 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Every Frame Matter: Continuous Video Understanding for Large Models via Adaptive State Modeling
Paper and Code
Oct 19, 2024
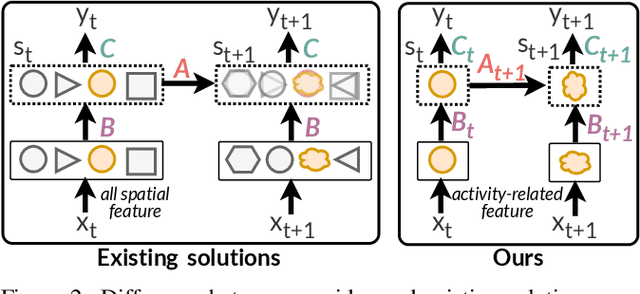
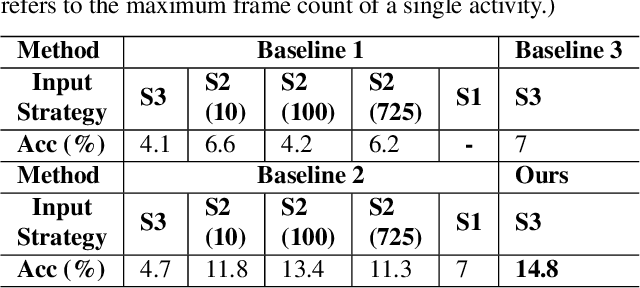
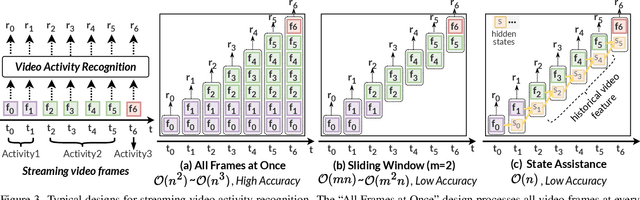
Video understanding has become increasingly important with the rise of multi-modality applications. Understanding continuous video poses considerable challenges due to the fast expansion of streaming video, which contains multi-scale and untrimmed events. We introduce a novel system, C-VUE, to overcome these issues through adaptive state modeling. C-VUE has three key designs. The first is a long-range history modeling technique that uses a video-aware approach to retain historical video information. The second is a spatial redundancy reduction technique, which enhances the efficiency of history modeling based on temporal relations. The third is a parallel training structure that incorporates the frame-weighted loss to understand multi-scale events in long videos. Our C-VUE offers high accuracy and efficiency. It runs at speeds >30 FPS on typical edge devices and outperforms all baselines in accuracy. Moreover, applying C-VUE to a video foundation model as a video encoder in our case study resulted in a 0.46-point enhancement (on a 5-point scale) on the in-distribution dataset, and an improvement ranging from 1.19\% to 4\% on zero-shot datasets.