 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInA-Probe: Instruction-Aware Active Probing for Time Series Forecasting with LLMs
Jun 07, 2026Large Language Models (LLMs) have recently demonstrated impressive potential for time series forecasting. However, existing methods predominantly rely on passive modality alignment or static task reprogramming, which often fail to capture fine-grained, non-stationary temporal patterns or to adapt to nuanced task intents. In this paper, we propose Instruction-aware Active Probing (InA-Probe), which shifts the paradigm from passive alignment toward an active, instruction-driven probing mechanism. Specifically, we design a Multi-Level Instruction Injection mechanism that enriches the model with both global task objectives and fine-grained, patch-level semantic priors. Building on this, an Adaptive Query Generation module produces sample-specific probes that are dynamically modulated by the temporal context. These probes are then refined through a dual-stage attention process: they first internalize task-specific intents via Instruction-Aware Self-Attention, and subsequently interrogate the projected temporal representations through Temporal Cross-Attention to extract salient patterns. Comprehensive experiments on seven real-world benchmarks show that InA-Probe consistently outperforms state-of-the-art deep learning and LLM-based baselines, excelling in both one-for-all generalization and zero-shot transfer while reducing forecasting error by up to 37\% in challenging cross-domain scenarios. Ablation studies further confirm that the synergy between adaptive querying and fine-grained instructions is key to unlocking the reasoning power of LLMs for complex time series.
Physically-Constrained Mamba-SDE for Remaining Useful Life Prediction under Irregular Observations
Jun 01, 2026Accurate Remaining Useful Life prediction is critical for industrial predictive maintenance. However, real-world deployment is challenging due to the irregular nature of sensor observations, characterized by asynchronous sampling, burst missingness, and temporal jitter. Compounding this issue, purely data-driven models often generate physically implausible degradation trajectories that violate the irreversible nature of damage accumulation. To address this, we propose PC-MambaSDE, a unified continuous-time framework for robust RUL prediction under irregular observations. Specifically, we design a Mask-Aware Continuous Mamba Encoder that explicitly leverages observation masks to extract context-rich control signals. Furthermore, we introduce a Physics-Guided Latent SDE with parametrically rectified hybrid drift, superimposing a global physical bias to enforce monotonic degradation even amid severe observation gaps. Additionally, we formulate RUL prediction as a boundary value problem via a Terminal Degradation Penalty, which decouples a Health Index dimension and applies a penalty loss to guide trajectories toward the failure state. Theoretically, we prove that our variational objective is mathematically equivalent to minimizing the KL divergence via Girsanov's theorem, and we guarantee the global asymptotic stability of the learned dynamics through Lyapunov analysis. To enable rigorous evaluation, we develop a Hybrid Irregularity Generation Scheme that simulates realistic industrial imperfections. Extensive experiments on public benchmarks demonstrate that PC-MambaSDE significantly outperforms state-of-the-art methods, particularly under extreme observation scarcity, validating the efficacy of embedding physical priors into continuous-time latent dynamics.
DARE-EEG: A Foundation Model for Mining Dual-Aligned Representation of EEG
May 18, 2026Foundation models pre-trained through masked reconstruction on large-scale EEG data have emerged as a promising paradigm for learning generalizable neural representations across diverse brain-computer interface applications. However, a critical yet overlooked challenge is that EEG encoders must learn representations invariant to incomplete observations-when different masked views of the same signal have minimal overlap, existing methods fail to constrain them to a consistent latent subspace, leading to degraded transferability. To address this, we propose DARE-EEG, a self-supervised foundation model that explicitly enforces the mask-invariance property through dual-aligned representation learning during pre-training. Specifically, we introduce mask alignment that constrains representations from multiple masked views of the same EEG sample via contrastive learning, complementing anchor alignment that aligns masked representations to momentum-updated complete features for semantic stability. Additionally, we propose conv-linear-probing, a parameter-efficient strategy that adapts pre-trained representations to heterogeneous electrode configurations and sampling rates through decoupled spectro-spatial projections. Extensive experiments across diverse EEG benchmarks demonstrate that DARE-EEG consistently achieves state-of-the-art in accuracy performance while maintaining relatively low parameter complexity and superior cross-dataset portability compared to existing methods. Furthermore, DARE-EEG contributes to effectively discovering and utilizing the rich potential representations in EEG.
Multi-Level Bidirectional Biomimetic Learning for EEG-Based Visual Decoding
May 06, 2026EEG-based visual neural decoding aims to align neural responses with visual stimuli for tasks such as image retrieval. However, limited paired data and a fundamental mismatch between high-fidelity digital images and biological visual perception - distorted by retinotopic mapping and subject-specific neuroanatomy - severely impede cross-modal alignment. To address this, we propose MB2L, a Multi-Level Bidirectional Biomimetic Learning framework that incorporates structured physiological inductive biases into representation learning. Specifically, we propose Adaptive Blur with Visual Priors to mitigate perceptual-structural mismatch by reweighting visual inputs according to retinotopic priors. We further propose Biomimetic Visual Feature Extraction to learn multi-level visual representations consistent with hierarchical cortical processing, enhancing subject-invariant encoding. These modules are jointly optimized via Multi-level Bidirectional Contrastive Learning, which aligns EEG and visual features in a shared semantic space through bidirectional contrastive objectives. Experiments show MB2L achieves 80.5% Top-1 and 97.6% Top-5 accuracy on zero-shot EEG-to-image retrieval, significantly outperforming prior methods and demonstrating strong generalization across subjects and experimental settings.
Learn Like Humans: Use Meta-cognitive Reflection for Efficient Self-Improvement
Jan 17, 2026While Large Language Models (LLMs) enable complex autonomous behavior, current agents remain constrained by static, human-designed prompts that limit adaptability. Existing self-improving frameworks attempt to bridge this gap but typically rely on inefficient, multi-turn recursive loops that incur high computational costs. To address this, we propose Metacognitive Agent Reflective Self-improvement (MARS), a framework that achieves efficient self-evolution within a single recurrence cycle. Inspired by educational psychology, MARS mimics human learning by integrating principle-based reflection (abstracting normative rules to avoid errors) and procedural reflection (deriving step-by-step strategies for success). By synthesizing these insights into optimized instructions, MARS allows agents to systematically refine their reasoning logic without continuous online feedback. Extensive experiments on six benchmarks demonstrate that MARS outperforms state-of-the-art self-evolving systems while significantly reducing computational overhead.
Bridging Distribution Gaps in Time Series Foundation Model Pretraining with Prototype-Guided Normalization
Apr 15, 2025Foundation models have achieved remarkable success across diverse machine-learning domains through large-scale pretraining on large, diverse datasets. However, pretraining on such datasets introduces significant challenges due to substantial mismatches in data distributions, a problem particularly pronounced with time series data. In this paper, we tackle this issue by proposing a domain-aware adaptive normalization strategy within the Transformer architecture. Specifically, we replace the traditional LayerNorm with a prototype-guided dynamic normalization mechanism (ProtoNorm), where learned prototypes encapsulate distinct data distributions, and sample-to-prototype affinity determines the appropriate normalization layer. This mechanism effectively captures the heterogeneity of time series characteristics, aligning pretrained representations with downstream tasks. Through comprehensive empirical evaluation, we demonstrate that our method significantly outperforms conventional pretraining techniques across both classification and forecasting tasks, while effectively mitigating the adverse effects of distribution shifts during pretraining. Incorporating ProtoNorm is as simple as replacing a single line of code. Extensive experiments on diverse real-world time series benchmarks validate the robustness and generalizability of our approach, advancing the development of more versatile time series foundation models.
Augmented Contrastive Clustering with Uncertainty-Aware Prototyping for Time Series Test Time Adaptation
Jan 01, 2025



Test-time adaptation aims to adapt pre-trained deep neural networks using solely online unlabelled test data during inference. Although TTA has shown promise in visual applications, its potential in time series contexts remains largely unexplored. Existing TTA methods, originally designed for visual tasks, may not effectively handle the complex temporal dynamics of real-world time series data, resulting in suboptimal adaptation performance. To address this gap, we propose Augmented Contrastive Clustering with Uncertainty-aware Prototyping (ACCUP), a straightforward yet effective TTA method for time series data. Initially, our approach employs augmentation ensemble on the time series data to capture diverse temporal information and variations, incorporating uncertainty-aware prototypes to distill essential characteristics. Additionally, we introduce an entropy comparison scheme to selectively acquire more confident predictions, enhancing the reliability of pseudo labels. Furthermore, we utilize augmented contrastive clustering to enhance feature discriminability and mitigate error accumulation from noisy pseudo labels, promoting cohesive clustering within the same class while facilitating clear separation between different classes. Extensive experiments conducted on three real-world time series datasets and an additional visual dataset demonstrate the effectiveness and generalization potential of the proposed method, advancing the underexplored realm of TTA for time series data.
Temporal Source Recovery for Time-Series Source-Free Unsupervised Domain Adaptation
Sep 29, 2024Source-Free Unsupervised Domain Adaptation (SFUDA) has gained popularity for its ability to adapt pretrained models to target domains without accessing source domains, ensuring source data privacy. While SFUDA is well-developed in visual tasks, its application to Time-Series SFUDA (TS-SFUDA) remains limited due to the challenge of transferring crucial temporal dependencies across domains. Although a few researchers begin to explore this area, they rely on specific source domain designs, which are impractical as source data owners cannot be expected to follow particular pretraining protocols. To solve this, we propose Temporal Source Recovery (TemSR), a framework that transfers temporal dependencies for effective TS-SFUDA without requiring source-specific designs. TemSR features a recovery process that leverages masking, recovery, and optimization to generate a source-like distribution with recovered source temporal dependencies. To ensure effective recovery, we further design segment-based regularization to restore local dependencies and anchor-based recovery diversity maximization to enhance the diversity of the source-like distribution. The source-like distribution is then adapted to the target domain using traditional UDA techniques. Extensive experiments across multiple TS tasks demonstrate the effectiveness of TemSR, even surpassing existing TS-SFUDA method that requires source domain designs. Code is available in https://github.com/Frank-Wang-oss/TemSR.
Evidentially Calibrated Source-Free Time-Series Domain Adaptation with Temporal Imputation
Jun 04, 2024



Source-free domain adaptation (SFDA) aims to adapt a model pre-trained on a labeled source domain to an unlabeled target domain without access to source data, preserving the source domain's privacy. While SFDA is prevalent in computer vision, it remains largely unexplored in time series analysis. Existing SFDA methods, designed for visual data, struggle to capture the inherent temporal dynamics of time series, hindering adaptation performance. This paper proposes MAsk And imPUte (MAPU), a novel and effective approach for time series SFDA. MAPU addresses the critical challenge of temporal consistency by introducing a novel temporal imputation task. This task involves randomly masking time series signals and leveraging a dedicated temporal imputer to recover the original signal within the learned embedding space, bypassing the complexities of noisy raw data. Notably, MAPU is the first method to explicitly address temporal consistency in the context of time series SFDA. Additionally, it offers seamless integration with existing SFDA methods, providing greater flexibility. We further introduce E-MAPU, which incorporates evidential uncertainty estimation to address the overconfidence issue inherent in softmax predictions. To achieve that, we leverage evidential deep learning to obtain a better-calibrated pre-trained model and adapt the target encoder to map out-of-support target samples to a new feature representation closer to the source domain's support. This fosters better alignment, ultimately enhancing adaptation performance. Extensive experiments on five real-world time series datasets demonstrate that both MAPU and E-MAPU achieve significant performance gains compared to existing methods. These results highlight the effectiveness of our proposed approaches for tackling various time series domain adaptation problems.
CLIP-guided Source-free Object Detection in Aerial Images
Jan 10, 2024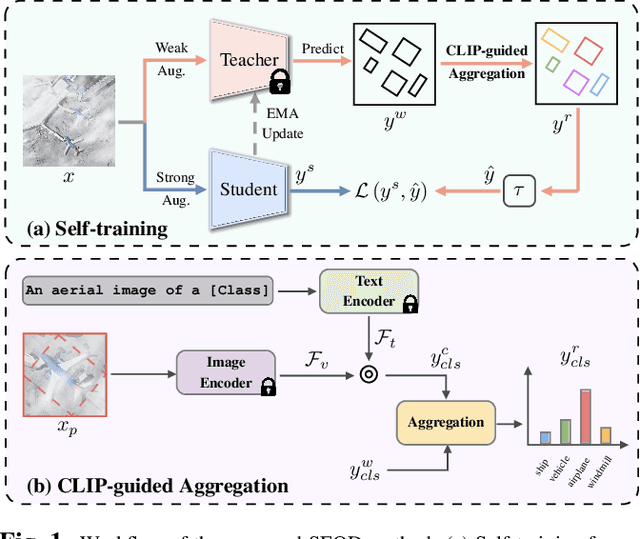
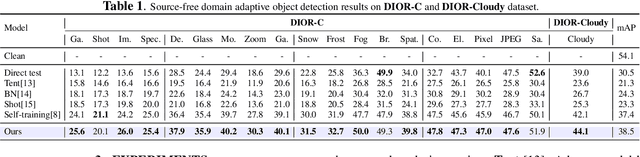
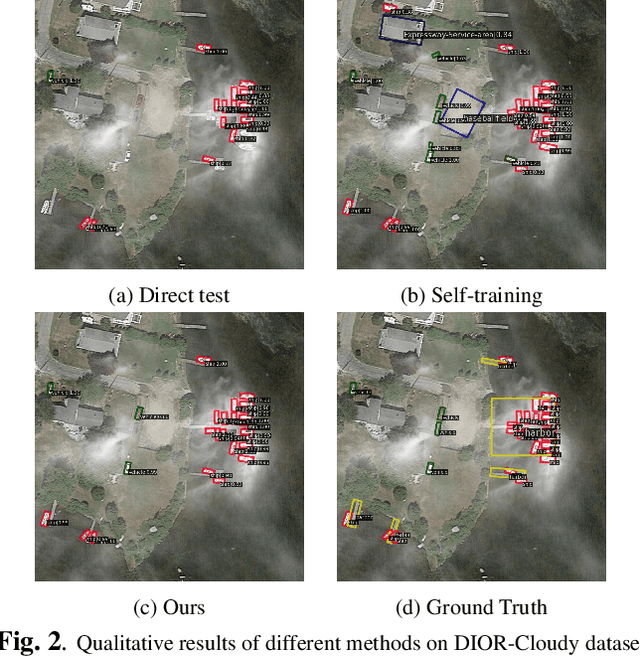
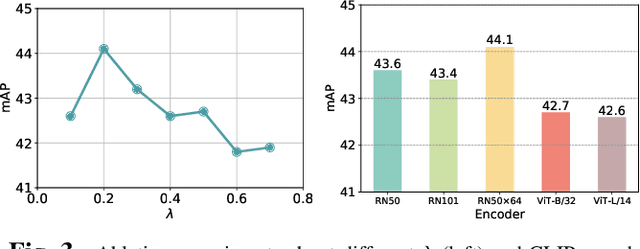
Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.