 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFi: Coarse-to-Fine ICP for LiDAR Localization in an Efficient Long-lasting Point Cloud Map
Oct 19, 2021
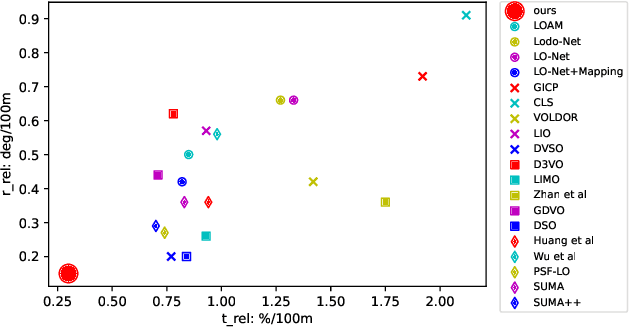
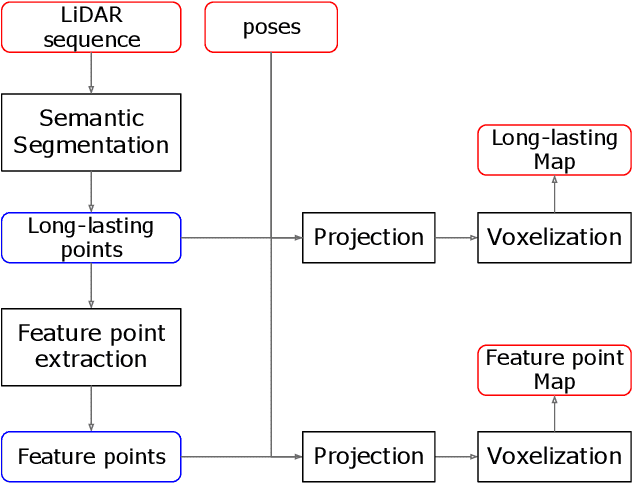
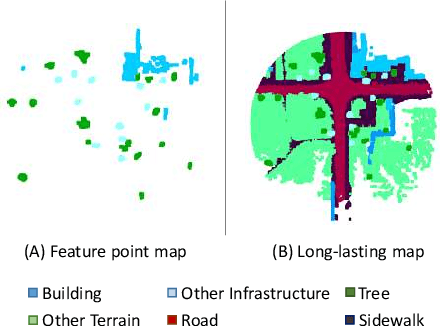
LiDAR odometry and localization has attracted increasing research interest in recent years. In the existing works, iterative closest point (ICP) is widely used since it is precise and efficient. Due to its non-convexity and its local iterative strategy, however, ICP-based method easily falls into local optima, which in turn calls for a precise initialization. In this paper, we propose CoFi, a Coarse-to-Fine ICP algorithm for LiDAR localization. Specifically, the proposed algorithm down-samples the input point sets under multiple voxel resolution, and gradually refines the transformation from the coarse point sets to the fine-grained point sets. In addition, we propose a map based LiDAR localization algorithm that extracts semantic feature points from the LiDAR frames and apply CoFi to estimate the pose on an efficient point cloud map. With the help of the Cylinder3D algorithm for LiDAR scan semantic segmentation, the proposed CoFi localization algorithm demonstrates the state-of-the-art performance on the KITTI odometry benchmark, with significant improvement over the literature.
LiDAR Odometry Methodologies for Autonomous Driving: A Survey
Sep 13, 2021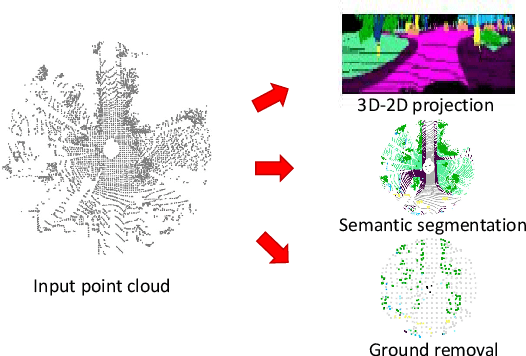
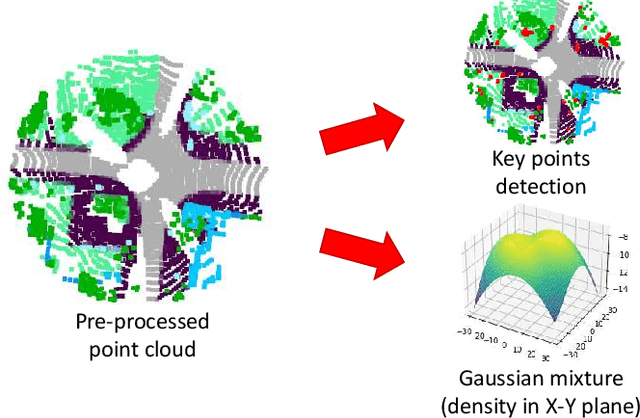
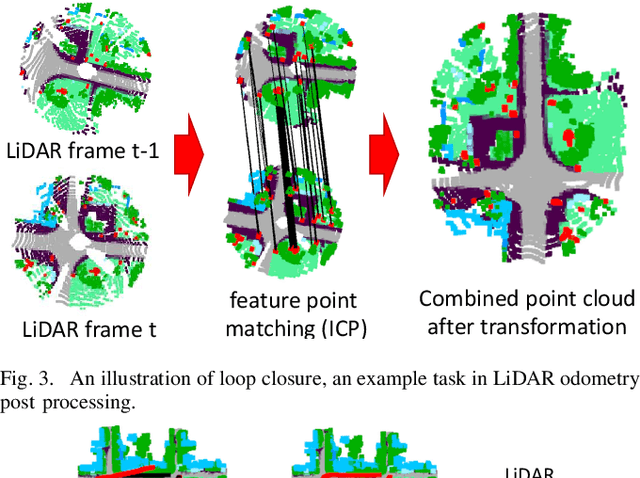
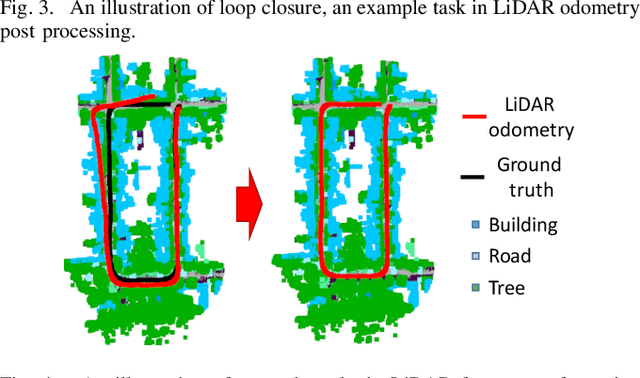
Vehicle odometry is an essential component of an automated driving system as it computes the vehicle's position and orientation. The odometry module has a higher demand and impact in urban areas where the global navigation satellite system (GNSS) signal is weak and noisy. Traditional visual odometry methods suffer from the diverse illumination status and get disparities during pose estimation, which results in significant errors as the error accumulates. Odometry using light detection and ranging (LiDAR) devices has attracted increasing research interest as LiDAR devices are robust to illumination variations. In this survey, we examine the existing LiDAR odometry methods and summarize the pipeline and delineate the several intermediate steps. Additionally, the existing LiDAR odometry methods are categorized by their correspondence type, and their advantages, disadvantages, and correlations are analyzed across-category and within-category in each step. Finally, we compare the accuracy and the running speed among these methodologies evaluated over the KITTI odometry dataset and outline promising future research directions.
Revisiting 2D Convolutional Neural Networks for Graph-based Applications
May 23, 2021
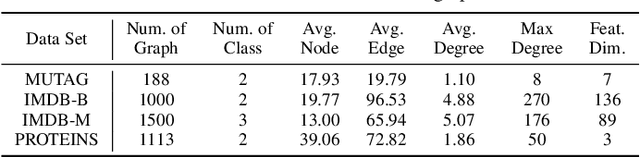
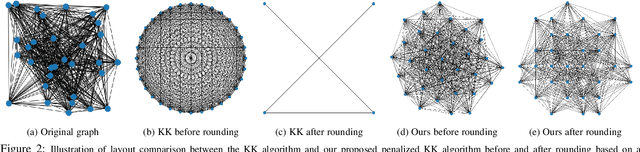
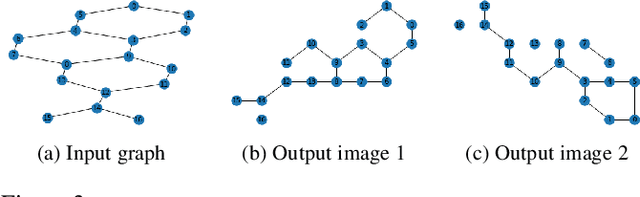
Graph convolutional networks (GCNs) are widely used in graph-based applications such as graph classification and segmentation. However, current GCNs have limitations on implementation such as network architectures due to their irregular inputs. In contrast, convolutional neural networks (CNNs) are capable of extracting rich features from large-scale input data, but they do not support general graph inputs. To bridge the gap between GCNs and CNNs, in this paper we study the problem of how to effectively and efficiently map general graphs to 2D grids that CNNs can be directly applied to, while preserving graph topology as much as possible. We therefore propose two novel graph-to-grid mapping schemes, namely, {\em graph-preserving grid layout (GPGL)} and its extension {\em Hierarchical GPGL (H-GPGL)} for computational efficiency. We formulate the GPGL problem as integer programming and further propose an approximate yet efficient solver based on a penalized Kamada-Kawai method, a well-known optimization algorithm in 2D graph drawing. We propose a novel vertex separation penalty that encourages graph vertices to lay on the grid without any overlap. Along with this image representation, even extra 2D maxpooling layers contribute to the PointNet, a widely applied point-based neural network. We demonstrate the empirical success of GPGL on general graph classification with small graphs and H-GPGL on 3D point cloud segmentation with large graphs, based on 2D CNNs including VGG16, ResNet50 and multi-scale maxout (MSM) CNN.
EllipsoidNet: Ellipsoid Representation for Point Cloud Classification and Segmentation
Mar 03, 2021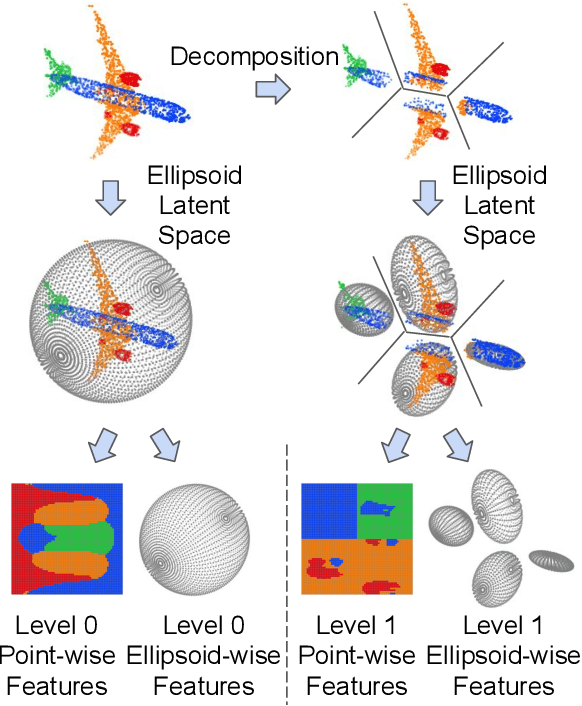
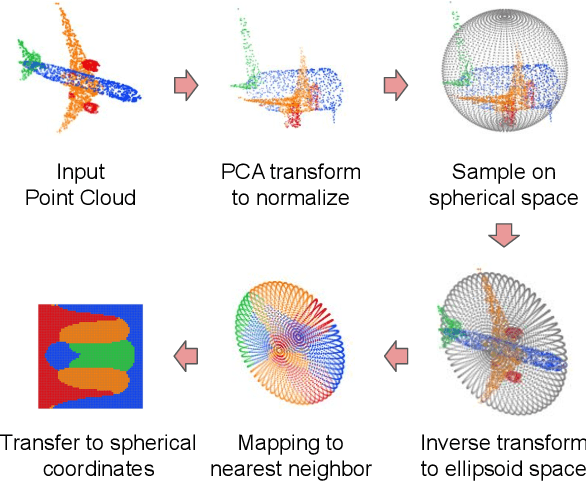
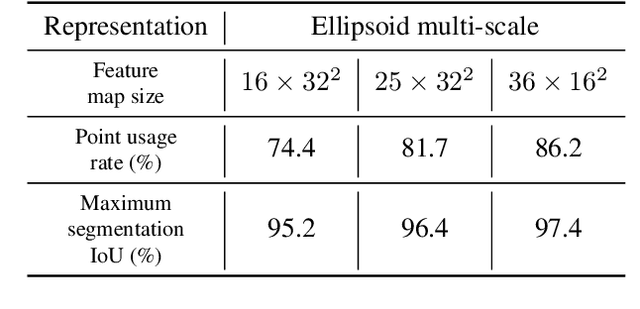
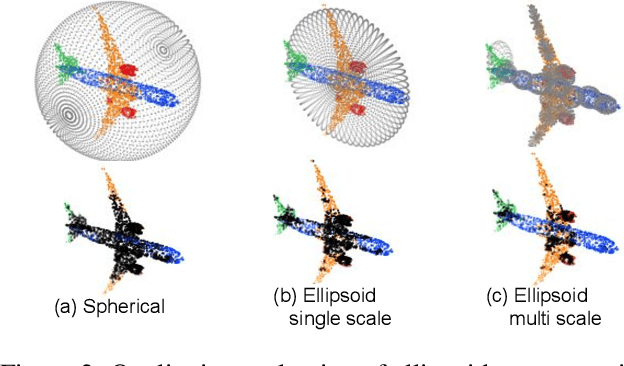
Point cloud patterns are hard to learn because of the implicit local geometry features among the orderless points. In recent years, point cloud representation in 2D space has attracted increasing research interest since it exposes the local geometry features in a 2D space. By projecting those points to a 2D feature map, the relationship between points is inherited in the context between pixels, which are further extracted by a 2D convolutional neural network. However, existing 2D representing methods are either accuracy limited or time-consuming. In this paper, we propose a novel 2D representation method that projects a point cloud onto an ellipsoid surface space, where local patterns are well exposed in ellipsoid-level and point-level. Additionally, a novel convolutional neural network named EllipsoidNet is proposed to utilize those features for point cloud classification and segmentation applications. The proposed methods are evaluated in ModelNet40 and ShapeNet benchmarks, where the advantages are clearly shown over existing 2D representation methods.
Self-Supervised Visual Attention Learning for Vehicle Re-Identification
Oct 19, 2020

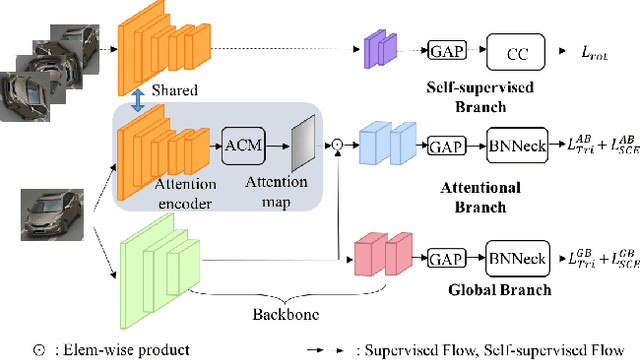
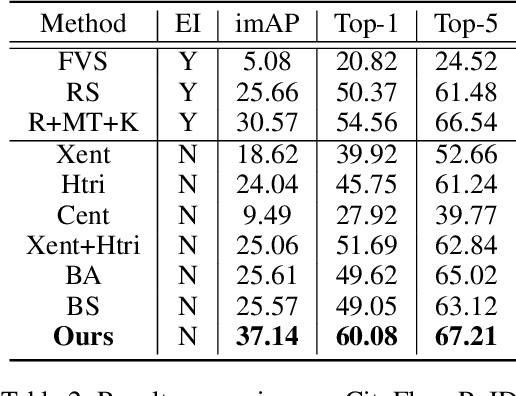
Visual attention learning (VAL) aims to produce a confidence map as weights to detect discriminative features in each image for certain task such as vehicle re-identification (ReID) where the same vehicle instance needs to be identified across different cameras. In contrast to the literature, in this paper we propose utilizing self-supervised learning to regularize VAL to improving the performance for vehicle ReID. Mathematically using lifting we can factorize the two functions of VAL and self-supervised regularization through another shared function. We implement such factorization using a deep learning framework consisting of three branches: (1) a global branch as backbone for image feature extraction, (2) an attentional branch for producing attention masks, and (3) a self-supervised branch for regularizing the attention learning. Our network design naturally leads to an end-to-end multi-task joint optimization. We conduct comprehensive experiments on three benchmark datasets for vehicle ReID, i.e., VeRi-776, CityFlow-ReID, and VehicleID. We demonstrate the state-of-the-art (SOTA) performance of our approach with the capability of capturing informative vehicle parts with no corresponding manual labels. We also demonstrate the good generalization of our approach in other ReID tasks such as person ReID and multi-target multi-camera tracking.
LodoNet: A Deep Neural Network with 2D Keypoint Matchingfor 3D LiDAR Odometry Estimation
Sep 01, 2020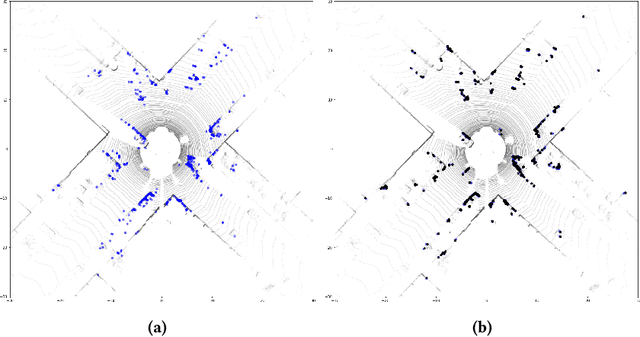
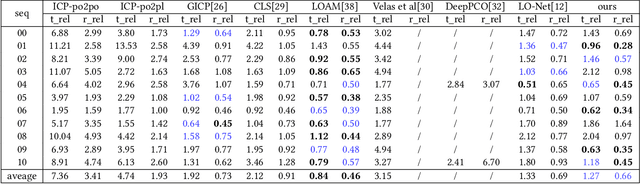
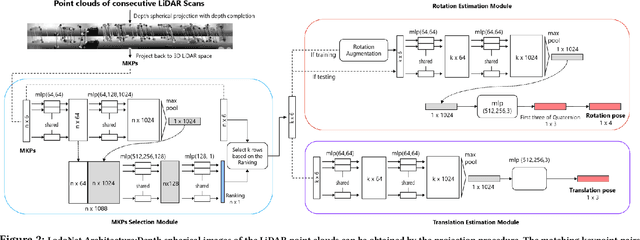
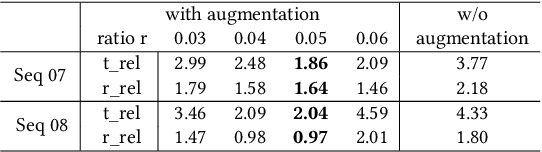
Deep learning based LiDAR odometry (LO) estimation attracts increasing research interests in the field of autonomous driving and robotics. Existing works feed consecutive LiDAR frames into neural networks as point clouds and match pairs in the learned feature space. In contrast, motivated by the success of image based feature extractors, we propose to transfer the LiDAR frames to image space and reformulate the problem as image feature extraction. With the help of scale-invariant feature transform (SIFT) for feature extraction, we are able to generate matched keypoint pairs (MKPs) that can be precisely returned to the 3D space. A convolutional neural network pipeline is designed for LiDAR odometry estimation by extracted MKPs. The proposed scheme, namely LodoNet, is then evaluated in the KITTI odometry estimation benchmark, achieving on par with or even better results than the state-of-the-art.
TreeRNN: Topology-Preserving Deep GraphEmbedding and Learning
Jun 21, 2020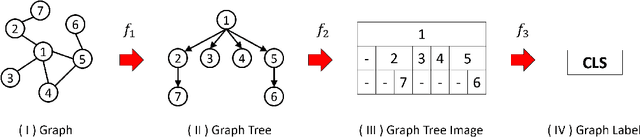



In contrast to the literature where the graph local patterns are captured by customized graph kernels, in this paper we study the problem of how to effectively and efficiently transfer such graphs into image space so that order-sensitive networks such as recurrent neural networks (RNNs) can better extract local pattern in this regularized forms. To this end, we propose a novel topology-preserving graph embedding scheme that transfers the graphs into image space via a graph-tree-image projection, which explicitly present the order of graph nodes on the corresponding graph-trees. Addition to the projection, we propose TreeRNN, a 2D RNN architecture that recurrently integrates the graph nodes along with rows and columns of the graph-tree-images to help classify the graphs. At last, we manage to demonstrate a comparable performance on graph classification datasets including MUTAG, PTC, and NCI1.
RoadNet-RT: High Throughput CNN Architecture and SoC Design for Real-Time Road Segmentation
Jun 13, 2020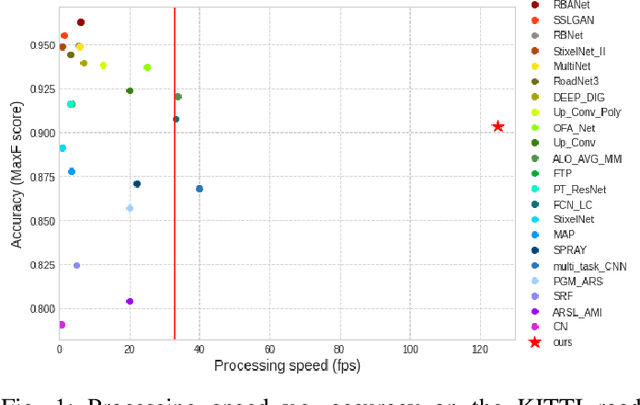
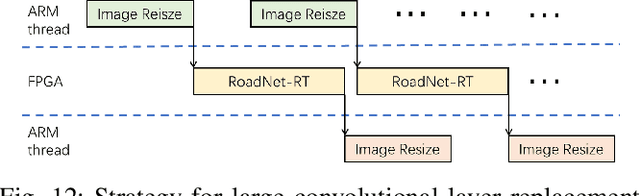
In recent years, convolutional neural network has gained popularity in many engineering applications especially for computer vision. In order to achieve better performance, often more complex structures and advanced operations are incorporated into the neural networks, which results very long inference time. For time-critical tasks such as autonomous driving and virtual reality, real-time processing is fundamental. In order to reach real-time process speed, a light-weight, high-throughput CNN architecture namely RoadNet-RT is proposed for road segmentation in this paper. It achieves 90.33% MaxF score on test set of KITTI road segmentation task and 8 ms per frame when running on GTX 1080 GPU. Comparing to the state-of-the-art network, RoadNet-RT speeds up the inference time by a factor of 20 at the cost of only 6.2% accuracy loss. For hardware design optimization, several techniques such as depthwise separable convolution and non-uniformed kernel size convolution are customized designed to further reduce the processing time. The proposed CNN architecture has been successfully implemented on an FPGA ZCU102 MPSoC platform that achieves the computation capability of 83.05 GOPS. The system throughput reaches 327.9 frames per second with image size 1216x176.
Automatic Building and Labeling of HD Maps with Deep Learning
Jun 01, 2020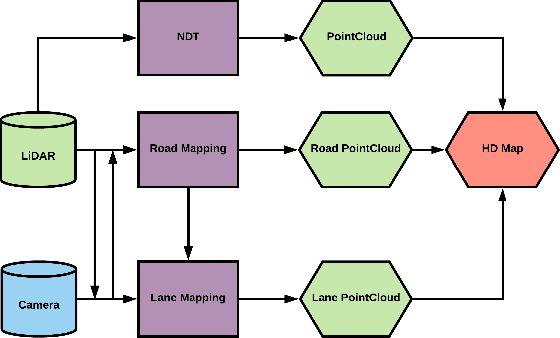
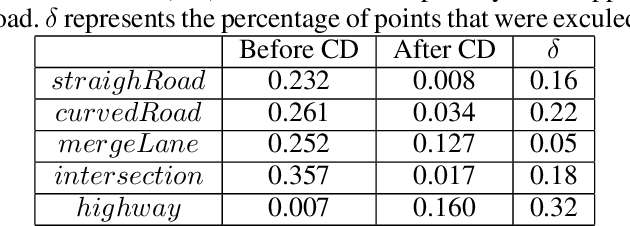
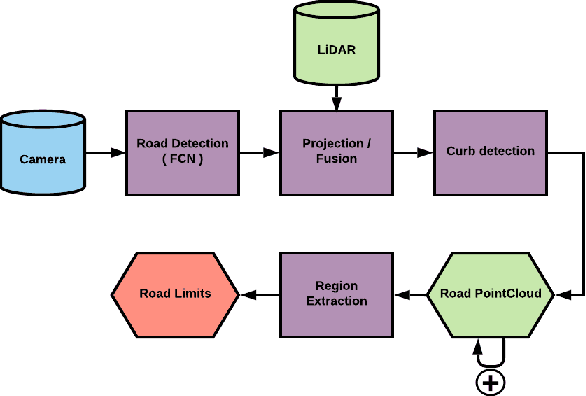
In a world where autonomous driving cars are becoming increasingly more common, creating an adequate infrastructure for this new technology is essential. This includes building and labeling high-definition (HD) maps accurately and efficiently. Today, the process of creating HD maps requires a lot of human input, which takes time and is prone to errors. In this paper, we propose a novel method capable of generating labelled HD maps from raw sensor data. We implemented and tested our methods on several urban scenarios using data collected from our test vehicle. The results show that the pro-posed deep learning based method can produce highly accurate HD maps. This approach speeds up the process of building and labeling HD maps, which can make meaningful contribution to the deployment of autonomous vehicle.
Learning to Segment 3D Point Clouds in 2D Image Space
Mar 23, 2020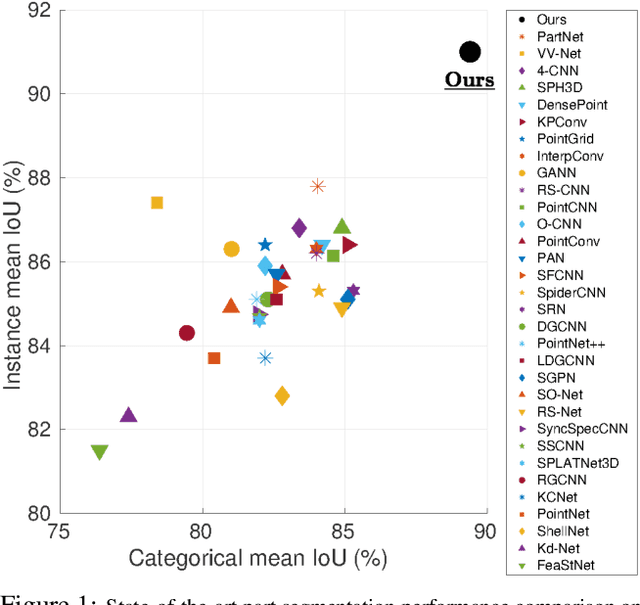
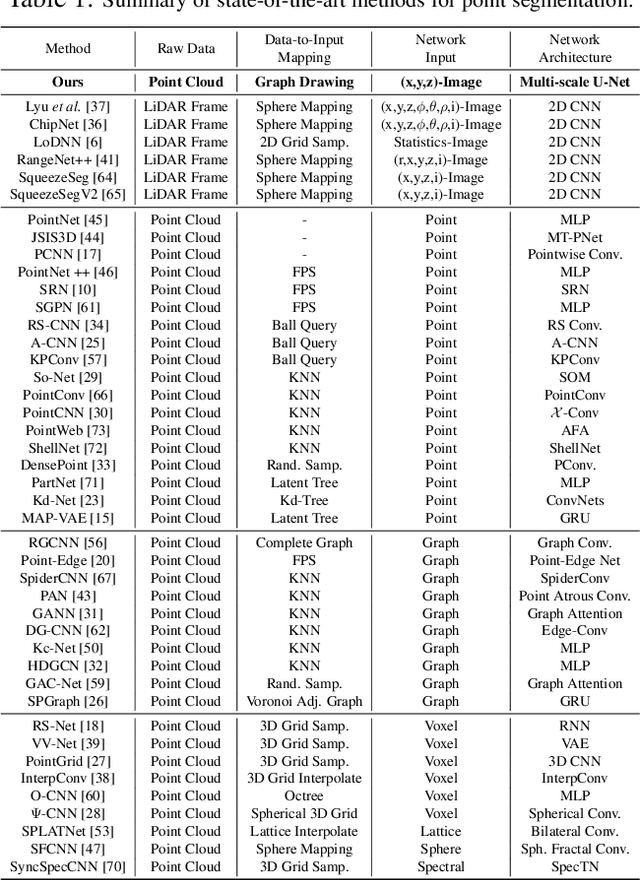

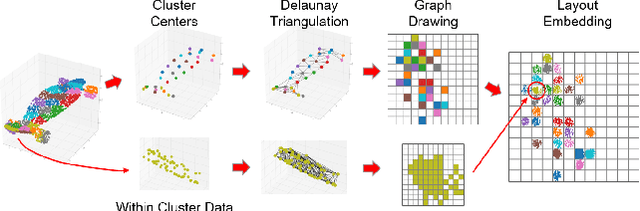
In contrast to the literature where local patterns in 3D point clouds are captured by customized convolutional operators, in this paper we study the problem of how to effectively and efficiently project such point clouds into a 2D image space so that traditional 2D convolutional neural networks (CNNs) such as U-Net can be applied for segmentation. To this end, we are motivated by graph drawing and reformulate it as an integer programming problem to learn the topology-preserving graph-to-grid mapping for each individual point cloud. To accelerate the computation in practice, we further propose a novel hierarchical approximate algorithm. With the help of the Delaunay triangulation for graph construction from point clouds and a multi-scale U-Net for segmentation, we manage to demonstrate the state-of-the-art performance on ShapeNet and PartNet, respectively, with significant improvement over the literature. Code is available at https://github.com/Zhang-VISLab.