 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Human-Centric AI Requires a Minimum Viable Level of Human Understanding
Jan 31, 2026AI systems increasingly produce fluent, correct, end-to-end outcomes. Over time, this erodes users' ability to explain, verify, or intervene. We define this divergence as the Capability-Comprehension Gap: a decoupling where assisted performance improves while users' internal models deteriorate. This paper argues that prevailing approaches to transparency, user control, literacy, and governance do not define the foundational understanding humans must retain for oversight under sustained AI delegation. To formalize this, we define the Cognitive Integrity Threshold (CIT) as the minimum comprehension required to preserve oversight, autonomy, and accountable participation under AI assistance. CIT does not require full reasoning reconstruction, nor does it constrain automation. It identifies the threshold beyond which oversight becomes procedural and contestability fails. We operatinalize CIT through three functional dimensions: (i) verification capacity, (ii) comprehension-preserving interaction, and (iii) institutional scaffolds for governance. This motivates a design and governance agenda that aligns human-AI interaction with cognitive sustainability in responsibility-critical settings.
A Language Anchor-Guided Method for Robust Noisy Domain Generalization
Mar 21, 2025Real-world machine learning applications often struggle with two major challenges: distribution shift and label noise. Models tend to overfit by focusing on redundant and uninformative features in the training data, which makes it hard for them to generalize to the target domain. Noisy data worsens this problem by causing further overfitting to the noise, meaning that existing methods often fail to tell the difference between true, invariant features and misleading, spurious ones. To tackle these issues, we introduce Anchor Alignment and Adaptive Weighting (A3W). This new algorithm uses sample reweighting guided by natural language processing (NLP) anchors to extract more representative features. In simple terms, A3W leverages semantic representations from natural language models as a source of domain-invariant prior knowledge. Additionally, it employs a weighted loss function that adjusts each sample's contribution based on its similarity to the corresponding NLP anchor. This adjustment makes the model more robust to noisy labels. Extensive experiments on standard benchmark datasets show that A3W consistently outperforms state-of-the-art domain generalization methods, offering significant improvements in both accuracy and robustness across different datasets and noise levels.
Hyperbolic Chamfer Distance for Point Cloud Completion and Beyond
Dec 23, 2024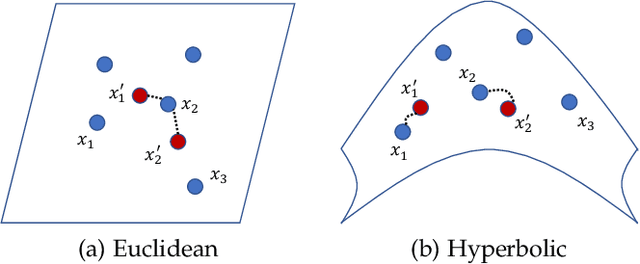
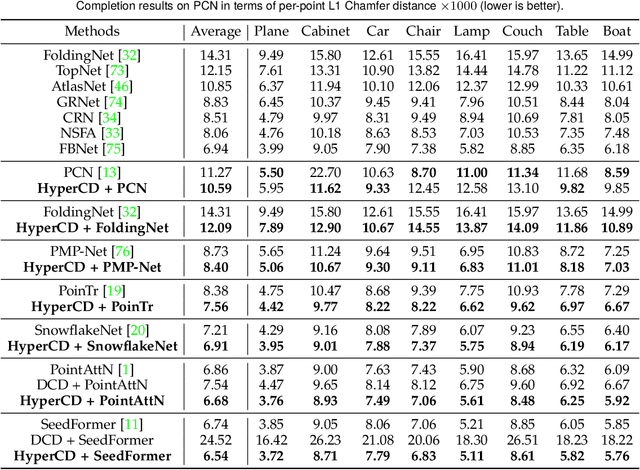
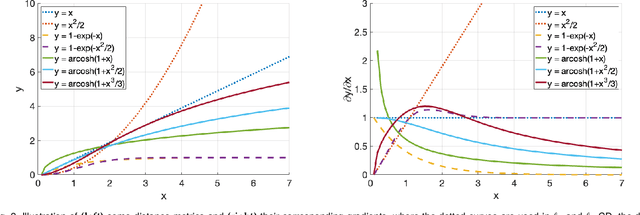
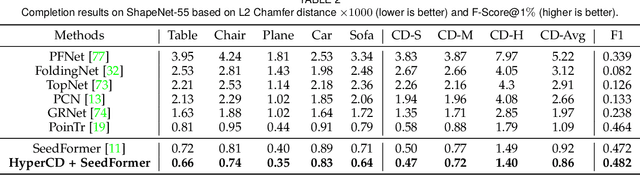
Chamfer Distance (CD) is widely used as a metric to quantify difference between two point clouds. In point cloud completion, Chamfer Distance (CD) is typically used as a loss function in deep learning frameworks. However, it is generally acknowledged within the field that Chamfer Distance (CD) is vulnerable to the presence of outliers, which can consequently lead to the convergence on suboptimal models. In divergence from the existing literature, which largely concentrates on resolving such concerns in the realm of Euclidean space, we put forth a notably uncomplicated yet potent metric specifically designed for point cloud completion tasks: {Hyperbolic Chamfer Distance (HyperCD)}. This metric conducts Chamfer Distance computations within the parameters of hyperbolic space. During the backpropagation process, HyperCD systematically allocates greater weight to matched point pairs exhibiting reduced Euclidean distances. This mechanism facilitates the preservation of accurate point pair matches while permitting the incremental adjustment of suboptimal matches, thereby contributing to enhanced point cloud completion outcomes. Moreover, measure the shape dissimilarity is not solely work for point cloud completion task, we further explore its applications in other generative related tasks, including single image reconstruction from point cloud, and upsampling. We demonstrate state-of-the-art performance on the point cloud completion benchmark datasets, PCN, ShapeNet-55, and ShapeNet-34, and show from visualization that HyperCD can significantly improve the surface smoothness, we also provide the provide experimental results beyond completion task.
SPADE: Spectroscopic Photoacoustic Denoising using an Analytical and Data-free Enhancement Framework
Dec 16, 2024



Spectroscopic photoacoustic (sPA) imaging uses multiple wavelengths to differentiate chromophores based on their unique optical absorption spectra. This technique has been widely applied in areas such as vascular mapping, tumor detection, and therapeutic monitoring. However, sPA imaging is highly susceptible to noise, leading to poor signal-to-noise ratio (SNR) and compromised image quality. Traditional denoising techniques like frame averaging, though effective in improving SNR, can be impractical for dynamic imaging scenarios due to reduced frame rates. Advanced methods, including learning-based approaches and analytical algorithms, have demonstrated promise but often require extensive training data and parameter tuning, limiting their adaptability for real-time clinical use. In this work, we propose a sPA denoising using a tuning-free analytical and data-free enhancement (SPADE) framework for denoising sPA images. This framework integrates a data-free learning-based method with an efficient BM3D-based analytical approach while preserves spectral linearity, providing noise reduction and ensuring that functional information is maintained. The SPADE framework was validated through simulation, phantom, ex vivo, and in vivo experiments. Results demonstrated that SPADE improved SNR and preserved spectral information, outperforming conventional methods, especially in challenging imaging conditions. SPADE presents a promising solution for enhancing sPA imaging quality in clinical applications where noise reduction and spectral preservation are critical.
Deep Loss Convexification for Learning Iterative Models
Nov 16, 2024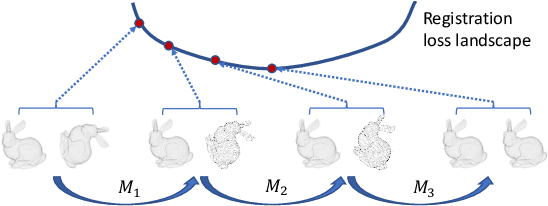
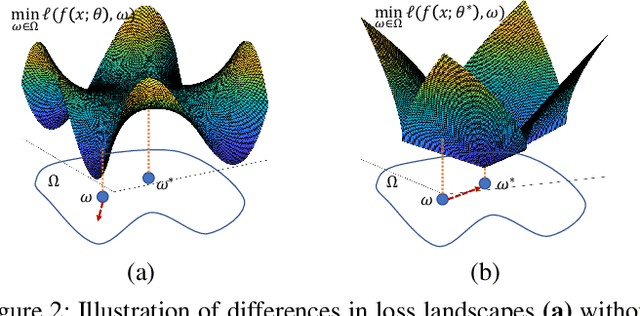
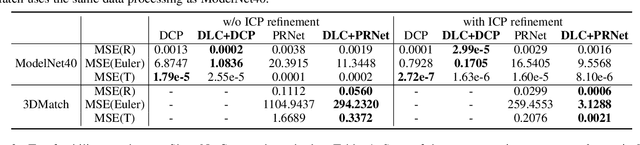
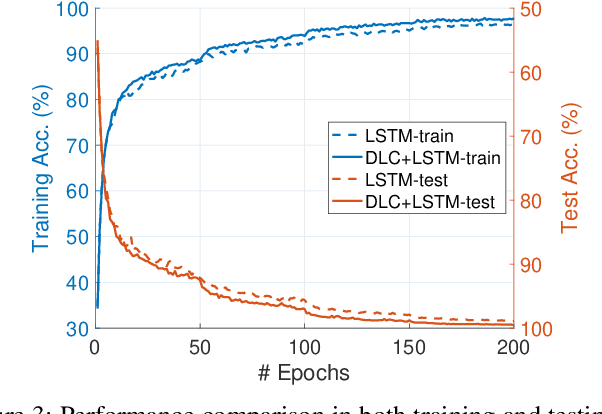
Iterative methods such as iterative closest point (ICP) for point cloud registration often suffer from bad local optimality (e.g. saddle points), due to the nature of nonconvex optimization. To address this fundamental challenge, in this paper we propose learning to form the loss landscape of a deep iterative method w.r.t. predictions at test time into a convex-like shape locally around each ground truth given data, namely Deep Loss Convexification (DLC), thanks to the overparametrization in neural networks. To this end, we formulate our learning objective based on adversarial training by manipulating the ground-truth predictions, rather than input data. In particular, we propose using star-convexity, a family of structured nonconvex functions that are unimodal on all lines that pass through a global minimizer, as our geometric constraint for reshaping loss landscapes, leading to (1) extra novel hinge losses appended to the original loss and (2) near-optimal predictions. We demonstrate the state-of-the-art performance using DLC with existing network architectures for the tasks of training recurrent neural networks (RNNs), 3D point cloud registration, and multimodel image alignment.
Robust 3D Point Clouds Classification based on Declarative Defenders
Oct 13, 2024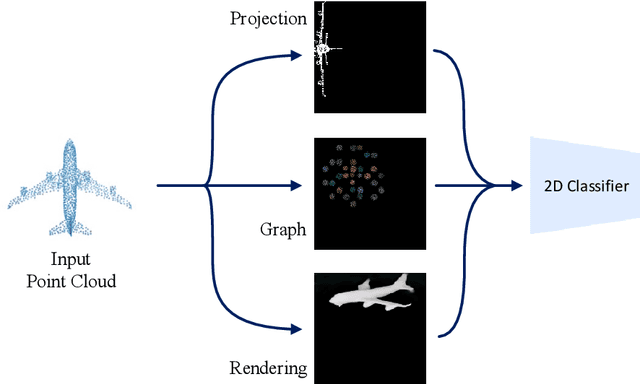



3D point cloud classification requires distinct models from 2D image classification due to the divergent characteristics of the respective input data. While 3D point clouds are unstructured and sparse, 2D images are structured and dense. Bridging the domain gap between these two data types is a non-trivial challenge to enable model interchangeability. Recent research using Lattice Point Classifier (LPC) highlights the feasibility of cross-domain applicability. However, the lattice projection operation in LPC generates 2D images with disconnected projected pixels. In this paper, we explore three distinct algorithms for mapping 3D point clouds into 2D images. Through extensive experiments, we thoroughly examine and analyze their performance and defense mechanisms. Leveraging current large foundation models, we scrutinize the feature disparities between regular 2D images and projected 2D images. The proposed approaches demonstrate superior accuracy and robustness against adversarial attacks. The generative model-based mapping algorithms yield regular 2D images, further minimizing the domain gap from regular 2D classification tasks. The source code is available at https://github.com/KaidongLi/pytorch-LatticePointClassifier.git.
Wildlife Product Trading in Online Social Networks: A Case Study on Ivory-Related Product Sales Promotion Posts
Sep 25, 2024
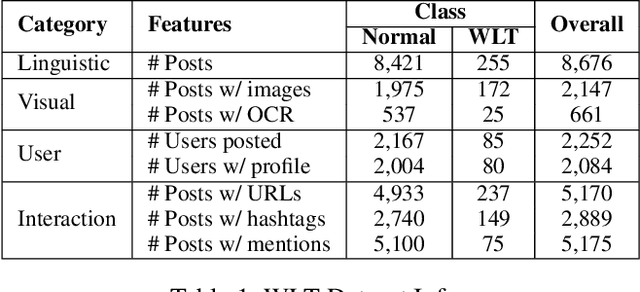
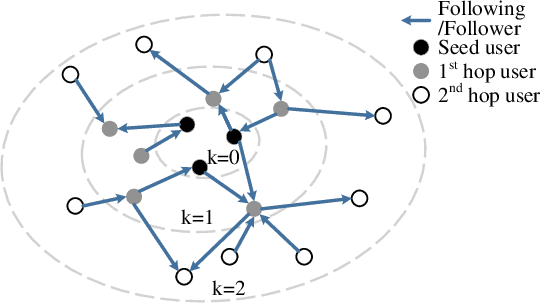
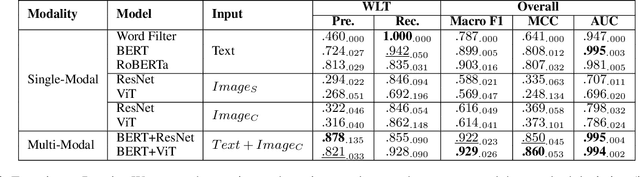
Wildlife trafficking (WLT) has emerged as a global issue, with traffickers expanding their operations from offline to online platforms, utilizing e-commerce websites and social networks to enhance their illicit trade. This paper addresses the challenge of detecting and recognizing wildlife product sales promotion behaviors in online social networks, a crucial aspect in combating these environmentally harmful activities. To counter these environmentally damaging illegal operations, in this research, we focus on wildlife product sales promotion behaviors in online social networks. Specifically, 1) A scalable dataset related to wildlife product trading is collected using a network-based approach. This dataset is labeled through a human-in-the-loop machine learning process, distinguishing positive class samples containing wildlife product selling posts and hard-negatives representing normal posts misclassified as potential WLT posts, subsequently corrected by human annotators. 2) We benchmark the machine learning results on the proposed dataset and build a practical framework that automatically identifies suspicious wildlife selling posts and accounts, sufficiently leveraging the multi-modal nature of online social networks. 3) This research delves into an in-depth analysis of trading posts, shedding light on the systematic and organized selling behaviors prevalent in the current landscape. We provide detailed insights into the nature of these behaviors, contributing valuable information for understanding and countering illegal wildlife product trading.
* ICWSM 2024
Loss Distillation via Gradient Matching for Point Cloud Completion with Weighted Chamfer Distance
Sep 10, 2024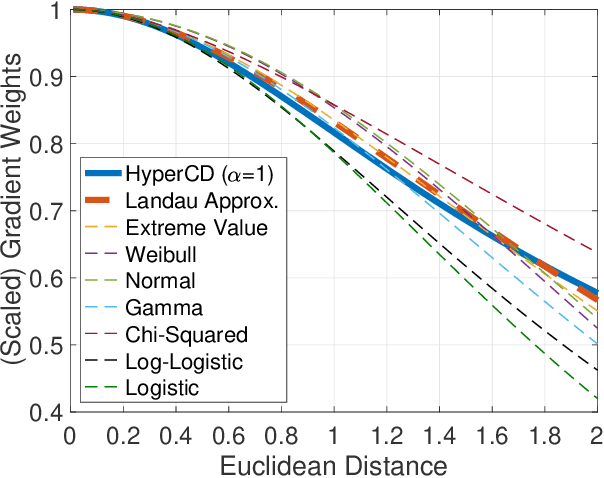
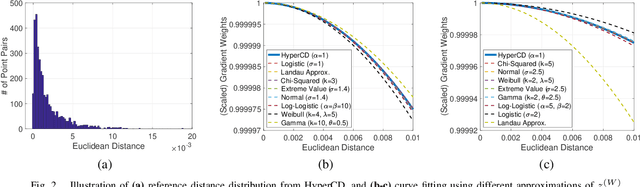


3D point clouds enhanced the robot's ability to perceive the geometrical information of the environments, making it possible for many downstream tasks such as grasp pose detection and scene understanding. The performance of these tasks, though, heavily relies on the quality of data input, as incomplete can lead to poor results and failure cases. Recent training loss functions designed for deep learning-based point cloud completion, such as Chamfer distance (CD) and its variants (\eg HyperCD ), imply a good gradient weighting scheme can significantly boost performance. However, these CD-based loss functions usually require data-related parameter tuning, which can be time-consuming for data-extensive tasks. To address this issue, we aim to find a family of weighted training losses ({\em weighted CD}) that requires no parameter tuning. To this end, we propose a search scheme, {\em Loss Distillation via Gradient Matching}, to find good candidate loss functions by mimicking the learning behavior in backpropagation between HyperCD and weighted CD. Once this is done, we propose a novel bilevel optimization formula to train the backbone network based on the weighted CD loss. We observe that: (1) with proper weighted functions, the weighted CD can always achieve similar performance to HyperCD, and (2) the Landau weighted CD, namely {\em Landau CD}, can outperform HyperCD for point cloud completion and lead to new state-of-the-art results on several benchmark datasets. {\it Our demo code is available at \url{https://github.com/Zhang-VISLab/IROS2024-LossDistillationWeightedCD}.}
Guiding the Last Centimeter: Novel Anatomy-Aware Probe Servoing for Standardized Imaging Plane Navigation in Robotic Lung Ultrasound
Jun 17, 2024Navigating the ultrasound (US) probe to the standardized imaging plane (SIP) for image acquisition is a critical but operator-dependent task in conventional freehand diagnostic US. Robotic US systems (RUSS) offer the potential to enhance imaging consistency by leveraging real-time US image feedback to optimize the probe pose, thereby reducing reliance on operator expertise. However, determining the proper approach to extracting generalizable features from the US images for probe pose adjustment remain challenging. In this work, we propose a SIP navigation framework for RUSS, exemplified in the context of robotic lung ultrasound (LUS). This framework facilitates automatic probe adjustment when in proximity to the SIP. This is achieved by explicitly extracting multiple anatomical features presented in real-time LUS images and performing non-patient-specific template matching to generate probe motion towards the SIP using image-based visual servoing (IBVS). This framework is further integrated with the active-sensing end-effector (A-SEE), a customized robot end-effector that leverages patient external body geometry to maintain optimal probe alignment with the contact surface, thus preserving US signal quality throughout the navigation. The proposed approach ensures procedural interpretability and inter-patient adaptability. Validation is conducted through anatomy-mimicking phantom and in-vivo evaluations involving five human subjects. The results show the framework's high navigation precision with the probe correctly located at the SIP for all cases, exhibiting positioning error of under 2 mm in translation and under 2 degree in rotation. These results demonstrate the navigation process's capability to accomondate anatomical variations among patients.
Understanding Hyperbolic Metric Learning through Hard Negative Sampling
Apr 23, 2024In recent years, there has been a growing trend of incorporating hyperbolic geometry methods into computer vision. While these methods have achieved state-of-the-art performance on various metric learning tasks using hyperbolic distance measurements, the underlying theoretical analysis supporting this superior performance remains under-exploited. In this study, we investigate the effects of integrating hyperbolic space into metric learning, particularly when training with contrastive loss. We identify a need for a comprehensive comparison between Euclidean and hyperbolic spaces regarding the temperature effect in the contrastive loss within the existing literature. To address this gap, we conduct an extensive investigation to benchmark the results of Vision Transformers (ViTs) using a hybrid objective function that combines loss from Euclidean and hyperbolic spaces. Additionally, we provide a theoretical analysis of the observed performance improvement. We also reveal that hyperbolic metric learning is highly related to hard negative sampling, providing insights for future work. This work will provide valuable data points and experience in understanding hyperbolic image embeddings. To shed more light on problem-solving and encourage further investigation into our approach, our code is available online (https://github.com/YunYunY/HypMix).