 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLUT-DLA: Lookup Table as Efficient Extreme Low-Bit Deep Learning Accelerator
Jan 18, 2025The emergence of neural network capabilities invariably leads to a significant surge in computational demands due to expanding model sizes and increased computational complexity. To reduce model size and lower inference costs, recent research has focused on simplifying models and designing hardware accelerators using low-bit quantization. However, due to numerical representation limits, scalar quantization cannot reduce bit width lower than 1-bit, diminishing its benefits. To break through these limitations, we introduce LUT-DLA, a Look-Up Table (LUT) Deep Learning Accelerator Framework that utilizes vector quantization to convert neural network models into LUTs, achieving extreme low-bit quantization. The LUT-DLA framework facilitates efficient and cost-effective hardware accelerator designs and supports the LUTBoost algorithm, which helps to transform various DNN models into LUT-based models via multistage training, drastically cutting both computational and hardware overhead. Additionally, through co-design space exploration, LUT-DLA assesses the impact of various model and hardware parameters to fine-tune hardware configurations for different application scenarios, optimizing performance and efficiency. Our comprehensive experiments show that LUT-DLA achieves improvements in power efficiency and area efficiency with gains of $1.4$~$7.0\times$ and $1.5$~$146.1\times$, respectively, while maintaining only a modest accuracy drop. For CNNs, accuracy decreases by $0.1\%$~$3.1\%$ using the $L_2$ distance similarity, $0.1\%$~$3.4\%$ with the $L_1$ distance similarity, and $0.1\%$~$3.8\%$ when employing the Chebyshev distance similarity. For transformer-based models, the accuracy drop ranges from $1.4\%$ to $3.0\%$.
LPViT: Low-Power Semi-structured Pruning for Vision Transformers
Jul 02, 2024
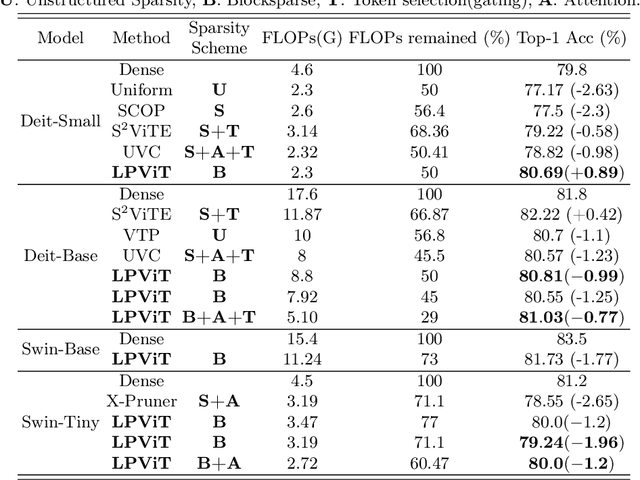

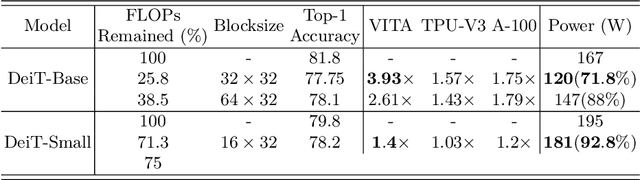
Vision transformers have emerged as a promising alternative to convolutional neural networks for various image analysis tasks, offering comparable or superior performance. However, one significant drawback of ViTs is their resource-intensive nature, leading to increased memory footprint, computation complexity, and power consumption. To democratize this high-performance technology and make it more environmentally friendly, it is essential to compress ViT models, reducing their resource requirements while maintaining high performance. In this paper, we introduce a new block-structured pruning to address the resource-intensive issue for ViTs, offering a balanced trade-off between accuracy and hardware acceleration. Unlike unstructured pruning or channel-wise structured pruning, block pruning leverages the block-wise structure of linear layers, resulting in more efficient matrix multiplications. To optimize this pruning scheme, our paper proposes a novel hardware-aware learning objective that simultaneously maximizes speedup and minimizes power consumption during inference, tailored to the block sparsity structure. This objective eliminates the need for empirical look-up tables and focuses solely on reducing parametrized layer connections. Moreover, our paper provides a lightweight algorithm to achieve post-training pruning for ViTs, utilizing second-order Taylor approximation and empirical optimization to solve the proposed hardware-aware objective. Extensive experiments on ImageNet are conducted across various ViT architectures, including DeiT-B and DeiT-S, demonstrating competitive performance with other pruning methods and achieving a remarkable balance between accuracy preservation and power savings. Especially, we achieve up to 3.93x and 1.79x speedups on dedicated hardware and GPUs respectively for DeiT-B, and also observe an inference power reduction by 1.4x on real-world GPUs.
From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
May 09, 2024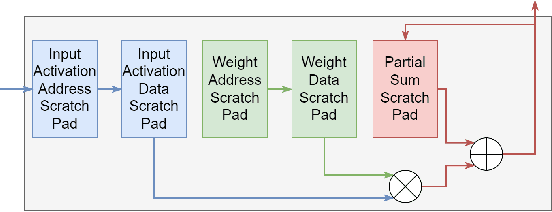
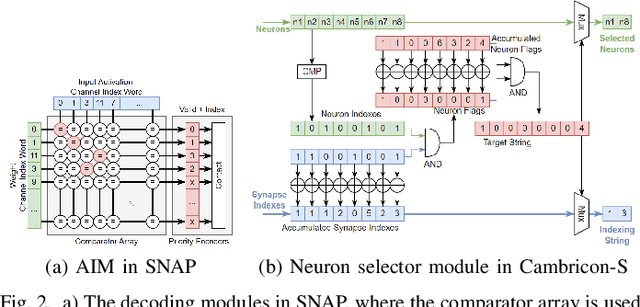

Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.