 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Apr 11, 2026Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
Learning to Commit: Generating Organic Pull Requests via Online Repository Memory
Mar 27, 2026Large language model (LLM)-based coding agents achieve impressive results on controlled benchmarks yet routinely produce pull requests that real maintainers reject. The root cause is not functional incorrectness but a lack of organicity: generated code ignores project-specific conventions, duplicates functionality already provided by internal APIs, and violates implicit architectural constraints accumulated over years of development. Simply exposing an agent to the latest repository snapshot is not enough: the snapshot reveals the final state of the codebase, but not the repository-specific change patterns by which that state was reached. We introduce Learning to Commit, a framework that closes this gap through Online Repository Memory. Given a repository with a strict chronological split, the agent performs supervised contrastive reflection on earlier commits: it blindly attempts to resolve each historical issue, compares its prediction against the oracle diff, and distils the gap into a continuously growing set of skills-reusable patterns capturing coding style, internal API usage, and architectural invariants. When a new PR description arrives, the agent conditions its generation on these accumulated skills, producing changes grounded in the project's own evolution rather than generic pretraining priors. Evaluation is conducted on genuinely future, merged pull requests that could not have been seen during the skill-building phase, and spans multiple dimensions including functional correctness, code-style consistency, internal API reuse rate, and modified-region plausibility. Experiments on an expert-maintained repository with rich commit history show that Online Repository Memory effectively improves organicity scores on held-out future tasks.
Em-Garde: A Propose-Match Framework for Proactive Streaming Video Understanding
Mar 19, 2026Recent advances in Streaming Video Understanding has enabled a new interaction paradigm where models respond proactively to user queries. Current proactive VideoLLMs rely on per-frame triggering decision making, which suffers from an efficiency-accuracy dilemma. We propose Em-Garde, a novel framework that decouples semantic understanding from streaming perception. At query time, the Instruction-Guided Proposal Parser transforms user queries into structured, perceptually grounded visual proposals; during streaming, a Lightweight Proposal Matching Module performs efficient embedding-based matching to trigger responses. Experiments on StreamingBench and OVO-Bench demonstrate consistent improvements over prior models in proactive response accuracy and efficiency, validating an effective solution for proactive video understanding under strict computational constraints.
OxyGen: Unified KV Cache Management for Vision-Language-Action Models under Multi-Task Parallelism
Mar 15, 2026Embodied AI agents increasingly require parallel execution of multiple tasks, such as manipulation, conversation, and memory construction, from shared observations under distinct time constraints. Recent Mixture-of-Transformers (MoT) Vision-Language-Action Models (VLAs) architecturally support such heterogeneous outputs, yet existing inference systems fail to achieve efficient multi-task parallelism for on-device deployment due to redundant computation and resource contention. We identify isolated KV cache management as the root cause. To address this, we propose unified KV cache management, an inference paradigm that treats KV cache as a first-class shared resource across tasks and over time. This abstraction enables two key optimizations: cross-task KV sharing eliminates redundant prefill of shared observations, while cross-frame continuous batching decouples variable-length language decoding from fixed-rate action generation across control cycles. We implement this paradigm for $π_{0.5}$, the most popular MoT VLA, and evaluate under representative robotic configurations. OxyGen achieves up to 3.7$\times$ speedup over isolated execution, delivering over 200 tokens/s language throughput and 70 Hz action frequency simultaneously without action quality degradation.
Sculptor: Empowering LLMs with Cognitive Agency via Active Context Management
Aug 06, 2025Large Language Models (LLMs) suffer from significant performance degradation when processing long contexts due to proactive interference, where irrelevant information in earlier parts of the context disrupts reasoning and memory recall. While most research focuses on external memory systems to augment LLMs' capabilities, we propose a complementary approach: empowering LLMs with Active Context Management (ACM) tools to actively sculpt their internal working memory. We introduce Sculptor, a framework that equips LLMs with three categories of tools: (1) context fragmentation, (2) summary, hide, and restore, and (3) intelligent search. Our approach enables LLMs to proactively manage their attention and working memory, analogous to how humans selectively focus on relevant information while filtering out distractions. Experimental evaluation on information-sparse benchmarks-PI-LLM (proactive interference) and NeedleBench Multi-Needle Reasoning-demonstrates that Sculptor significantly improves performance even without specific training, leveraging LLMs' inherent tool calling generalization capabilities. By enabling Active Context Management, Sculptor not only mitigates proactive interference but also provides a cognitive foundation for more reliable reasoning across diverse long-context tasks-highlighting that explicit context-control strategies, rather than merely larger token windows, are key to robustness at scale.
SeerAttention-R: Sparse Attention Adaptation for Long Reasoning
Jun 10, 2025



We introduce SeerAttention-R, a sparse attention framework specifically tailored for the long decoding of reasoning models. Extended from SeerAttention, SeerAttention-R retains the design of learning attention sparsity through a self-distilled gating mechanism, while removing query pooling to accommodate auto-regressive decoding. With a lightweight plug-in gating, SeerAttention-R is flexible and can be easily integrated into existing pretrained model without modifying the original parameters. We demonstrate that SeerAttention-R, trained on just 0.4B tokens, maintains near-lossless reasoning accuracy with 4K token budget in AIME benchmark under large sparse attention block sizes (64/128). Using TileLang, we develop a highly optimized sparse decoding kernel that achieves near-theoretical speedups of up to 9x over FlashAttention-3 on H100 GPU at 90% sparsity. Code is available at: https://github.com/microsoft/SeerAttention.
SwarmThinkers: Learning Physically Consistent Atomic KMC Transitions at Scale
May 26, 2025Can a scientific simulation system be physically consistent, interpretable by design, and scalable across regimes--all at once? Despite decades of progress, this trifecta remains elusive. Classical methods like Kinetic Monte Carlo ensure thermodynamic accuracy but scale poorly; learning-based methods offer efficiency but often sacrifice physical consistency and interpretability. We present SwarmThinkers, a reinforcement learning framework that recasts atomic-scale simulation as a physically grounded swarm intelligence system. Each diffusing particle is modeled as a local decision-making agent that selects transitions via a shared policy network trained under thermodynamic constraints. A reweighting mechanism fuses learned preferences with transition rates, preserving statistical fidelity while enabling interpretable, step-wise decision making. Training follows a centralized-training, decentralized-execution paradigm, allowing the policy to generalize across system sizes, concentrations, and temperatures without retraining. On a benchmark simulating radiation-induced Fe-Cu alloy precipitation, SwarmThinkers is the first system to achieve full-scale, physically consistent simulation on a single A100 GPU, previously attainable only via OpenKMC on a supercomputer. It delivers up to 4963x (3185x on average) faster computation with 485x lower memory usage. By treating particles as decision-makers, not passive samplers, SwarmThinkers marks a paradigm shift in scientific simulation--one that unifies physical consistency, interpretability, and scalability through agent-driven intelligence.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025

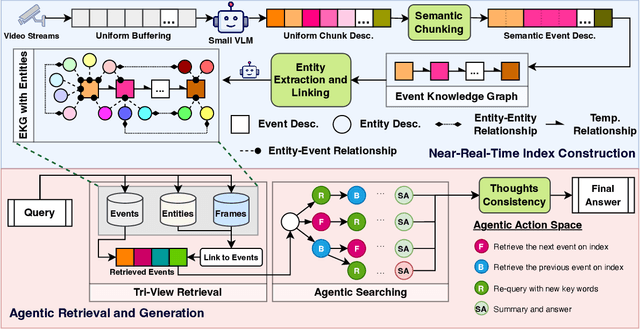
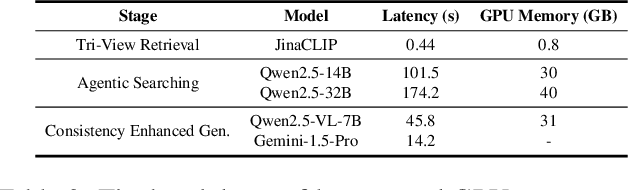
AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Zoomer: Adaptive Image Focus Optimization for Black-box MLLM
Apr 30, 2025



Recent advancements in multimodal large language models (MLLMs) have broadened the scope of vision-language tasks, excelling in applications like image captioning and interactive question-answering. However, these models struggle with accurately processing visual data, particularly in tasks requiring precise object recognition and fine visual details. Stringent token limits often result in the omission of critical information, hampering performance. To address these limitations, we introduce \SysName, a novel visual prompting mechanism designed to enhance MLLM performance while preserving essential visual details within token limits. \SysName features three key innovations: a prompt-aware strategy that dynamically highlights relevant image regions, a spatial-preserving orchestration schema that maintains object integrity, and a budget-aware prompting method that balances global context with crucial visual details. Comprehensive evaluations across multiple datasets demonstrate that \SysName consistently outperforms baseline methods, achieving up to a $26.9\%$ improvement in accuracy while significantly reducing token consumption.
Scaling Up On-Device LLMs via Active-Weight Swapping Between DRAM and Flash
Apr 11, 2025Large language models (LLMs) are increasingly being deployed on mobile devices, but the limited DRAM capacity constrains the deployable model size. This paper introduces ActiveFlow, the first LLM inference framework that can achieve adaptive DRAM usage for modern LLMs (not ReLU-based), enabling the scaling up of deployable model sizes. The framework is based on the novel concept of active weight DRAM-flash swapping and incorporates three novel techniques: (1) Cross-layer active weights preloading. It uses the activations from the current layer to predict the active weights of several subsequent layers, enabling computation and data loading to overlap, as well as facilitating large I/O transfers. (2) Sparsity-aware self-distillation. It adjusts the active weights to align with the dense-model output distribution, compensating for approximations introduced by contextual sparsity. (3) Active weight DRAM-flash swapping pipeline. It orchestrates the DRAM space allocation among the hot weight cache, preloaded active weights, and computation-involved weights based on available memory. Results show ActiveFlow achieves the performance-cost Pareto frontier compared to existing efficiency optimization methods.