 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePubMed Reasoner: Dynamic Reasoning-based Retrieval for Evidence-Grounded Biomedical Question Answering
Mar 28, 2026Trustworthy biomedical question answering (QA) systems must not only provide accurate answers but also justify them with current, verifiable evidence. Retrieval-augmented approaches partially address this gap but lack mechanisms to iteratively refine poor queries, whereas self-reflection methods kick in only after full retrieval is completed. In this context, we introduce PubMed Reasoner, a biomedical QA agent composed of three stages: self-critic query refinement evaluates MeSH terms for coverage, alignment, and redundancy to enhance PubMed queries based on partial (metadata) retrieval; reflective retrieval processes articles in batches until sufficient evidence is gathered; and evidence-grounded response generation produces answers with explicit citations. PubMed Reasoner with a GPT-4o backbone achieves 78.32% accuracy on PubMedQA, slightly surpassing human experts, and showing consistent gains on MMLU Clinical Knowledge. Moreover, LLM-as-judge evaluations prefer our responses across: reasoning soundness, evidence grounding, clinical relevance, and trustworthiness. By orchestrating retrieval-first reasoning over authoritative sources, our approach provides practical assistance to clinicians and biomedical researchers while controlling compute and token costs.
CLaDMoP: Learning Transferrable Models from Successful Clinical Trials via LLMs
May 24, 2025Many existing models for clinical trial outcome prediction are optimized using task-specific loss functions on trial phase-specific data. While this scheme may boost prediction for common diseases and drugs, it can hinder learning of generalizable representations, leading to more false positives/negatives. To address this limitation, we introduce CLaDMoP, a new pre-training approach for clinical trial outcome prediction, alongside the Successful Clinical Trials dataset(SCT), specifically designed for this task. CLaDMoP leverages a Large Language Model-to encode trials' eligibility criteria-linked to a lightweight Drug-Molecule branch through a novel multi-level fusion technique. To efficiently fuse long embeddings across levels, we incorporate a grouping block, drastically reducing computational overhead. CLaDMoP avoids reliance on task-specific objectives by pre-training on a "pair matching" proxy task. Compared to established zero-shot and few-shot baselines, our method significantly improves both PR-AUC and ROC-AUC, especially for phase I and phase II trials. We further evaluate and perform ablation on CLaDMoP after Parameter-Efficient Fine-Tuning, comparing it to state-of-the-art supervised baselines, including MEXA-CTP, on the Trial Outcome Prediction(TOP) benchmark. CLaDMoP achieves up to 10.5% improvement in PR-AUC and 3.6% in ROC-AUC, while attaining comparable F1 score to MEXA-CTP, highlighting its potential for clinical trial outcome prediction. Code and SCT dataset can be downloaded from https://github.com/murai-lab/CLaDMoP.
MEXA-CTP: Mode Experts Cross-Attention for Clinical Trial Outcome Prediction
Jan 12, 2025Clinical trials are the gold standard for assessing the effectiveness and safety of drugs for treating diseases. Given the vast design space of drug molecules, elevated financial cost, and multi-year timeline of these trials, research on clinical trial outcome prediction has gained immense traction. Accurate predictions must leverage data of diverse modes such as drug molecules, target diseases, and eligibility criteria to infer successes and failures. Previous Deep Learning approaches for this task, such as HINT, often require wet lab data from synthesized molecules and/or rely on prior knowledge to encode interactions as part of the model architecture. To address these limitations, we propose a light-weight attention-based model, MEXA-CTP, to integrate readily-available multi-modal data and generate effective representations via specialized modules dubbed "mode experts", while avoiding human biases in model design. We optimize MEXA-CTP with the Cauchy loss to capture relevant interactions across modes. Our experiments on the Trial Outcome Prediction (TOP) benchmark demonstrate that MEXA-CTP improves upon existing approaches by, respectively, up to 11.3% in F1 score, 12.2% in PR-AUC, and 2.5% in ROC-AUC, compared to HINT. Ablation studies are provided to quantify the effectiveness of each component in our proposed method.
Deep Loss Convexification for Learning Iterative Models
Nov 16, 2024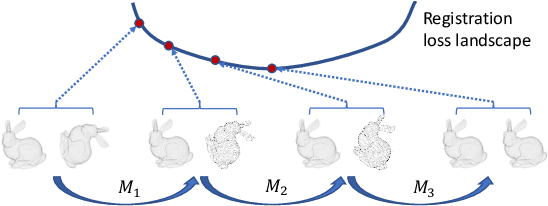
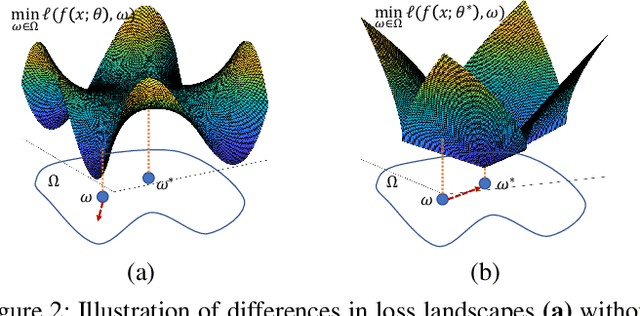
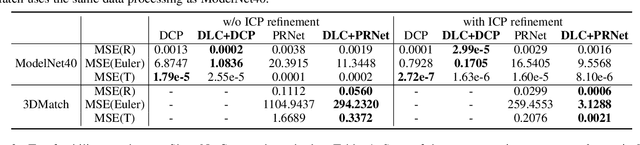
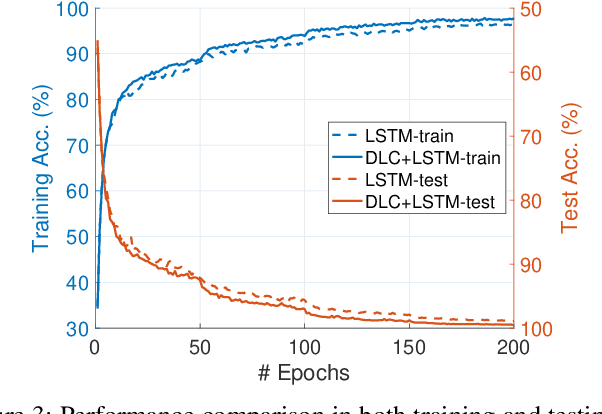
Iterative methods such as iterative closest point (ICP) for point cloud registration often suffer from bad local optimality (e.g. saddle points), due to the nature of nonconvex optimization. To address this fundamental challenge, in this paper we propose learning to form the loss landscape of a deep iterative method w.r.t. predictions at test time into a convex-like shape locally around each ground truth given data, namely Deep Loss Convexification (DLC), thanks to the overparametrization in neural networks. To this end, we formulate our learning objective based on adversarial training by manipulating the ground-truth predictions, rather than input data. In particular, we propose using star-convexity, a family of structured nonconvex functions that are unimodal on all lines that pass through a global minimizer, as our geometric constraint for reshaping loss landscapes, leading to (1) extra novel hinge losses appended to the original loss and (2) near-optimal predictions. We demonstrate the state-of-the-art performance using DLC with existing network architectures for the tasks of training recurrent neural networks (RNNs), 3D point cloud registration, and multimodel image alignment.
PRISE: Demystifying Deep Lucas-Kanade with Strongly Star-Convex Constraints for Multimodel Image Alignment
Mar 21, 2023The Lucas-Kanade (LK) method is a classic iterative homography estimation algorithm for image alignment, but often suffers from poor local optimality especially when image pairs have large distortions. To address this challenge, in this paper we propose a novel Deep Star-Convexified Lucas-Kanade (PRISE) method for multimodel image alignment by introducing strongly star-convex constraints into the optimization problem. Our basic idea is to enforce the neural network to approximately learn a star-convex loss landscape around the ground truth give any data to facilitate the convergence of the LK method to the ground truth through the high dimensional space defined by the network. This leads to a minimax learning problem, with contrastive (hinge) losses due to the definition of strong star-convexity that are appended to the original loss for training. We also provide an efficient sampling based algorithm to leverage the training cost, as well as some analysis on the quality of the solutions from PRISE. We further evaluate our approach on benchmark datasets such as MSCOCO, GoogleEarth, and GoogleMap, and demonstrate state-of-the-art results, especially for small pixel errors. Code can be downloaded from https://github.com/Zhang-VISLab.
Composing Answer from Multi-spans for Reading Comprehension
Sep 14, 2020

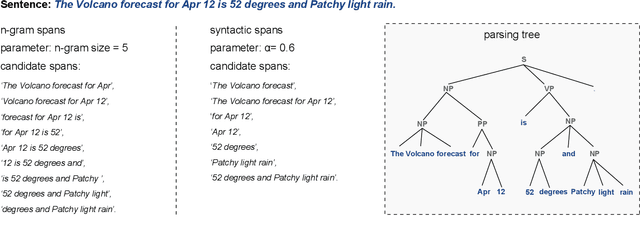
This paper presents a novel method to generate answers for non-extraction machine reading comprehension (MRC) tasks whose answers cannot be simply extracted as one span from the given passages. Using a pointer network-style extractive decoder for such type of MRC may result in unsatisfactory performance when the ground-truth answers are given by human annotators or highly re-paraphrased from parts of the passages. On the other hand, using generative decoder cannot well guarantee the resulted answers with well-formed syntax and semantics when encountering long sentences. Therefore, to alleviate the obvious drawbacks of both sides, we propose an answer making-up method from extracted multi-spans that are learned by our model as highly confident $n$-gram candidates in the given passage. That is, the returned answers are composed of discontinuous multi-spans but not just one consecutive span in the given passages anymore. The proposed method is simple but effective: empirical experiments on MS MARCO show that the proposed method has a better performance on accurately generating long answers, and substantially outperforms two competitive typical one-span and Seq2Seq baseline decoders.
Dependency or Span, End-to-End Uniform Semantic Role Labeling
Jan 16, 2019
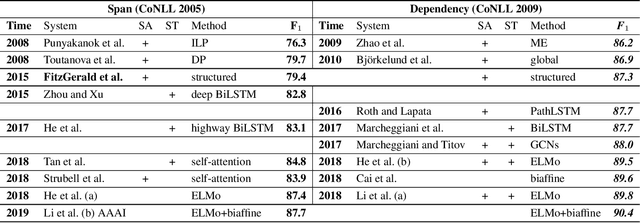
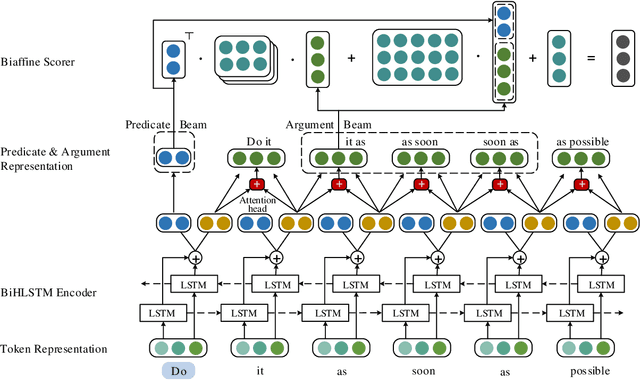
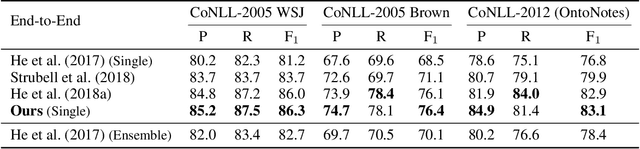
Semantic role labeling (SRL) aims to discover the predicateargument structure of a sentence. End-to-end SRL without syntactic input has received great attention. However, most of them focus on either span-based or dependency-based semantic representation form and only show specific model optimization respectively. Meanwhile, handling these two SRL tasks uniformly was less successful. This paper presents an end-to-end model for both dependency and span SRL with a unified argument representation to deal with two different types of argument annotations in a uniform fashion. Furthermore, we jointly predict all predicates and arguments, especially including long-term ignored predicate identification subtask. Our single model achieves new state-of-the-art results on both span (CoNLL 2005, 2012) and dependency (CoNLL 2008, 2009) SRL benchmarks.