 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVHalluc: Benchmarking Speech-Vision Hallucination in Audio-Visual Large Language Models
May 31, 2026Despite the success of audio-visual large-language models (LLMs), they can produce plausible but ungrounded outputs, termed hallucination. Existing benchmarks focus on environmental sounds (e.g., dog barking) to indicate event occurrence. In contrast, human speech carries fundamentally different, rich semantics and temporal structures, yet it remains unexplored whether current models can accurately align speech content with corresponding visual signals. In this work, we show that speech content can induce hallucinations in audio-visual LLMs. To systematically study this, we introduce SVHalluc, the first comprehensive benchmark for evaluating speech-vision hallucination in audio-visual LLMs. Our benchmark diagnoses speech-vision hallucinations from two critical and complementary aspects: semantic and temporal. Experimental results demonstrate that state-of-the-art open-source audio-visual LLMs struggle with aligning speech content with corresponding visual signals, with a near-random accuracy on multiple tasks. In contrast, Gemini 2.5 Pro significantly outperforms the open-source models. Our analysis suggests that their failures stem from limited ability in cross-modality understanding, despite strong performance in single-modality perception. Our work uncovers a new and fundamental limitation of current audio-visual LLMs and highlights the need for speech-grounded video comprehension. Project page: https://chenshuang-zhang.github.io/projects/svhalluc/.
DRL-TH: Jointly Utilizing Temporal Graph Attention and Hierarchical Fusion for UGV Navigation in Crowded Environments
Dec 30, 2025Deep reinforcement learning (DRL) methods have demonstrated potential for autonomous navigation and obstacle avoidance of unmanned ground vehicles (UGVs) in crowded environments. Most existing approaches rely on single-frame observation and employ simple concatenation for multi-modal fusion, which limits their ability to capture temporal context and hinders dynamic adaptability. To address these challenges, we propose a DRL-based navigation framework, DRL-TH, which leverages temporal graph attention and hierarchical graph pooling to integrate historical observations and adaptively fuse multi-modal information. Specifically, we introduce a temporal-guided graph attention network (TG-GAT) that incorporates temporal weights into attention scores to capture correlations between consecutive frames, thereby enabling the implicit estimation of scene evolution. In addition, we design a graph hierarchical abstraction module (GHAM) that applies hierarchical pooling and learnable weighted fusion to dynamically integrate RGB and LiDAR features, achieving balanced representation across multiple scales. Extensive experiments demonstrate that our DRL-TH outperforms existing methods in various crowded environments. We also implemented DRL-TH control policy on a real UGV and showed that it performed well in real world scenarios.
CLIP-guided Source-free Object Detection in Aerial Images
Jan 10, 2024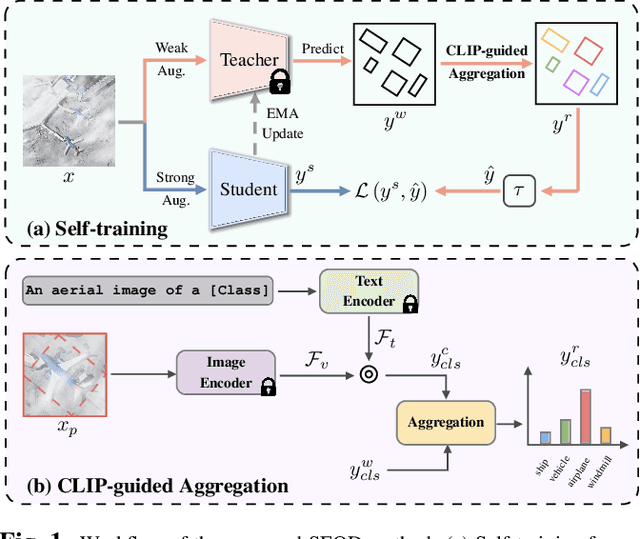
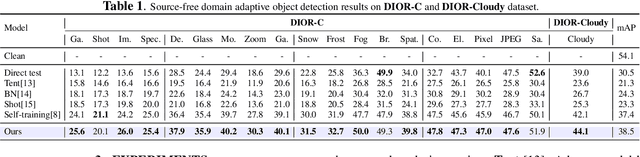
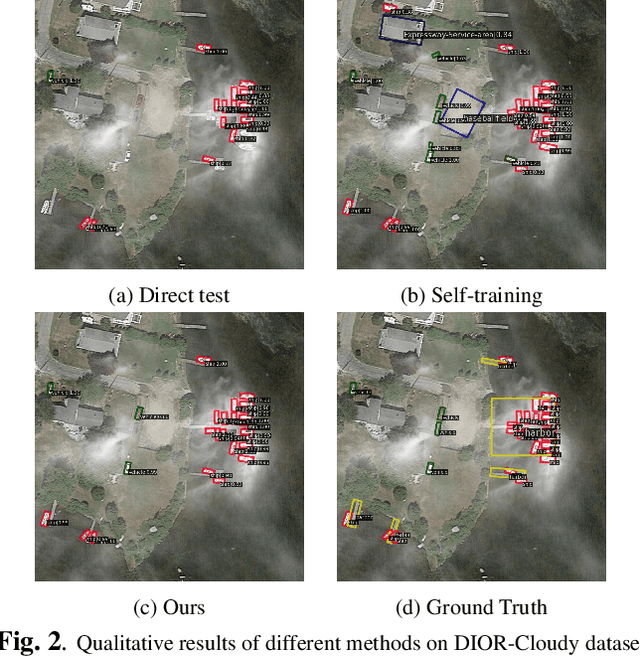
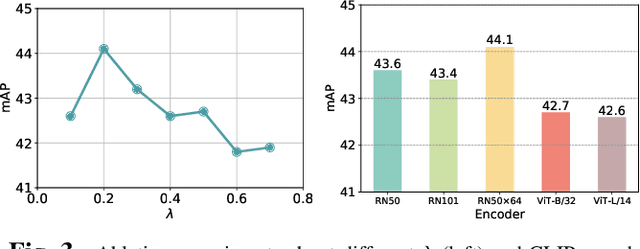
Domain adaptation is crucial in aerial imagery, as the visual representation of these images can significantly vary based on factors such as geographic location, time, and weather conditions. Additionally, high-resolution aerial images often require substantial storage space and may not be readily accessible to the public. To address these challenges, we propose a novel Source-Free Object Detection (SFOD) method. Specifically, our approach is built upon a self-training framework; however, self-training can lead to inaccurate learning in the absence of labeled training data. To address this issue, we further integrate Contrastive Language-Image Pre-training (CLIP) to guide the generation of pseudo-labels, termed CLIP-guided Aggregation. By leveraging CLIP's zero-shot classification capability, we use it to aggregate scores with the original predicted bounding boxes, enabling us to obtain refined scores for the pseudo-labels. To validate the effectiveness of our method, we constructed two new datasets from different domains based on the DIOR dataset, named DIOR-C and DIOR-Cloudy. Experiments demonstrate that our method outperforms other comparative algorithms.
Point-Query Quadtree for Crowd Counting, Localization, and More
Aug 26, 2023
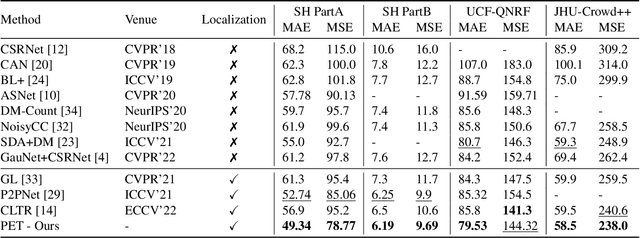


We show that crowd counting can be viewed as a decomposable point querying process. This formulation enables arbitrary points as input and jointly reasons whether the points are crowd and where they locate. The querying processing, however, raises an underlying problem on the number of necessary querying points. Too few imply underestimation; too many increase computational overhead. To address this dilemma, we introduce a decomposable structure, i.e., the point-query quadtree, and propose a new counting model, termed Point quEry Transformer (PET). PET implements decomposable point querying via data-dependent quadtree splitting, where each querying point could split into four new points when necessary, thus enabling dynamic processing of sparse and dense regions. Such a querying process yields an intuitive, universal modeling of crowd as both the input and output are interpretable and steerable. We demonstrate the applications of PET on a number of crowd-related tasks, including fully-supervised crowd counting and localization, partial annotation learning, and point annotation refinement, and also report state-of-the-art performance. For the first time, we show that a single counting model can address multiple crowd-related tasks across different learning paradigms. Code is available at https://github.com/cxliu0/PET.
Robust Object Detection With Inaccurate Bounding Boxes
Jul 20, 2022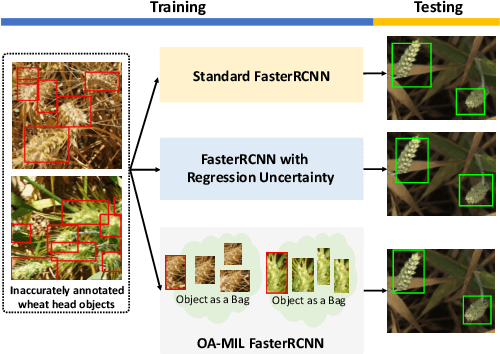
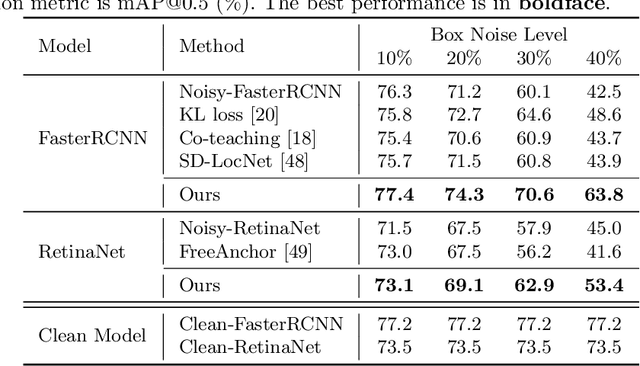
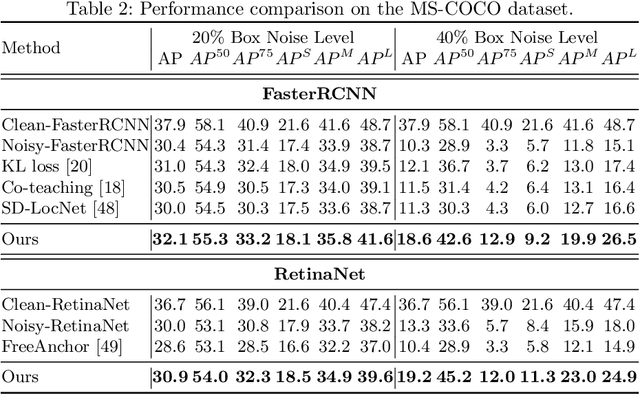
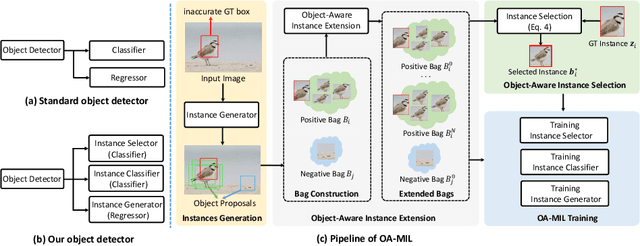
Learning accurate object detectors often requires large-scale training data with precise object bounding boxes. However, labeling such data is expensive and time-consuming. As the crowd-sourcing labeling process and the ambiguities of the objects may raise noisy bounding box annotations, the object detectors will suffer from the degenerated training data. In this work, we aim to address the challenge of learning robust object detectors with inaccurate bounding boxes. Inspired by the fact that localization precision suffers significantly from inaccurate bounding boxes while classification accuracy is less affected, we propose leveraging classification as a guidance signal for refining localization results. Specifically, by treating an object as a bag of instances, we introduce an Object-Aware Multiple Instance Learning approach (OA-MIL), featured with object-aware instance selection and object-aware instance extension. The former aims to select accurate instances for training, instead of directly using inaccurate box annotations. The latter focuses on generating high-quality instances for selection. Extensive experiments on synthetic noisy datasets (i.e., noisy PASCAL VOC and MS-COCO) and a real noisy wheat head dataset demonstrate the effectiveness of our OA-MIL. Code is available at https://github.com/cxliu0/OA-MIL.
Represent, Compare, and Learn: A Similarity-Aware Framework for Class-Agnostic Counting
Mar 16, 2022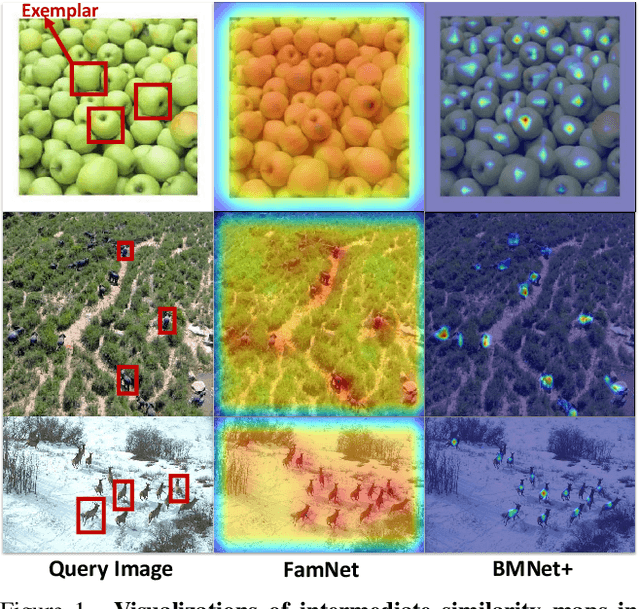
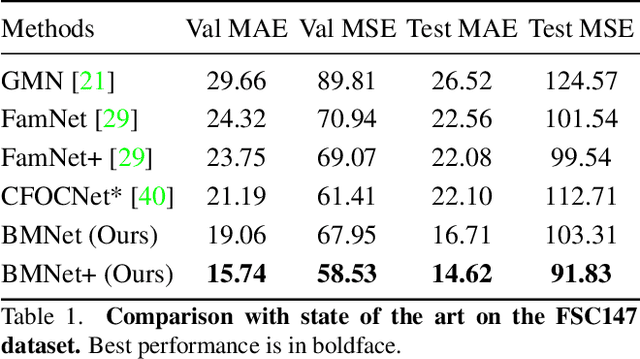
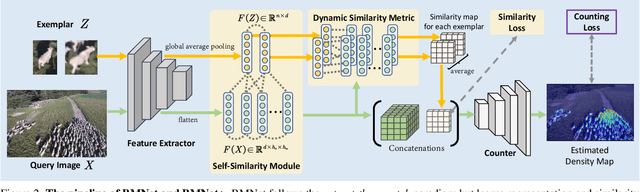
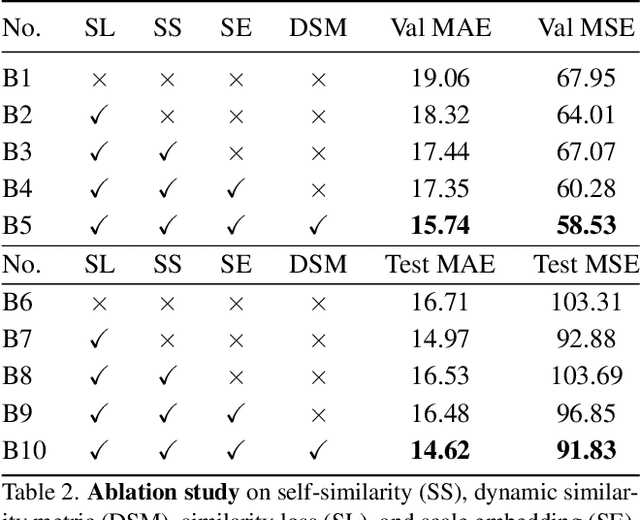
Class-agnostic counting (CAC) aims to count all instances in a query image given few exemplars. A standard pipeline is to extract visual features from exemplars and match them with query images to infer object counts. Two essential components in this pipeline are feature representation and similarity metric. Existing methods either adopt a pretrained network to represent features or learn a new one, while applying a naive similarity metric with fixed inner product. We find this paradigm leads to noisy similarity matching and hence harms counting performance. In this work, we propose a similarity-aware CAC framework that jointly learns representation and similarity metric. We first instantiate our framework with a naive baseline called Bilinear Matching Network (BMNet), whose key component is a learnable bilinear similarity metric. To further embody the core of our framework, we extend BMNet to BMNet+ that models similarity from three aspects: 1) representing the instances via their self-similarity to enhance feature robustness against intra-class variations; 2) comparing the similarity dynamically to focus on the key patterns of each exemplar; 3) learning from a supervision signal to impose explicit constraints on matching results. Extensive experiments on a recent CAC dataset FSC147 show that our models significantly outperform state-of-the-art CAC approaches. In addition, we also validate the cross-dataset generality of BMNet and BMNet+ on a car counting dataset CARPK. Code is at tiny.one/BMNet
From Open Set to Closed Set: Supervised Spatial Divide-and-Conquer for Object Counting
Jan 07, 2020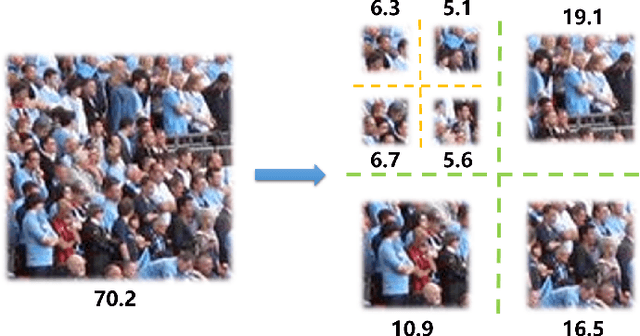

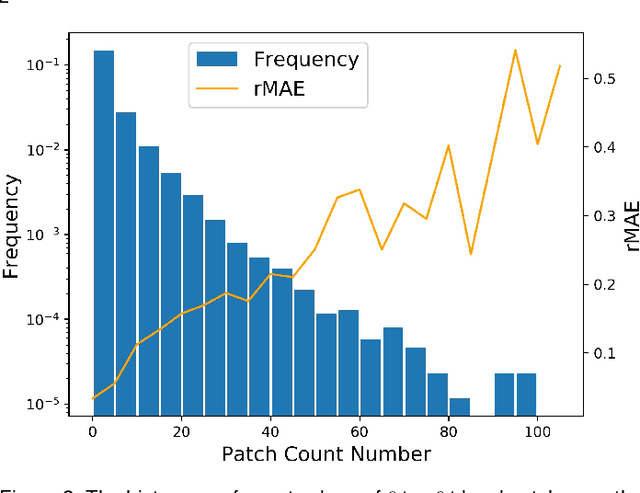
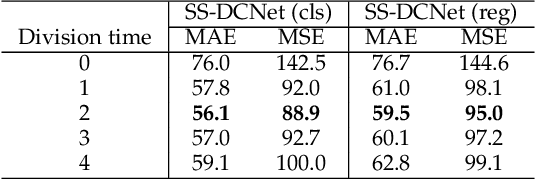
Visual counting, a task that aims to estimate the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in [0, inf) in theory. However, collected data and labeled instances are limited in reality, which means that only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are prone to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting has an interesting and exclusive property---spatially decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. We therefore introduce the idea of spatial divide-and-conquer (S-DC) that transforms open-set counting into a closed-set problem. This idea is implemented by a novel Supervised Spatial Divide-and-Conquer Network (SS-DCNet). Thus, SS-DCNet can only learn from a closed set but generalize well to open-set scenarios via S-DC. SS-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. We provide theoretical analyses as well as a controlled experiment on toy data, demonstrating why closed-set modeling makes sense. Extensive experiments show that SS-DCNet achieves the state-of-the-art performance. Code and models are available at: https://tinyurl.com/SS-DCNet.
From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer
Aug 15, 2019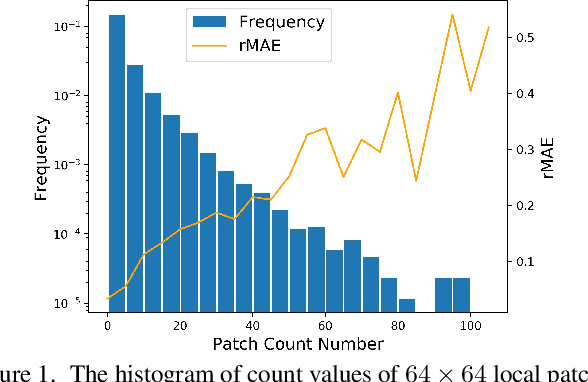

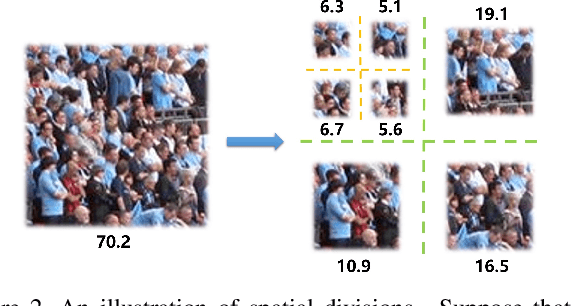

Visual counting, a task that predicts the number of objects from an image/video, is an open-set problem by nature, i.e., the number of population can vary in $[0,+\infty)$ in theory. However, the collected images and labeled count values are limited in reality, which means only a small closed set is observed. Existing methods typically model this task in a regression manner, while they are likely to suffer from an unseen scene with counts out of the scope of the closed set. In fact, counting is decomposable. A dense region can always be divided until sub-region counts are within the previously observed closed set. Inspired by this idea, we propose a simple but effective approach, Spatial Divide-and- Conquer Network (S-DCNet). S-DCNet only learns from a closed set but can generalize well to open-set scenarios via S-DC. S-DCNet is also efficient. To avoid repeatedly computing sub-region convolutional features, S-DC is executed on the feature map instead of on the input image. S-DCNet achieves the state-of-the-art performance on three crowd counting datasets (ShanghaiTech, UCF_CC_50 and UCF-QNRF), a vehicle counting dataset (TRANCOS) and a plant counting dataset (MTC). Compared to the previous best methods, S-DCNet brings a 20.2% relative improvement on the ShanghaiTech Part B, 20.9% on the UCF-QNRF, 22.5% on the TRANCOS and 15.1% on the MTC. Code has been made available at: https://github. com/xhp-hust-2018-2011/S-DCNet.