 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamMind: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition
Mar 08, 2025With the rise of real-world human-AI interaction applications, such as AI assistants, the need for Streaming Video Dialogue is critical. To address this need, we introduce \sys, a video LLM framework that achieves ultra-FPS streaming video processing (100 fps on a single A100) and enables proactive, always-on responses in real time, without explicit user intervention. To solve the key challenge of the contradiction between linear video streaming speed and quadratic transformer computation cost, we propose a novel perception-cognition interleaving paradigm named ''event-gated LLM invocation'', in contrast to the existing per-time-step LLM invocation. By introducing a Cognition Gate network between the video encoder and the LLM, LLM is only invoked when relevant events occur. To realize the event feature extraction with constant cost, we propose Event-Preserving Feature Extractor (EPFE) based on state-space method, generating a single perception token for spatiotemporal features. These techniques enable the video LLM with full-FPS perception and real-time cognition response. Experiments on Ego4D and SoccerNet streaming tasks, as well as standard offline benchmarks, demonstrate state-of-the-art performance in both model capability and real-time efficiency, paving the way for ultra-high-FPS applications, such as Game AI Copilot and interactive media.
Making Every Frame Matter: Continuous Video Understanding for Large Models via Adaptive State Modeling
Oct 19, 2024
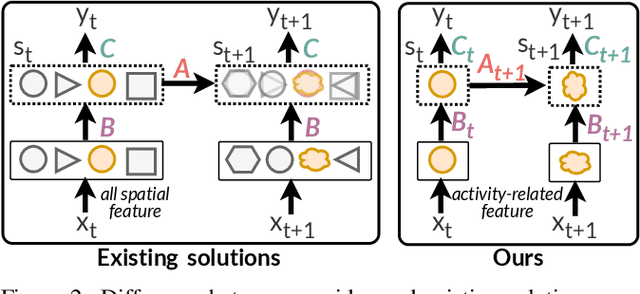
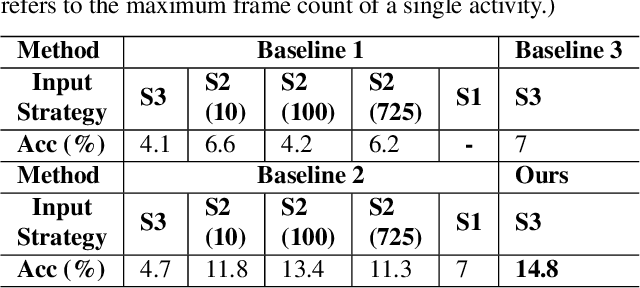
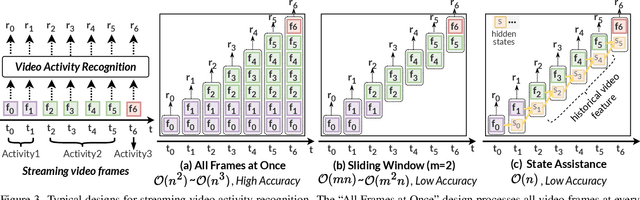
Video understanding has become increasingly important with the rise of multi-modality applications. Understanding continuous video poses considerable challenges due to the fast expansion of streaming video, which contains multi-scale and untrimmed events. We introduce a novel system, C-VUE, to overcome these issues through adaptive state modeling. C-VUE has three key designs. The first is a long-range history modeling technique that uses a video-aware approach to retain historical video information. The second is a spatial redundancy reduction technique, which enhances the efficiency of history modeling based on temporal relations. The third is a parallel training structure that incorporates the frame-weighted loss to understand multi-scale events in long videos. Our C-VUE offers high accuracy and efficiency. It runs at speeds >30 FPS on typical edge devices and outperforms all baselines in accuracy. Moreover, applying C-VUE to a video foundation model as a video encoder in our case study resulted in a 0.46-point enhancement (on a 5-point scale) on the in-distribution dataset, and an improvement ranging from 1.19\% to 4\% on zero-shot datasets.
Online Video Streaming Super-Resolution with Adaptive Look-Up Table Fusion
Mar 01, 2023This paper focuses on Super-resolution for online video streaming data. Applying existing super-resolution methods to video streaming data is non-trivial for two reasons. First, to support application with constant interactions, video streaming has a high requirement for latency that most existing methods are less applicable, especially on low-end devices. Second, existing video streaming protocols (e.g., WebRTC) dynamically adapt the video quality to the network condition, thus video streaming in the wild varies greatly under different network bandwidths, which leads to diverse and dynamic degradations. To tackle the above two challenges, we proposed a novel video super-resolution method for online video streaming. First, we incorporate Look-Up Table (LUT) to lightweight convolution modules to achieve real-time latency. Second, for variant degradations, we propose a pixel-level LUT fusion strategy, where a set of LUT bases are built upon state-of-the-art SR networks pre-trained on different degraded data, and those LUT bases are combined with extracted weights from lightweight convolution modules to adaptively handle dynamic degradations. Extensive experiments are conducted on a newly proposed online video streaming dataset named LDV-WebRTC. All the results show that our method significantly outperforms existing LUT-based methods and offers competitive SR performance with faster speed compared to efficient CNN-based methods. Accelerated with our parallel LUT inference, our proposed method can even support online 720P video SR around 100 FPS.
Full-Cycle Energy Consumption Benchmark for Low-Carbon Computer Vision
Aug 30, 2021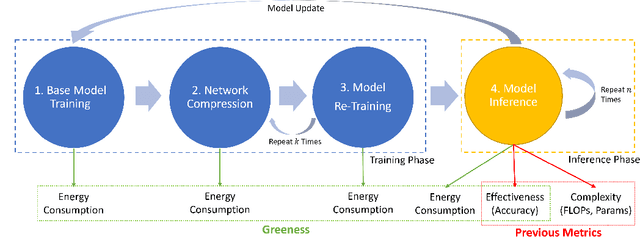
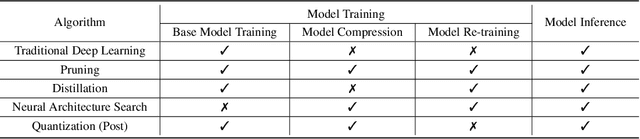

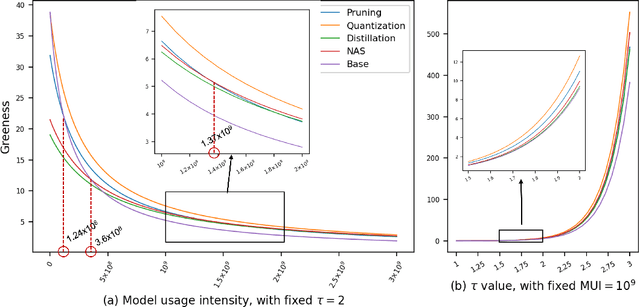
The energy consumption of deep learning models is increasing at a breathtaking rate, which raises concerns due to potential negative effects on carbon neutrality in the context of global warming and climate change. With the progress of efficient deep learning techniques, e.g., model compression, researchers can obtain efficient models with fewer parameters and smaller latency. However, most of the existing efficient deep learning methods do not explicitly consider energy consumption as a key performance indicator. Furthermore, existing methods mostly focus on the inference costs of the resulting efficient models, but neglect the notable energy consumption throughout the entire life cycle of the algorithm. In this paper, we present the first large-scale energy consumption benchmark for efficient computer vision models, where a new metric is proposed to explicitly evaluate the full-cycle energy consumption under different model usage intensity. The benchmark can provide insights for low carbon emission when selecting efficient deep learning algorithms in different model usage scenarios.