 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMsFormer: Enabling Robust Predictive Maintenance Services for Industrial Devices
Mar 24, 2026Providing reliable predictive maintenance is a critical industrial AI service essential for ensuring the high availability of manufacturing devices. Existing deep-learning methods present competitive results on such tasks but lack a general service-oriented framework to capture complex dependencies in industrial IoT sensor data. While Transformer-based models show strong sequence modeling capabilities, their direct deployment as robust AI services faces significant bottlenecks. Specifically, streaming sensor data collected in real-world service environments often exhibits multi-scale temporal correlations driven by machine working principles. Besides, the datasets available for training time-to-failure predictive services are typically limited in size. These issues pose significant challenges for directly applying existing models as robust predictive services. To address these challenges, we propose MsFormer, a lightweight Multi-scale Transformer designed as a unified AI service model for reliable industrial predictive maintenance. MsFormer incorporates a Multi-scale Sampling (MS) module and a tailored position encoding mechanism to capture sequential correlations across multi-streaming service data. Additionally, to accommodate data-scarce service environments, MsFormer adopts a lightweight attention mechanism with straightforward pooling operations instead of self-attention. Extensive experiments on real-world datasets demonstrate that the proposed framework achieves significant performance improvements over state-of-the-art methods. Furthermore, MsFormer outperforms across industrial devices and operating conditions, demonstrating strong generalizability while maintaining a highly reliable Quality of Service (QoS).
Evidential Domain Adaptation for Remaining Useful Life Prediction with Incomplete Degradation
Mar 15, 2026Accurate Remaining Useful Life (RUL) prediction without labeled target domain data is a critical challenge, and domain adaptation (DA) has been widely adopted to address it by transferring knowledge from a labeled source domain to an unlabeled target domain. Despite its success, existing DA methods struggle significantly when faced with incomplete degradation trajectories in the target domain, particularly due to the absence of late degradation stages. This missing data introduces a key extrapolation challenge. When applied to such incomplete RUL prediction tasks, current DA methods encounter two primary limitations. First, most DA approaches primarily focus on global alignment, which can misaligns late degradation stage in the source domain with early degradation stage in the target domain. Second, due to varying operating conditions in RUL prediction, degradation patterns may differ even within the same degradation stage, resulting in different learned features. As a result, even if degradation stages are partially aligned, simple feature matching cannot fully align two domains. To overcome these limitations, we propose a novel evidential adaptation approach called EviAdapt, which leverages evidential learning to enhance domain adaptation. The method first segments the source and target domain data into distinct degradation stages based on degradation rate, enabling stage-wise alignment that ensures samples from corresponding stages are accurately matched. To address the second limitation, we introduce an evidential uncertainty alignment technique that estimates uncertainty using evidential learning and aligns the uncertainty across matched stages.
Bridging Distribution Gaps in Time Series Foundation Model Pretraining with Prototype-Guided Normalization
Apr 15, 2025Foundation models have achieved remarkable success across diverse machine-learning domains through large-scale pretraining on large, diverse datasets. However, pretraining on such datasets introduces significant challenges due to substantial mismatches in data distributions, a problem particularly pronounced with time series data. In this paper, we tackle this issue by proposing a domain-aware adaptive normalization strategy within the Transformer architecture. Specifically, we replace the traditional LayerNorm with a prototype-guided dynamic normalization mechanism (ProtoNorm), where learned prototypes encapsulate distinct data distributions, and sample-to-prototype affinity determines the appropriate normalization layer. This mechanism effectively captures the heterogeneity of time series characteristics, aligning pretrained representations with downstream tasks. Through comprehensive empirical evaluation, we demonstrate that our method significantly outperforms conventional pretraining techniques across both classification and forecasting tasks, while effectively mitigating the adverse effects of distribution shifts during pretraining. Incorporating ProtoNorm is as simple as replacing a single line of code. Extensive experiments on diverse real-world time series benchmarks validate the robustness and generalizability of our approach, advancing the development of more versatile time series foundation models.
UniFault: A Fault Diagnosis Foundation Model from Bearing Data
Apr 02, 2025Machine fault diagnosis (FD) is a critical task for predictive maintenance, enabling early fault detection and preventing unexpected failures. Despite its importance, existing FD models are operation-specific with limited generalization across diverse datasets. Foundation models (FM) have demonstrated remarkable potential in both visual and language domains, achieving impressive generalization capabilities even with minimal data through few-shot or zero-shot learning. However, translating these advances to FD presents unique hurdles. Unlike the large-scale, cohesive datasets available for images and text, FD datasets are typically smaller and more heterogeneous, with significant variations in sampling frequencies and the number of channels across different systems and applications. This heterogeneity complicates the design of a universal architecture capable of effectively processing such diverse data while maintaining robust feature extraction and learning capabilities. In this paper, we introduce UniFault, a foundation model for fault diagnosis that systematically addresses these issues. Specifically, the model incorporates a comprehensive data harmonization pipeline featuring two key innovations. First, a unification scheme transforms multivariate inputs into standardized univariate sequences while retaining local inter-channel relationships. Second, a novel cross-domain temporal fusion strategy mitigates distribution shifts and enriches sample diversity and count, improving the model generalization across varying conditions. UniFault is pretrained on over 9 billion data points spanning diverse FD datasets, enabling superior few-shot performance. Extensive experiments on real-world FD datasets demonstrate that UniFault achieves SoTA performance, setting a new benchmark for fault diagnosis models and paving the way for more scalable and robust predictive maintenance solutions.
Augmented Contrastive Clustering with Uncertainty-Aware Prototyping for Time Series Test Time Adaptation
Jan 01, 2025



Test-time adaptation aims to adapt pre-trained deep neural networks using solely online unlabelled test data during inference. Although TTA has shown promise in visual applications, its potential in time series contexts remains largely unexplored. Existing TTA methods, originally designed for visual tasks, may not effectively handle the complex temporal dynamics of real-world time series data, resulting in suboptimal adaptation performance. To address this gap, we propose Augmented Contrastive Clustering with Uncertainty-aware Prototyping (ACCUP), a straightforward yet effective TTA method for time series data. Initially, our approach employs augmentation ensemble on the time series data to capture diverse temporal information and variations, incorporating uncertainty-aware prototypes to distill essential characteristics. Additionally, we introduce an entropy comparison scheme to selectively acquire more confident predictions, enhancing the reliability of pseudo labels. Furthermore, we utilize augmented contrastive clustering to enhance feature discriminability and mitigate error accumulation from noisy pseudo labels, promoting cohesive clustering within the same class while facilitating clear separation between different classes. Extensive experiments conducted on three real-world time series datasets and an additional visual dataset demonstrate the effectiveness and generalization potential of the proposed method, advancing the underexplored realm of TTA for time series data.
WiFi CSI Based Temporal Activity Detection Via Dual Pyramid Network
Dec 19, 2024We address the challenge of WiFi-based temporal activity detection and propose an efficient Dual Pyramid Network that integrates Temporal Signal Semantic Encoders and Local Sensitive Response Encoders. The Temporal Signal Semantic Encoder splits feature learning into high and low-frequency components, using a novel Signed Mask-Attention mechanism to emphasize important areas and downplay unimportant ones, with the features fused using ContraNorm. The Local Sensitive Response Encoder captures fluctuations without learning. These feature pyramids are then combined using a new cross-attention fusion mechanism. We also introduce a dataset with over 2,114 activity segments across 553 WiFi CSI samples, each lasting around 85 seconds. Extensive experiments show our method outperforms challenging baselines. Code and dataset are available at https://github.com/AVC2-UESTC/WiFiTAD.
Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning
Nov 03, 2024



Meta-learning offers a promising avenue for few-shot learning (FSL), enabling models to glean a generalizable feature embedding through episodic training on synthetic FSL tasks in a source domain. Yet, in practical scenarios where the target task diverges from that in the source domain, meta-learning based method is susceptible to over-fitting. To overcome this, we introduce a novel framework, Meta-Exploiting Frequency Prior for Cross-Domain Few-Shot Learning, which is crafted to comprehensively exploit the cross-domain transferable image prior that each image can be decomposed into complementary low-frequency content details and high-frequency robust structural characteristics. Motivated by this insight, we propose to decompose each query image into its high-frequency and low-frequency components, and parallel incorporate them into the feature embedding network to enhance the final category prediction. More importantly, we introduce a feature reconstruction prior and a prediction consistency prior to separately encourage the consistency of the intermediate feature as well as the final category prediction between the original query image and its decomposed frequency components. This allows for collectively guiding the network's meta-learning process with the aim of learning generalizable image feature embeddings, while not introducing any extra computational cost in the inference phase. Our framework establishes new state-of-the-art results on multiple cross-domain few-shot learning benchmarks.
Temporal Source Recovery for Time-Series Source-Free Unsupervised Domain Adaptation
Sep 29, 2024Source-Free Unsupervised Domain Adaptation (SFUDA) has gained popularity for its ability to adapt pretrained models to target domains without accessing source domains, ensuring source data privacy. While SFUDA is well-developed in visual tasks, its application to Time-Series SFUDA (TS-SFUDA) remains limited due to the challenge of transferring crucial temporal dependencies across domains. Although a few researchers begin to explore this area, they rely on specific source domain designs, which are impractical as source data owners cannot be expected to follow particular pretraining protocols. To solve this, we propose Temporal Source Recovery (TemSR), a framework that transfers temporal dependencies for effective TS-SFUDA without requiring source-specific designs. TemSR features a recovery process that leverages masking, recovery, and optimization to generate a source-like distribution with recovered source temporal dependencies. To ensure effective recovery, we further design segment-based regularization to restore local dependencies and anchor-based recovery diversity maximization to enhance the diversity of the source-like distribution. The source-like distribution is then adapted to the target domain using traditional UDA techniques. Extensive experiments across multiple TS tasks demonstrate the effectiveness of TemSR, even surpassing existing TS-SFUDA method that requires source domain designs. Code is available in https://github.com/Frank-Wang-oss/TemSR.
EverAdapt: Continuous Adaptation for Dynamic Machine Fault Diagnosis Environments
Jul 24, 2024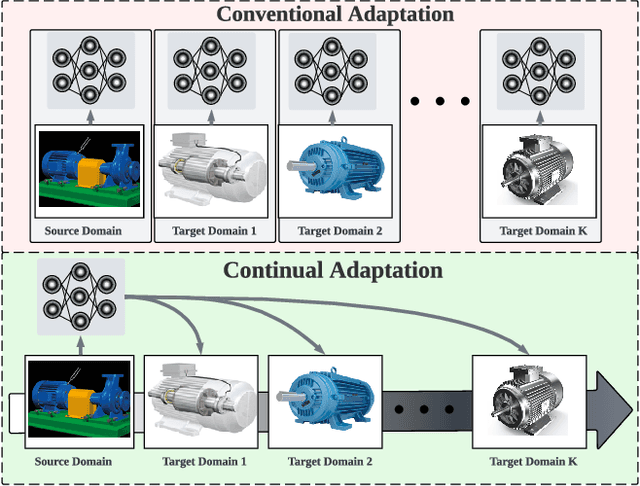
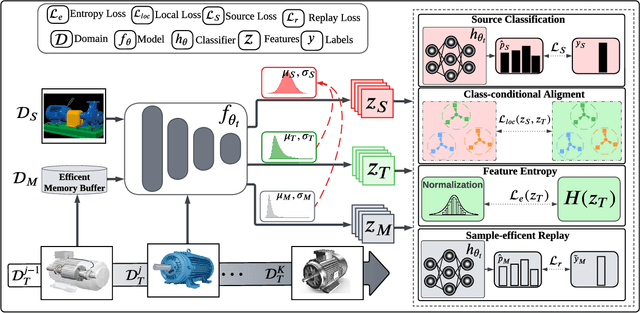
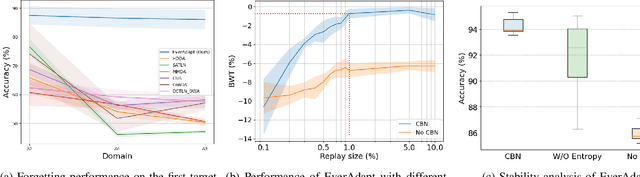
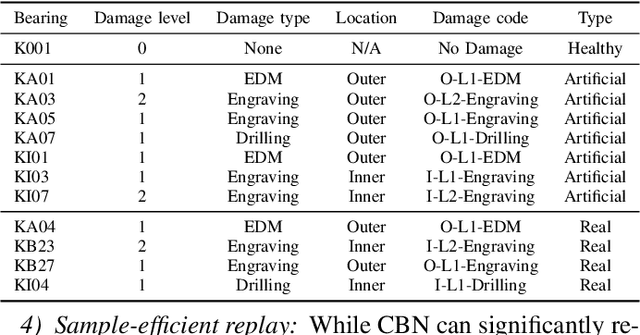
Unsupervised Domain Adaptation (UDA) has emerged as a key solution in data-driven fault diagnosis, addressing domain shift where models underperform in changing environments. However, under the realm of continually changing environments, UDA tends to underperform on previously seen domains when adapting to new ones - a problem known as catastrophic forgetting. To address this limitation, we introduce the EverAdapt framework, specifically designed for continuous model adaptation in dynamic environments. Central to EverAdapt is a novel Continual Batch Normalization (CBN), which leverages source domain statistics as a reference point to standardize feature representations across domains. EverAdapt not only retains statistical information from previous domains but also adapts effectively to new scenarios. Complementing CBN, we design a class-conditional domain alignment module for effective integration of target domains, and a Sample-efficient Replay strategy to reinforce memory retention. Experiments on real-world datasets demonstrate EverAdapt superiority in maintaining robust fault diagnosis in dynamic environments. Our code is available: https://github.com/mohamedr002/EverAdapt
Intelligent Cross-Organizational Process Mining: A Survey and New Perspectives
Jul 15, 2024



Process mining, as a high-level field in data mining, plays a crucial role in enhancing operational efficiency and decision-making across organizations. In this survey paper, we delve into the growing significance and ongoing trends in the field of process mining, advocating a specific viewpoint on its contents, application, and development in modern businesses and process management, particularly in cross-organizational settings. We first summarize the framework of process mining, common industrial applications, and the latest advances combined with artificial intelligence, such as workflow optimization, compliance checking, and performance analysis. Then, we propose a holistic framework for intelligent process analysis and outline initial methodologies in cross-organizational settings, highlighting both challenges and opportunities. This particular perspective aims to revolutionize process mining by leveraging artificial intelligence to offer sophisticated solutions for complex, multi-organizational data analysis. By integrating advanced machine learning techniques, we can enhance predictive capabilities, streamline processes, and facilitate real-time decision-making. Furthermore, we pinpoint avenues for future investigations within the research community, encouraging the exploration of innovative algorithms, data integration strategies, and privacy-preserving methods to fully harness the potential of process mining in diverse, interconnected business environments.