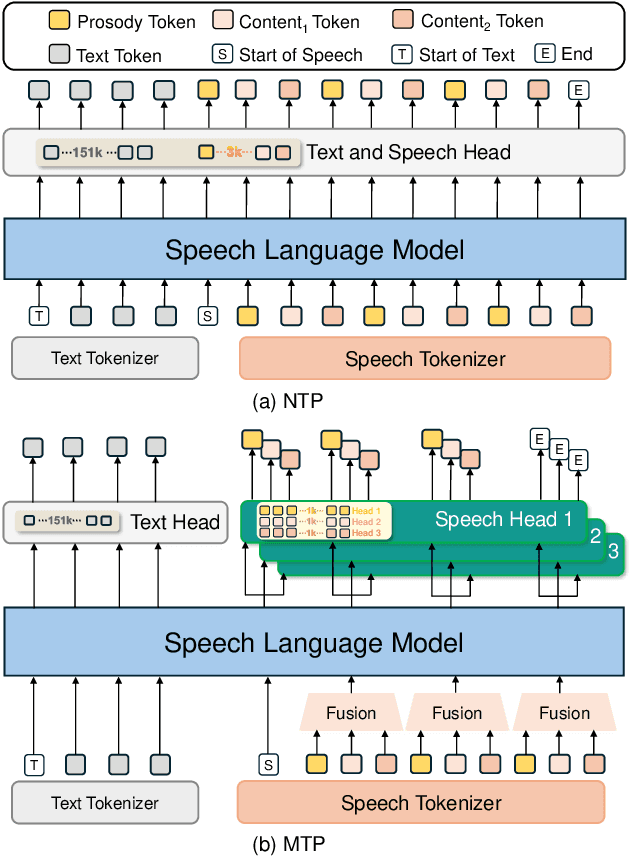
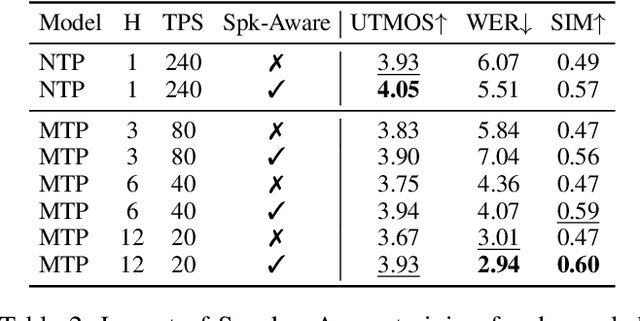
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Real-Time Neural-Enhancement for Online Cloud Gaming
Jan 12, 2025



Online Cloud gaming demands real-time, high-quality video transmission across variable wide-area networks (WANs). Neural-enhanced video transmission algorithms employing super-resolution (SR) for video quality enhancement have effectively challenged WAN environments. However, these SR-based methods require intensive fine-tuning for the whole video, making it infeasible in diverse online cloud gaming. To address this, we introduce River, a cloud gaming delivery framework designed based on the observation that video segment features in cloud gaming are typically repetitive and redundant. This permits a significant opportunity to reuse fine-tuned SR models, reducing the fine-tuning latency of minutes to query latency of milliseconds. To enable the idea, we design a practical system that addresses several challenges, such as model organization, online model scheduler, and transfer strategy. River first builds a content-aware encoder that fine-tunes SR models for diverse video segments and stores them in a lookup table. When delivering cloud gaming video streams online, River checks the video features and retrieves the most relevant SR models to enhance the frame quality. Meanwhile, if no existing SR model performs well enough for some video segments, River will further fine-tune new models and update the lookup table. Finally, to avoid the overhead of streaming model weight to the clients, River designs a prefetching strategy that predicts the models with the highest possibility of being retrieved. Our evaluation based on real video game streaming demonstrates River can reduce redundant training overhead by 44% and improve the Peak-Signal-to-Noise-Ratio by 1.81dB compared to the SOTA solutions. Practical deployment shows River meets real-time requirements, achieving approximately 720p 20fps on mobile devices.
RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval
Sep 16, 2024



Transformer-based large Language Models (LLMs) become increasingly important in various domains. However, the quadratic time complexity of attention operation poses a significant challenge for scaling to longer contexts due to the extremely high inference latency and GPU memory consumption for caching key-value (KV) vectors. This paper proposes RetrievalAttention, a training-free approach to accelerate attention computation. To leverage the dynamic sparse property of attention, RetrievalAttention builds approximate nearest neighbor search (ANNS) indexes upon KV vectors in CPU memory and retrieves the most relevant ones via vector search during generation. Due to the out-of-distribution (OOD) between query vectors and key vectors, off-the-shelf ANNS indexes still need to scan O(N) (usually 30% of all keys) data for accurate retrieval, which fails to exploit the high sparsity. RetrievalAttention first identifies the OOD challenge of ANNS-based attention, and addresses it via an attention-aware vector search algorithm that can adapt to queries and only access 1--3% of data, thus achieving a sub-linear time complexity. RetrievalAttention greatly reduces the inference cost of long-context LLM with much lower GPU memory requirements while maintaining the model accuracy. Especially, RetrievalAttention only needs 16GB GPU memory for serving 128K tokens in LLMs with 8B parameters, which is capable of generating one token in 0.188 seconds on a single NVIDIA RTX4090 (24GB).
MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention
Jul 02, 2024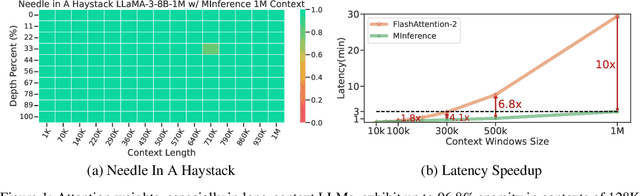

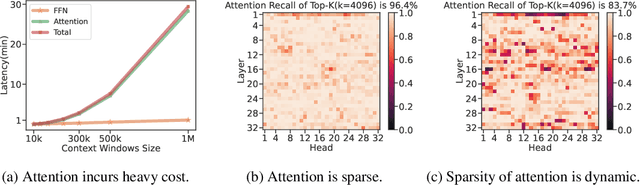
The computational challenges of Large Language Model (LLM) inference remain a significant barrier to their widespread deployment, especially as prompt lengths continue to increase. Due to the quadratic complexity of the attention computation, it takes 30 minutes for an 8B LLM to process a prompt of 1M tokens (i.e., the pre-filling stage) on a single A100 GPU. Existing methods for speeding up prefilling often fail to maintain acceptable accuracy or efficiency when applied to long-context LLMs. To address this gap, we introduce MInference (Milliontokens Inference), a sparse calculation method designed to accelerate pre-filling of long-sequence processing. Specifically, we identify three unique patterns in long-context attention matrices-the A-shape, Vertical-Slash, and Block-Sparsethat can be leveraged for efficient sparse computation on GPUs. We determine the optimal pattern for each attention head offline and dynamically build sparse indices based on the assigned pattern during inference. With the pattern and sparse indices, we perform efficient sparse attention calculations via our optimized GPU kernels to significantly reduce the latency in the pre-filling stage of long-context LLMs. Our proposed technique can be directly applied to existing LLMs without any modifications to the pre-training setup or additional fine-tuning. By evaluating on a wide range of downstream tasks, including InfiniteBench, RULER, PG-19, and Needle In A Haystack, and models including LLaMA-3-1M, GLM4-1M, Yi-200K, Phi-3-128K, and Qwen2-128K, we demonstrate that MInference effectively reduces inference latency by up to 10x for pre-filling on an A100, while maintaining accuracy. Our code is available at https://aka.ms/MInference.