 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Domain Adaptation for Remaining Useful Life Prediction with Incomplete Degradation
Mar 15, 2026Accurate Remaining Useful Life (RUL) prediction without labeled target domain data is a critical challenge, and domain adaptation (DA) has been widely adopted to address it by transferring knowledge from a labeled source domain to an unlabeled target domain. Despite its success, existing DA methods struggle significantly when faced with incomplete degradation trajectories in the target domain, particularly due to the absence of late degradation stages. This missing data introduces a key extrapolation challenge. When applied to such incomplete RUL prediction tasks, current DA methods encounter two primary limitations. First, most DA approaches primarily focus on global alignment, which can misaligns late degradation stage in the source domain with early degradation stage in the target domain. Second, due to varying operating conditions in RUL prediction, degradation patterns may differ even within the same degradation stage, resulting in different learned features. As a result, even if degradation stages are partially aligned, simple feature matching cannot fully align two domains. To overcome these limitations, we propose a novel evidential adaptation approach called EviAdapt, which leverages evidential learning to enhance domain adaptation. The method first segments the source and target domain data into distinct degradation stages based on degradation rate, enabling stage-wise alignment that ensures samples from corresponding stages are accurately matched. To address the second limitation, we introduce an evidential uncertainty alignment technique that estimates uncertainty using evidential learning and aligns the uncertainty across matched stages.
UniFault: A Fault Diagnosis Foundation Model from Bearing Data
Apr 02, 2025Machine fault diagnosis (FD) is a critical task for predictive maintenance, enabling early fault detection and preventing unexpected failures. Despite its importance, existing FD models are operation-specific with limited generalization across diverse datasets. Foundation models (FM) have demonstrated remarkable potential in both visual and language domains, achieving impressive generalization capabilities even with minimal data through few-shot or zero-shot learning. However, translating these advances to FD presents unique hurdles. Unlike the large-scale, cohesive datasets available for images and text, FD datasets are typically smaller and more heterogeneous, with significant variations in sampling frequencies and the number of channels across different systems and applications. This heterogeneity complicates the design of a universal architecture capable of effectively processing such diverse data while maintaining robust feature extraction and learning capabilities. In this paper, we introduce UniFault, a foundation model for fault diagnosis that systematically addresses these issues. Specifically, the model incorporates a comprehensive data harmonization pipeline featuring two key innovations. First, a unification scheme transforms multivariate inputs into standardized univariate sequences while retaining local inter-channel relationships. Second, a novel cross-domain temporal fusion strategy mitigates distribution shifts and enriches sample diversity and count, improving the model generalization across varying conditions. UniFault is pretrained on over 9 billion data points spanning diverse FD datasets, enabling superior few-shot performance. Extensive experiments on real-world FD datasets demonstrate that UniFault achieves SoTA performance, setting a new benchmark for fault diagnosis models and paving the way for more scalable and robust predictive maintenance solutions.
I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
Jan 14, 2025


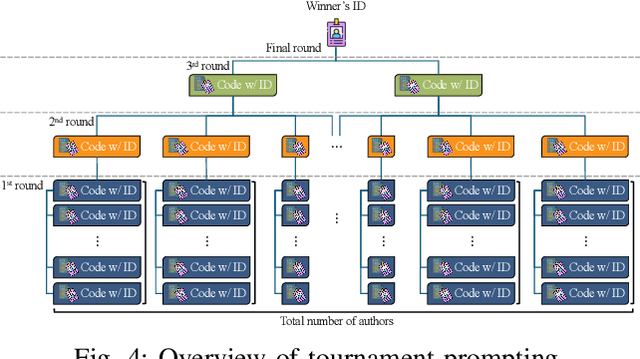
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.
Augmented Contrastive Clustering with Uncertainty-Aware Prototyping for Time Series Test Time Adaptation
Jan 01, 2025



Test-time adaptation aims to adapt pre-trained deep neural networks using solely online unlabelled test data during inference. Although TTA has shown promise in visual applications, its potential in time series contexts remains largely unexplored. Existing TTA methods, originally designed for visual tasks, may not effectively handle the complex temporal dynamics of real-world time series data, resulting in suboptimal adaptation performance. To address this gap, we propose Augmented Contrastive Clustering with Uncertainty-aware Prototyping (ACCUP), a straightforward yet effective TTA method for time series data. Initially, our approach employs augmentation ensemble on the time series data to capture diverse temporal information and variations, incorporating uncertainty-aware prototypes to distill essential characteristics. Additionally, we introduce an entropy comparison scheme to selectively acquire more confident predictions, enhancing the reliability of pseudo labels. Furthermore, we utilize augmented contrastive clustering to enhance feature discriminability and mitigate error accumulation from noisy pseudo labels, promoting cohesive clustering within the same class while facilitating clear separation between different classes. Extensive experiments conducted on three real-world time series datasets and an additional visual dataset demonstrate the effectiveness and generalization potential of the proposed method, advancing the underexplored realm of TTA for time series data.
Unsupervised Fingerphoto Presentation Attack Detection With Diffusion Models
Sep 27, 2024
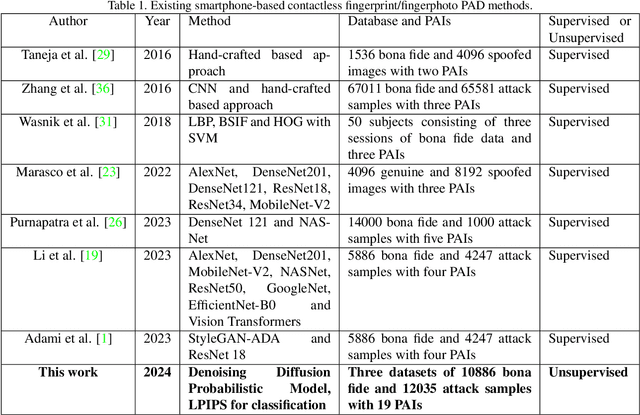
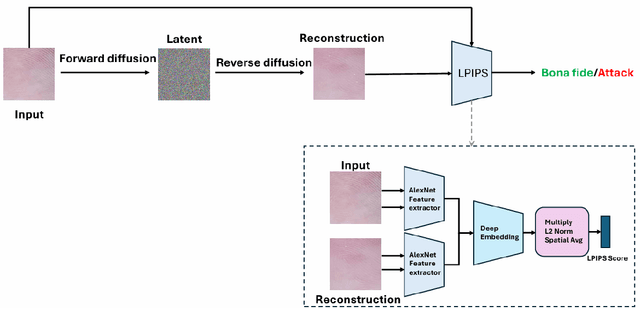
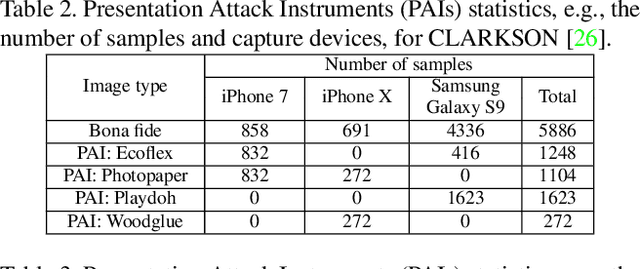
Smartphone-based contactless fingerphoto authentication has become a reliable alternative to traditional contact-based fingerprint biometric systems owing to rapid advances in smartphone camera technology. Despite its convenience, fingerprint authentication through fingerphotos is more vulnerable to presentation attacks, which has motivated recent research efforts towards developing fingerphoto Presentation Attack Detection (PAD) techniques. However, prior PAD approaches utilized supervised learning methods that require labeled training data for both bona fide and attack samples. This can suffer from two key issues, namely (i) generalization:the detection of novel presentation attack instruments (PAIs) unseen in the training data, and (ii) scalability:the collection of a large dataset of attack samples using different PAIs. To address these challenges, we propose a novel unsupervised approach based on a state-of-the-art deep-learning-based diffusion model, the Denoising Diffusion Probabilistic Model (DDPM), which is trained solely on bona fide samples. The proposed approach detects Presentation Attacks (PA) by calculating the reconstruction similarity between the input and output pairs of the DDPM. We present extensive experiments across three PAI datasets to test the accuracy and generalization capability of our approach. The results show that the proposed DDPM-based PAD method achieves significantly better detection error rates on several PAI classes compared to other baseline unsupervised approaches.
EverAdapt: Continuous Adaptation for Dynamic Machine Fault Diagnosis Environments
Jul 24, 2024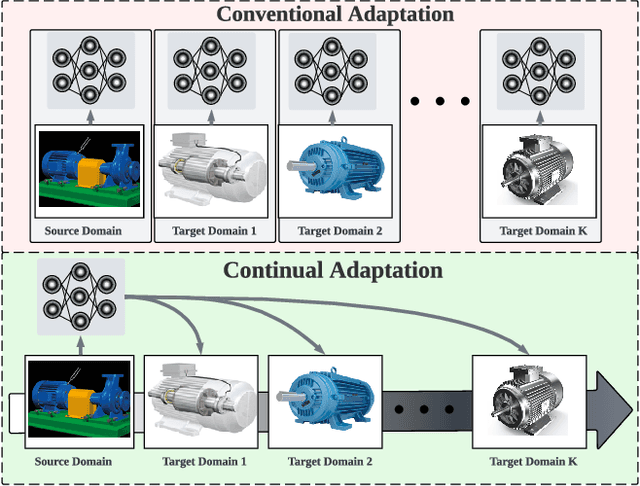
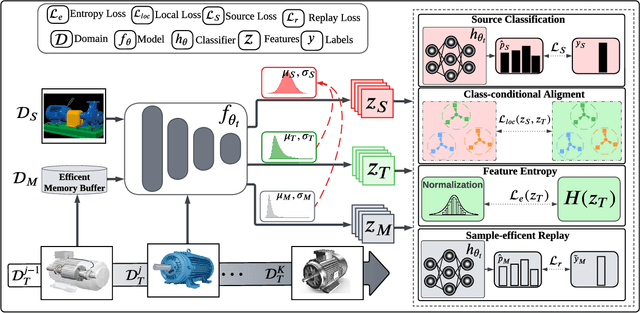
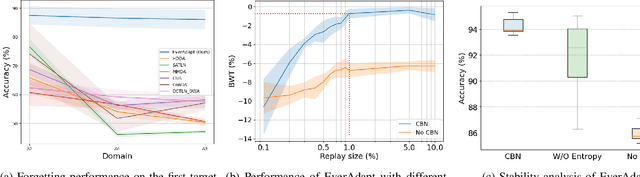
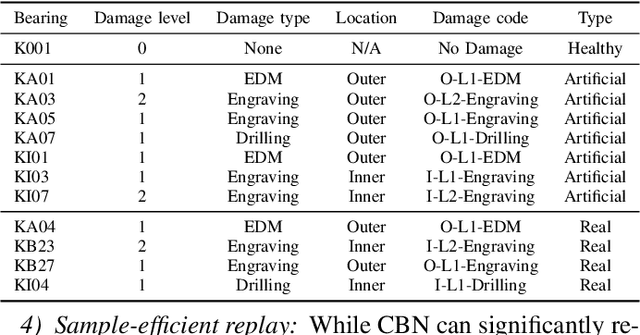
Unsupervised Domain Adaptation (UDA) has emerged as a key solution in data-driven fault diagnosis, addressing domain shift where models underperform in changing environments. However, under the realm of continually changing environments, UDA tends to underperform on previously seen domains when adapting to new ones - a problem known as catastrophic forgetting. To address this limitation, we introduce the EverAdapt framework, specifically designed for continuous model adaptation in dynamic environments. Central to EverAdapt is a novel Continual Batch Normalization (CBN), which leverages source domain statistics as a reference point to standardize feature representations across domains. EverAdapt not only retains statistical information from previous domains but also adapts effectively to new scenarios. Complementing CBN, we design a class-conditional domain alignment module for effective integration of target domains, and a Sample-efficient Replay strategy to reinforce memory retention. Experiments on real-world datasets demonstrate EverAdapt superiority in maintaining robust fault diagnosis in dynamic environments. Our code is available: https://github.com/mohamedr002/EverAdapt
Evidentially Calibrated Source-Free Time-Series Domain Adaptation with Temporal Imputation
Jun 04, 2024



Source-free domain adaptation (SFDA) aims to adapt a model pre-trained on a labeled source domain to an unlabeled target domain without access to source data, preserving the source domain's privacy. While SFDA is prevalent in computer vision, it remains largely unexplored in time series analysis. Existing SFDA methods, designed for visual data, struggle to capture the inherent temporal dynamics of time series, hindering adaptation performance. This paper proposes MAsk And imPUte (MAPU), a novel and effective approach for time series SFDA. MAPU addresses the critical challenge of temporal consistency by introducing a novel temporal imputation task. This task involves randomly masking time series signals and leveraging a dedicated temporal imputer to recover the original signal within the learned embedding space, bypassing the complexities of noisy raw data. Notably, MAPU is the first method to explicitly address temporal consistency in the context of time series SFDA. Additionally, it offers seamless integration with existing SFDA methods, providing greater flexibility. We further introduce E-MAPU, which incorporates evidential uncertainty estimation to address the overconfidence issue inherent in softmax predictions. To achieve that, we leverage evidential deep learning to obtain a better-calibrated pre-trained model and adapt the target encoder to map out-of-support target samples to a new feature representation closer to the source domain's support. This fosters better alignment, ultimately enhancing adaptation performance. Extensive experiments on five real-world time series datasets demonstrate that both MAPU and E-MAPU achieve significant performance gains compared to existing methods. These results highlight the effectiveness of our proposed approaches for tackling various time series domain adaptation problems.
Overcoming Negative Transfer by Online Selection: Distant Domain Adaptation for Fault Diagnosis
May 25, 2024



Unsupervised domain adaptation (UDA) has achieved remarkable success in fault diagnosis, bringing significant benefits to diverse industrial applications. While most UDA methods focus on cross-working condition scenarios where the source and target domains are notably similar, real-world applications often grapple with severe domain shifts. We coin the term `distant domain adaptation problem' to describe the challenge of adapting from a labeled source domain to a significantly disparate unlabeled target domain. This problem exhibits the risk of negative transfer, where extraneous knowledge from the source domain adversely affects the target domain performance. Unfortunately, conventional UDA methods often falter in mitigating this negative transfer, leading to suboptimal performance. In response to this challenge, we propose a novel Online Selective Adversarial Alignment (OSAA) approach. Central to OSAA is its ability to dynamically identify and exclude distant source samples via an online gradient masking approach, focusing primarily on source samples that closely resemble the target samples. Furthermore, recognizing the inherent complexities in bridging the source and target domains, we construct an intermediate domain to act as a transitional domain and ease the adaptation process. Lastly, we develop a class-conditional adversarial adaptation to address the label distribution disparities while learning domain invariant representation to account for potential label distribution disparities between the domains. Through detailed experiments and ablation studies on two real-world datasets, we validate the superior performance of the OSAA method over state-of-the-art methods, underscoring its significant utility in practical scenarios with severe domain shifts.
TSLANet: Rethinking Transformers for Time Series Representation Learning
Apr 12, 2024



Time series data, characterized by its intrinsic long and short-range dependencies, poses a unique challenge across analytical applications. While Transformer-based models excel at capturing long-range dependencies, they face limitations in noise sensitivity, computational efficiency, and overfitting with smaller datasets. In response, we introduce a novel Time Series Lightweight Adaptive Network (TSLANet), as a universal convolutional model for diverse time series tasks. Specifically, we propose an Adaptive Spectral Block, harnessing Fourier analysis to enhance feature representation and to capture both long-term and short-term interactions while mitigating noise via adaptive thresholding. Additionally, we introduce an Interactive Convolution Block and leverage self-supervised learning to refine the capacity of TSLANet for decoding complex temporal patterns and improve its robustness on different datasets. Our comprehensive experiments demonstrate that TSLANet outperforms state-of-the-art models in various tasks spanning classification, forecasting, and anomaly detection, showcasing its resilience and adaptability across a spectrum of noise levels and data sizes. The code is available at \url{https://github.com/emadeldeen24/TSLANet}
Universal Semi-Supervised Domain Adaptation by Mitigating Common-Class Bias
Mar 17, 2024



Domain adaptation is a critical task in machine learning that aims to improve model performance on a target domain by leveraging knowledge from a related source domain. In this work, we introduce Universal Semi-Supervised Domain Adaptation (UniSSDA), a practical yet challenging setting where the target domain is partially labeled, and the source and target label space may not strictly match. UniSSDA is at the intersection of Universal Domain Adaptation (UniDA) and Semi-Supervised Domain Adaptation (SSDA): the UniDA setting does not allow for fine-grained categorization of target private classes not represented in the source domain, while SSDA focuses on the restricted closed-set setting where source and target label spaces match exactly. Existing UniDA and SSDA methods are susceptible to common-class bias in UniSSDA settings, where models overfit to data distributions of classes common to both domains at the expense of private classes. We propose a new prior-guided pseudo-label refinement strategy to reduce the reinforcement of common-class bias due to pseudo-labeling, a common label propagation strategy in domain adaptation. We demonstrate the effectiveness of the proposed strategy on benchmark datasets Office-Home, DomainNet, and VisDA. The proposed strategy attains the best performance across UniSSDA adaptation settings and establishes a new baseline for UniSSDA.