 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Processing of Point Cloud Ground Segmentation for Mechanical and Solid-State LiDARs
Aug 19, 2024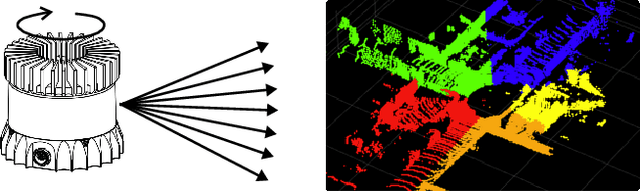
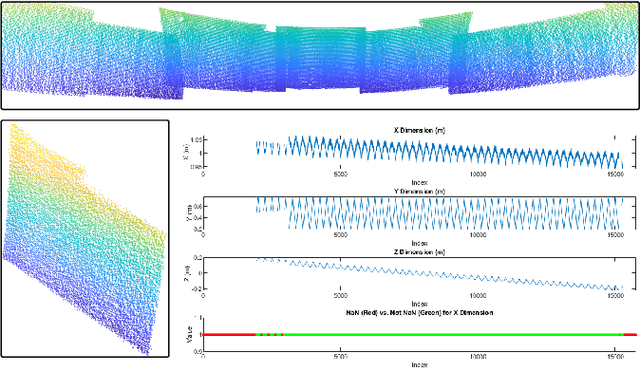
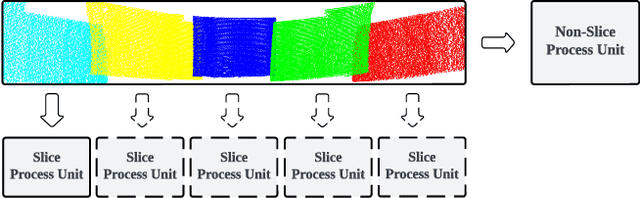
In this study, we introduce a novel parallel processing framework for real-time point cloud ground segmentation on FPGA platforms, aimed at adapting LiDAR algorithms to the evolving landscape from mechanical to solid-state LiDAR (SSL) technologies. Focusing on the ground segmentation task, we explore parallel processing techniques on existing approaches and adapt them to real-world SSL data handling. We validated frame-segmentation based parallel processing methods using point-based, voxel-based, and range-image-based ground segmentation approaches on the SemanticKITTI dataset based on mechanical LiDAR. The results revealed the superior performance and robustness of the range-image method, especially in its resilience to slicing. Further, utilizing a custom dataset from our self-built Camera-SSLSS equipment, we examined regular SSL data frames and validated the effectiveness of our parallel approach for SSL sensor. Additionally, our pioneering implementation of range-image ground segmentation on FPGA for SSL sensors demonstrated significant processing speed improvements and resource efficiency, achieving processing rates up to 50.3 times faster than conventional CPU setups. These findings underscore the potential of parallel processing strategies to significantly enhance LiDAR technologies for advanced perception tasks in autonomous systems. Post-publication, both the data and the code will be made available on GitHub.
Stream-Based Ground Segmentation for Real-Time LiDAR Point Cloud Processing on FPGA
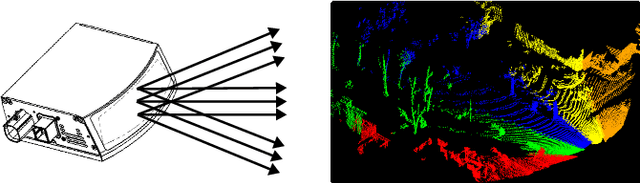
Aug 19, 2024This paper presents a novel and fast approach for ground plane segmentation in a LiDAR point cloud, specifically optimized for processing speed and hardware efficiency on FPGA hardware platforms. Our approach leverages a channel-based segmentation method with an advanced angular data repair technique and a cross-eight-way flood-fill algorithm. This innovative approach significantly reduces the number of iterations while ensuring the high accuracy of the segmented ground plane, which makes the stream-based hardware implementation possible. To validate the proposed approach, we conducted extensive experiments on the SemanticKITTI dataset. We introduced a bird's-eye view (BEV) evaluation metric tailored for the area representation of LiDAR segmentation tasks. Our method demonstrated superior performance in terms of BEV areas when compared to the existing approaches. Moreover, we presented an optimized hardware architecture targeted on a Zynq-7000 FPGA, compatible with LiDARs of various channel densities, i.e., 32, 64, and 128 channels. Our FPGA implementation operating at 160 MHz significantly outperforms the traditional computing platforms, which is 12 to 25 times faster than the CPU-based solutions and up to 6 times faster than the GPU-based solution, in addition to the benefit of low power consumption.
Real-Time Joint Simulation of LiDAR Perception and Motion Planning for Automated Driving
May 11, 2023Real-time perception and motion planning are two crucial tasks for autonomous driving. While there are many research works focused on improving the performance of perception and motion planning individually, it is still not clear how a perception error may adversely impact the motion planning results. In this work, we propose a joint simulation framework with LiDAR-based perception and motion planning for real-time automated driving. Taking the sensor input from the CARLA simulator with additive noise, a LiDAR perception system is designed to detect and track all surrounding vehicles and to provide precise orientation and velocity information. Next, we introduce a new collision bound representation that relaxes the communication cost between the perception module and the motion planner. A novel collision checking algorithm is implemented using line intersection checking that is more efficient for long distance range in comparing to the traditional method of occupancy grid. We evaluate the joint simulation framework in CARLA for urban driving scenarios. Experiments show that our proposed automated driving system can execute at 25 Hz, which meets the real-time requirement. The LiDAR perception system has high accuracy within 20 meters when evaluated with the ground truth. The motion planning results in consistent safe distance keeping when tested in CARLA urban driving scenarios.
PRISE: Demystifying Deep Lucas-Kanade with Strongly Star-Convex Constraints for Multimodel Image Alignment
Mar 21, 2023The Lucas-Kanade (LK) method is a classic iterative homography estimation algorithm for image alignment, but often suffers from poor local optimality especially when image pairs have large distortions. To address this challenge, in this paper we propose a novel Deep Star-Convexified Lucas-Kanade (PRISE) method for multimodel image alignment by introducing strongly star-convex constraints into the optimization problem. Our basic idea is to enforce the neural network to approximately learn a star-convex loss landscape around the ground truth give any data to facilitate the convergence of the LK method to the ground truth through the high dimensional space defined by the network. This leads to a minimax learning problem, with contrastive (hinge) losses due to the definition of strong star-convexity that are appended to the original loss for training. We also provide an efficient sampling based algorithm to leverage the training cost, as well as some analysis on the quality of the solutions from PRISE. We further evaluate our approach on benchmark datasets such as MSCOCO, GoogleEarth, and GoogleMap, and demonstrate state-of-the-art results, especially for small pixel errors. Code can be downloaded from https://github.com/Zhang-VISLab.
A Near Sensor Edge Computing System for Point Cloud Semantic Segmentation
Jul 12, 2022
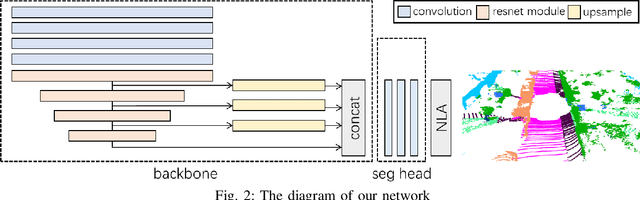
Point cloud semantic segmentation has attracted attentions due to its robustness to light condition. This makes it an ideal semantic solution for autonomous driving. However, considering the large computation burden and bandwidth demanding of neural networks, putting all the computing into vehicle Electronic Control Unit (ECU) is not efficient or practical. In this paper, we proposed a light weighted point cloud semantic segmentation network based on range view. Due to its simple pre-processing and standard convolution, it is efficient when running on deep learning accelerator like DPU. Furthermore, a near sensor computing system is built for autonomous vehicles. In this system, a FPGA-based deep learning accelerator core (DPU) is placed next to the LiDAR sensor, to perform point cloud pre-processing and segmentation neural network. By leaving only the post-processing step to ECU, this solution heavily alleviate the computation burden of ECU and consequently shortens the decision making and vehicles reaction latency. Our semantic segmentation network achieved 10 frame per second (fps) on Xilinx DPU with computation efficiency 42.5 GOP/W.
CoFi: Coarse-to-Fine ICP for LiDAR Localization in an Efficient Long-lasting Point Cloud Map
Oct 19, 2021
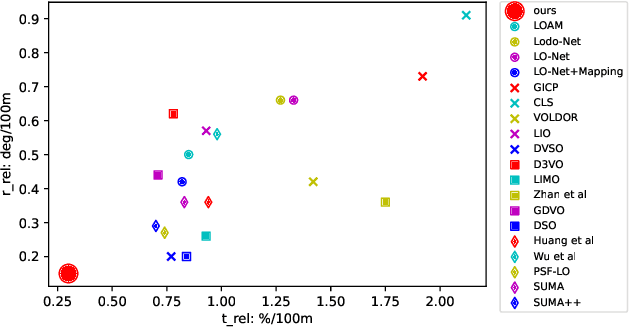
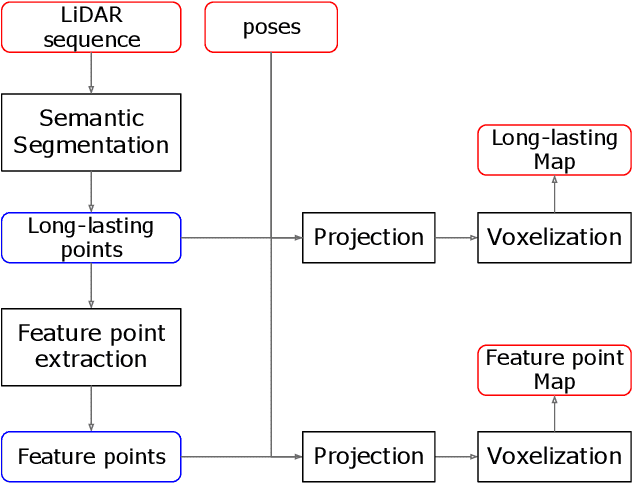
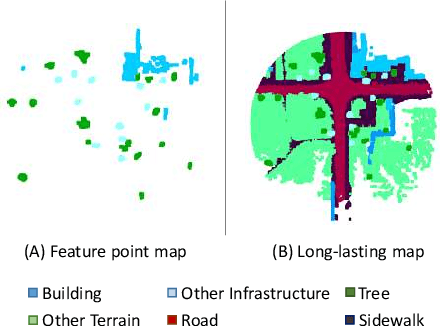
LiDAR odometry and localization has attracted increasing research interest in recent years. In the existing works, iterative closest point (ICP) is widely used since it is precise and efficient. Due to its non-convexity and its local iterative strategy, however, ICP-based method easily falls into local optima, which in turn calls for a precise initialization. In this paper, we propose CoFi, a Coarse-to-Fine ICP algorithm for LiDAR localization. Specifically, the proposed algorithm down-samples the input point sets under multiple voxel resolution, and gradually refines the transformation from the coarse point sets to the fine-grained point sets. In addition, we propose a map based LiDAR localization algorithm that extracts semantic feature points from the LiDAR frames and apply CoFi to estimate the pose on an efficient point cloud map. With the help of the Cylinder3D algorithm for LiDAR scan semantic segmentation, the proposed CoFi localization algorithm demonstrates the state-of-the-art performance on the KITTI odometry benchmark, with significant improvement over the literature.
A Divide-and-Merge Point Cloud Clustering Algorithm for LiDAR Panoptic Segmentation
Sep 16, 2021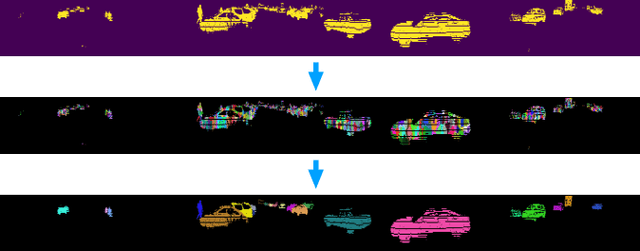
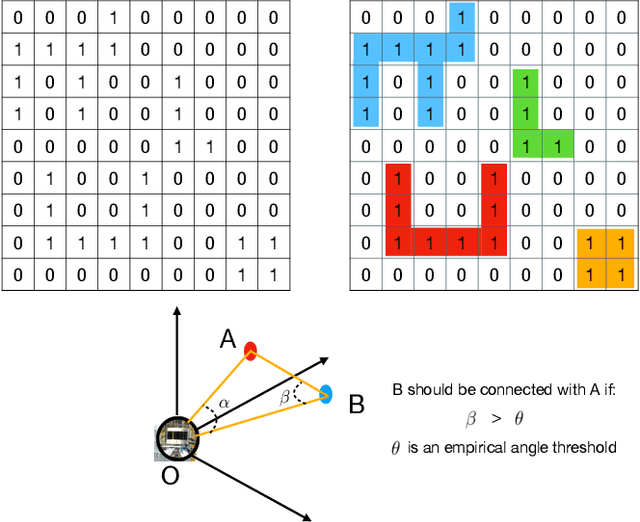
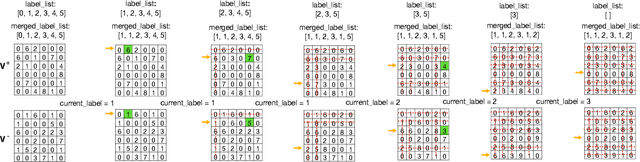

Clustering objects from the LiDAR point cloud is an important research problem with many applications such as autonomous driving. To meet the real-time requirement, existing research proposed to apply the connected-component-labeling (CCL) technique on LiDAR spherical range image with a heuristic condition to check if two neighbor points are connected. However, LiDAR range image is different from a binary image which has a deterministic condition to tell if two pixels belong to the same component. The heuristic condition used on the LiDAR range image only works empirically, which suggests the LiDAR clustering algorithm should be robust to potential failures of the empirical heuristic condition. To overcome this challenge, this paper proposes a divide-and-merge LiDAR clustering algorithm. This algorithm firstly conducts clustering in each evenly divided local region, then merges the local clustered small components by voting on edge point pairs. Assuming there are $N$ LiDAR points of objects in total with $m$ divided local regions, the time complexity of the proposed algorithm is $O(N)+O(m^2)$. A smaller $m$ means the voting will involve more neighbor points, but the time complexity will become larger. So the $m$ controls the trade-off between the time complexity and the clustering accuracy. A proper $m$ helps the proposed algorithm work in real-time as well as maintain good performance. We evaluate the divide-and-merge clustering algorithm on the SemanticKITTI panoptic segmentation benchmark by cascading it with a state-of-the-art semantic segmentation model. The final performance evaluated through the leaderboard achieves the best among all published methods. The proposed algorithm is implemented with C++ and wrapped as a python function. It can be easily used with the modern deep learning framework in python.
FIDNet: LiDAR Point Cloud Semantic Segmentation with Fully Interpolation Decoding
Sep 08, 2021

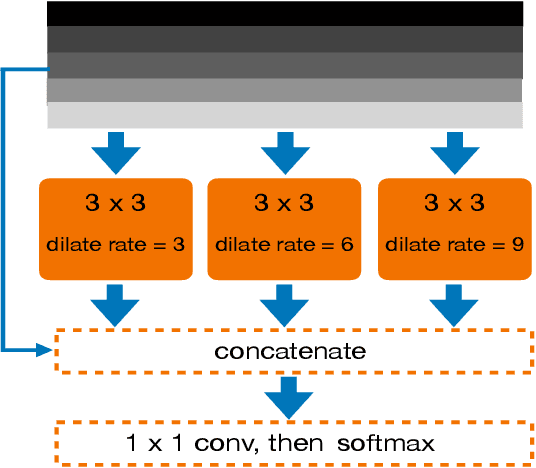

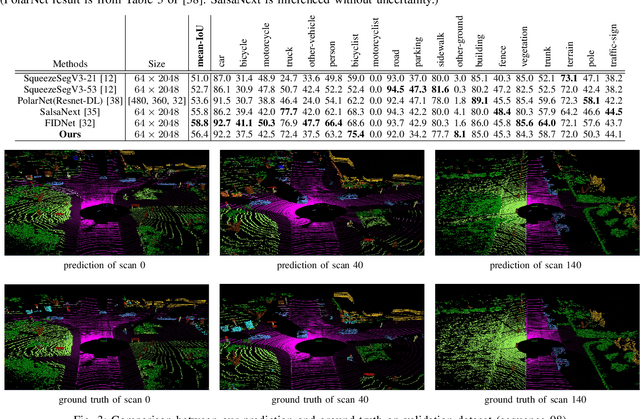
Projecting the point cloud on the 2D spherical range image transforms the LiDAR semantic segmentation to a 2D segmentation task on the range image. However, the LiDAR range image is still naturally different from the regular 2D RGB image; for example, each position on the range image encodes the unique geometry information. In this paper, we propose a new projection-based LiDAR semantic segmentation pipeline that consists of a novel network structure and an efficient post-processing step. In our network structure, we design a FID (fully interpolation decoding) module that directly upsamples the multi-resolution feature maps using bilinear interpolation. Inspired by the 3D distance interpolation used in PointNet++, we argue this FID module is a 2D version distance interpolation on $(\theta, \phi)$ space. As a parameter-free decoding module, the FID largely reduces the model complexity by maintaining good performance. Besides the network structure, we empirically find that our model predictions have clear boundaries between different semantic classes. This makes us rethink whether the widely used K-nearest-neighbor post-processing is still necessary for our pipeline. Then, we realize the many-to-one mapping causes the blurring effect that some points are mapped into the same pixel and share the same label. Therefore, we propose to process those occluded points by assigning the nearest predicted label to them. This NLA (nearest label assignment) post-processing step shows a better performance than KNN with faster inference speed in the ablation study. On the SemanticKITTI dataset, our pipeline achieves the best performance among all projection-based methods with $64 \times 2048$ resolution and all point-wise solutions. With a ResNet-34 as the backbone, both the training and testing of our model can be finished on a single RTX 2080 Ti with 11G memory. The code is released.
A Technical Survey and Evaluation of Traditional Point Cloud Clustering Methods for LiDAR Panoptic Segmentation
Aug 21, 2021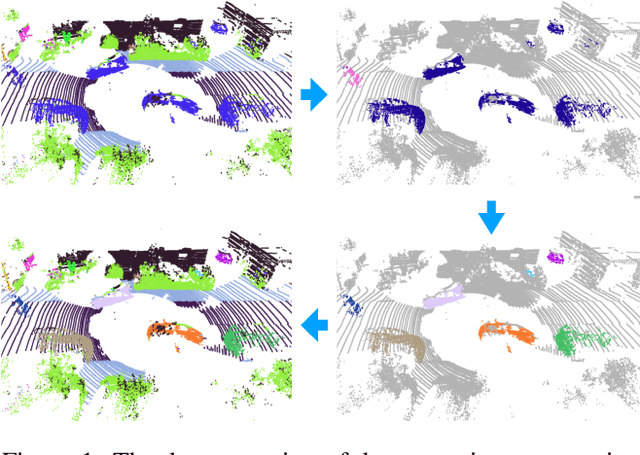
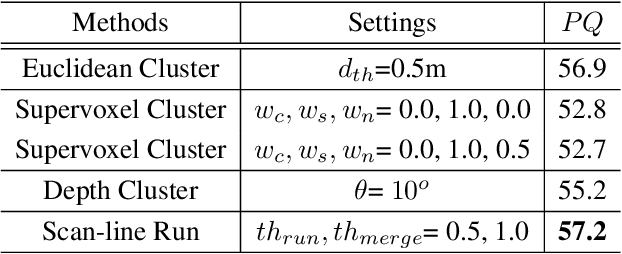
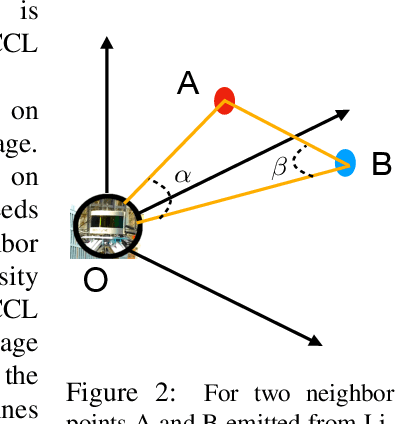
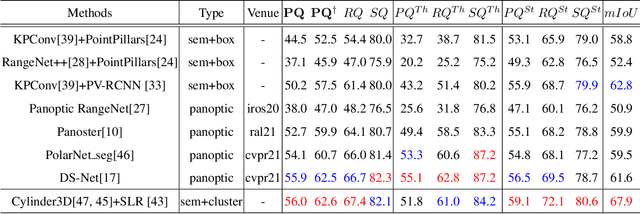
LiDAR panoptic segmentation is a newly proposed technical task for autonomous driving. In contrast to popular end-to-end deep learning solutions, we propose a hybrid method with an existing semantic segmentation network to extract semantic information and a traditional LiDAR point cloud cluster algorithm to split each instance object. We argue geometry-based traditional clustering algorithms are worth being considered by showing a state-of-the-art performance among all published end-to-end deep learning solutions on the panoptic segmentation leaderboard of the SemanticKITTI dataset. To our best knowledge, we are the first to attempt the point cloud panoptic segmentation with clustering algorithms. Therefore, instead of working on new models, we give a comprehensive technical survey in this paper by implementing four typical cluster methods and report their performances on the benchmark. Those four cluster methods are the most representative ones with real-time running speed. They are implemented with C++ in this paper and then wrapped as a python function for seamless integration with the existing deep learning frameworks. We release our code for peer researchers who might be interested in this problem.
Revisiting 2D Convolutional Neural Networks for Graph-based Applications
May 23, 2021
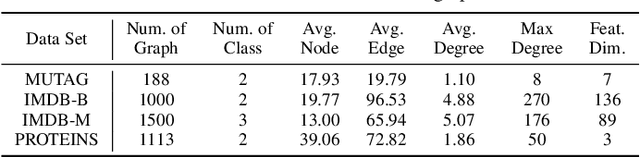
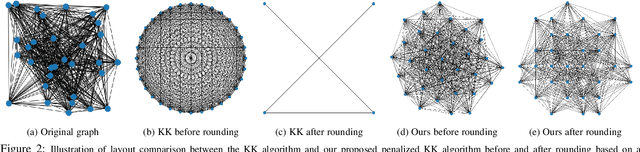
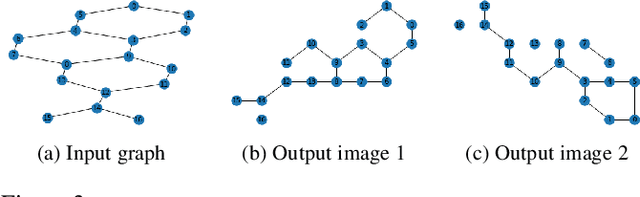
Graph convolutional networks (GCNs) are widely used in graph-based applications such as graph classification and segmentation. However, current GCNs have limitations on implementation such as network architectures due to their irregular inputs. In contrast, convolutional neural networks (CNNs) are capable of extracting rich features from large-scale input data, but they do not support general graph inputs. To bridge the gap between GCNs and CNNs, in this paper we study the problem of how to effectively and efficiently map general graphs to 2D grids that CNNs can be directly applied to, while preserving graph topology as much as possible. We therefore propose two novel graph-to-grid mapping schemes, namely, {\em graph-preserving grid layout (GPGL)} and its extension {\em Hierarchical GPGL (H-GPGL)} for computational efficiency. We formulate the GPGL problem as integer programming and further propose an approximate yet efficient solver based on a penalized Kamada-Kawai method, a well-known optimization algorithm in 2D graph drawing. We propose a novel vertex separation penalty that encourages graph vertices to lay on the grid without any overlap. Along with this image representation, even extra 2D maxpooling layers contribute to the PointNet, a widely applied point-based neural network. We demonstrate the empirical success of GPGL on general graph classification with small graphs and H-GPGL on 3D point cloud segmentation with large graphs, based on 2D CNNs including VGG16, ResNet50 and multi-scale maxout (MSM) CNN.