 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak-to-Strong Generalization Enables Fully Automated De Novo Training of Multi-head Mask-RCNN Model for Segmenting Densely Overlapping Cell Nuclei in Multiplex Whole-slice Brain Images
Dec 12, 2025We present a weak to strong generalization methodology for fully automated training of a multi-head extension of the Mask-RCNN method with efficient channel attention for reliable segmentation of overlapping cell nuclei in multiplex cyclic immunofluorescent (IF) whole-slide images (WSI), and present evidence for pseudo-label correction and coverage expansion, the key phenomena underlying weak to strong generalization. This method can learn to segment de novo a new class of images from a new instrument and/or a new imaging protocol without the need for human annotations. We also present metrics for automated self-diagnosis of segmentation quality in production environments, where human visual proofreading of massive WSI images is unaffordable. Our method was benchmarked against five current widely used methods and showed a significant improvement. The code, sample WSI images, and high-resolution segmentation results are provided in open form for community adoption and adaptation.
mViSE: A Visual Search Engine for Analyzing Multiplex IHC Brain Tissue Images
Dec 12, 2025Whole-slide multiplex imaging of brain tissue generates massive information-dense images that are challenging to analyze and require custom software. We present an alternative query-driven programming-free strategy using a multiplex visual search engine (mViSE) that learns the multifaceted brain tissue chemoarchitecture, cytoarchitecture, and myeloarchitecture. Our divide-and-conquer strategy organizes the data into panels of related molecular markers and uses self-supervised learning to train a multiplex encoder for each panel with explicit visual confirmation of successful learning. Multiple panels can be combined to process visual queries for retrieving similar communities of individual cells or multicellular niches using information-theoretic methods. The retrievals can be used for diverse purposes including tissue exploration, delineating brain regions and cortical cell layers, profiling and comparing brain regions without computer programming. We validated mViSE's ability to retrieve single cells, proximal cell pairs, tissue patches, delineate cortical layers, brain regions and sub-regions. mViSE is provided as an open-source QuPath plug-in.
Collaborative Secret and Covert Communications for Multi-User Multi-Antenna Uplink UAV Systems: Design and Optimization
Jul 08, 2024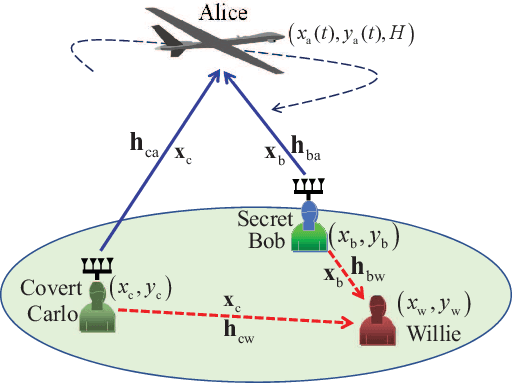
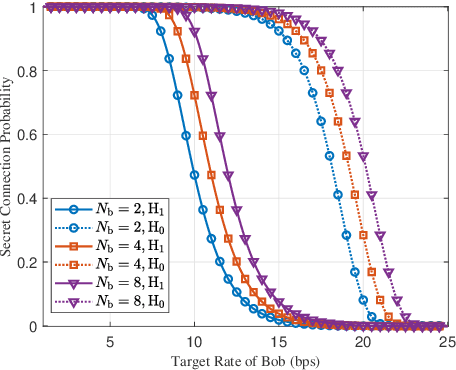
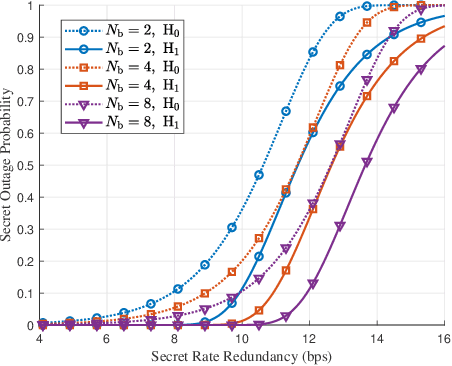
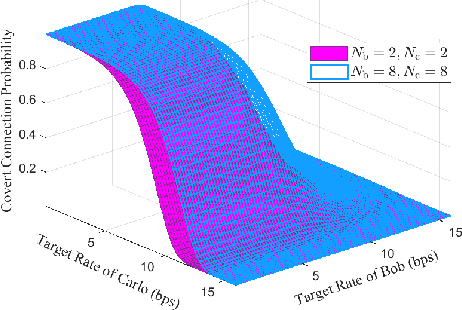
Motivated by diverse secure requirements of multi-user in UAV systems, we propose a collaborative secret and covert transmission method for multi-antenna ground users to unmanned aerial vehicle (UAV) communications. Specifically, based on the power domain non-orthogonal multiple access (NOMA), two ground users with distinct security requirements, named Bob and Carlo, superimpose their signals and transmit the combined signal to the UAV named Alice. An adversary Willie attempts to simultaneously eavesdrop Bob's confidential message and detect whether Carlo is transmitting or not. We derive close-form expressions of the secrecy connection probability (SCP) and the covert connection probability (CCP) to evaluate the link reliability for wiretap and covert transmissions, respectively. Furthermore, we bound the secrecy outage probability (SOP) from Bob to Alice and the detection error probability (DEP) of Willie to evaluate the link security for wiretap and covert transmissions, respectively. To characterize the theoretical benchmark of the above model, we formulate a weighted multi-objective optimization problem to maximize the average of secret and covert transmission rates subject to constraints SOP, DEP, the beamformers of Bob and Carlo, and UAV trajectory parameters. To solve the optimization problem, we propose an iterative optimization algorithm using successive convex approximation and block coordinate descent (SCA-BCD) methods. Our results reveal the influence of design parameters of the system on the wiretap and covert rates, analytically and numerically. In summary, our study fills the gaps in joint secret and covert transmission for multi-user multi-antenna uplink UAV communications and provides insights to construct such systems.
Large and Small Deviations for Statistical Sequence Matching
Jul 03, 2024



We revisit the problem of statistical sequence matching between two databases of sequences initiated by Unnikrishnan (TIT 2015) and derive theoretical performance guarantees for the generalized likelihood ratio test (GLRT). We first consider the case where the number of matched pairs of sequences between the databases is known. In this case, the task is to accurately find the matched pairs of sequences among all possible matches between the sequences in the two databases. We analyze the performance of the GLRT by Unnikrishnan and explicitly characterize the tradeoff between the mismatch and false reject probabilities under each hypothesis in both large and small deviations regimes. Furthermore, we demonstrate the optimality of Unnikrishnan's GLRT test under the generalized Neyman-Person criterion for both regimes and illustrate our theoretical results via numerical examples. Subsequently, we generalize our achievability analyses to the case where the number of matched pairs is unknown, and an additional error probability needs to be considered. When one of the two databases contains a single sequence, the problem of statistical sequence matching specializes to the problem of multiple classification introduced by Gutman (TIT 1989). For this special case, our result for the small deviations regime strengthens previous result of Zhou, Tan and Motani (Information and Inference 2020) by removing unnecessary conditions on the generating distributions.
VGA: Vision and Graph Fused Attention Network for Rumor Detection
Jan 03, 2024



With the development of social media, rumors have been spread broadly on social media platforms, causing great harm to society. Beside textual information, many rumors also use manipulated images or conceal textual information within images to deceive people and avoid being detected, making multimodal rumor detection be a critical problem. The majority of multimodal rumor detection methods mainly concentrate on extracting features of source claims and their corresponding images, while ignoring the comments of rumors and their propagation structures. These comments and structures imply the wisdom of crowds and are proved to be crucial to debunk rumors. Moreover, these methods usually only extract visual features in a basic manner, seldom consider tampering or textual information in images. Therefore, in this study, we propose a novel Vision and Graph Fused Attention Network (VGA) for rumor detection to utilize propagation structures among posts so as to obtain the crowd opinions and further explore visual tampering features, as well as the textual information hidden in images. We conduct extensive experiments on three datasets, demonstrating that VGA can effectively detect multimodal rumors and outperform state-of-the-art methods significantly.
GraphAlign: Enhancing Accurate Feature Alignment by Graph matching for Multi-Modal 3D Object Detection
Oct 12, 2023



LiDAR and cameras are complementary sensors for 3D object detection in autonomous driving. However, it is challenging to explore the unnatural interaction between point clouds and images, and the critical factor is how to conduct feature alignment of heterogeneous modalities. Currently, many methods achieve feature alignment by projection calibration only, without considering the problem of coordinate conversion accuracy errors between sensors, leading to sub-optimal performance. In this paper, we present GraphAlign, a more accurate feature alignment strategy for 3D object detection by graph matching. Specifically, we fuse image features from a semantic segmentation encoder in the image branch and point cloud features from a 3D Sparse CNN in the LiDAR branch. To save computation, we construct the nearest neighbor relationship by calculating Euclidean distance within the subspaces that are divided into the point cloud features. Through the projection calibration between the image and point cloud, we project the nearest neighbors of point cloud features onto the image features. Then by matching the nearest neighbors with a single point cloud to multiple images, we search for a more appropriate feature alignment. In addition, we provide a self-attention module to enhance the weights of significant relations to fine-tune the feature alignment between heterogeneous modalities. Extensive experiments on nuScenes benchmark demonstrate the effectiveness and efficiency of our GraphAlign.
Machine Learning for Large-Scale Optimization in 6G Wireless Networks
Jan 03, 2023The sixth generation (6G) wireless systems are envisioned to enable the paradigm shift from "connected things" to "connected intelligence", featured by ultra high density, large-scale, dynamic heterogeneity, diversified functional requirements and machine learning capabilities, which leads to a growing need for highly efficient intelligent algorithms. The classic optimization-based algorithms usually require highly precise mathematical model of data links and suffer from poor performance with high computational cost in realistic 6G applications. Based on domain knowledge (e.g., optimization models and theoretical tools), machine learning (ML) stands out as a promising and viable methodology for many complex large-scale optimization problems in 6G, due to its superior performance, generalizability, computational efficiency and robustness. In this paper, we systematically review the most representative "learning to optimize" techniques in diverse domains of 6G wireless networks by identifying the inherent feature of the underlying optimization problem and investigating the specifically designed ML frameworks from the perspective of optimization. In particular, we will cover algorithm unrolling, learning to branch-and-bound, graph neural network for structured optimization, deep reinforcement learning for stochastic optimization, end-to-end learning for semantic optimization, as well as federated learning for distributed optimization, for solving challenging large-scale optimization problems arising from various important wireless applications. Through the in-depth discussion, we shed light on the excellent performance of ML-based optimization algorithms with respect to the classical methods, and provide insightful guidance to develop advanced ML techniques in 6G networks.
Achievable Error Exponents for Almost Fixed-Length Hypothesis Testing and Classification
Oct 23, 2022



We revisit multiple hypothesis testing and propose a two-phase test, where each phase is a fixed-length test and the second-phase proceeds only if a reject option is decided in the first phase. We derive achievable error exponents of error probabilities under each hypothesis and show that our two-phase test bridges over fixed-length and sequential tests in the similar spirit of Lalitha and Javidi (ISIT, 2016) for binary hypothesis testing. Specifically, our test could achieve the performance close to a sequential test with the asymptotic complexity of a fixed-length test and such test is named the almost fixed-length test. Motivated by practical applications where the generating distribution under each hypothesis is \emph{unknown}, we generalize our results to the statistical classification framework of Gutman (TIT, 1989). We first consider binary classification and then generalize our results to $M$-ary classification. For both cases, we propose a two-phase test, derive achievable error exponents and demonstrate that our two-phase test bridges over fixed-length and sequential tests. In particular, for $M$-ary classification, no final reject option is required to achieve the same exponent as the sequential test of Haghifam, Tan, and Khisti (TIT, 2021). Our results generalize the design and analysis of the almost fixed-length test for binary hypothesis testing to broader and more practical families of $M$-ary hypothesis testing and statistical classification.
The Outcome of the 2022 Landslide4Sense Competition: Advanced Landslide Detection from Multi-Source Satellite Imagery
Sep 12, 2022
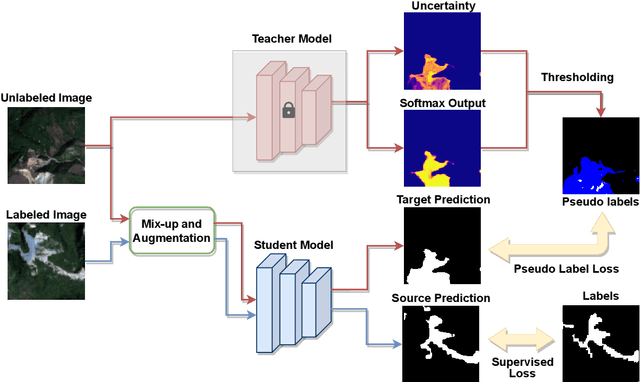
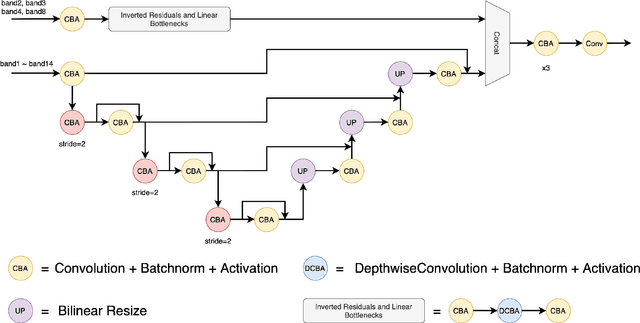
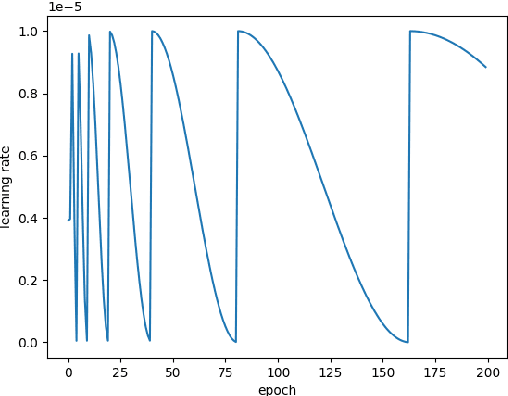
The scientific outcomes of the 2022 Landslide4Sense (L4S) competition organized by the Institute of Advanced Research in Artificial Intelligence (IARAI) are presented here. The objective of the competition is to automatically detect landslides based on large-scale multiple sources of satellite imagery collected globally. The 2022 L4S aims to foster interdisciplinary research on recent developments in deep learning (DL) models for the semantic segmentation task using satellite imagery. In the past few years, DL-based models have achieved performance that meets expectations on image interpretation, due to the development of convolutional neural networks (CNNs). The main objective of this article is to present the details and the best-performing algorithms featured in this competition. The winning solutions are elaborated with state-of-the-art models like the Swin Transformer, SegFormer, and U-Net. Advanced machine learning techniques and strategies such as hard example mining, self-training, and mix-up data augmentation are also considered. Moreover, we describe the L4S benchmark data set in order to facilitate further comparisons, and report the results of the accuracy assessment online. The data is accessible on \textit{Future Development Leaderboard} for future evaluation at \url{https://www.iarai.ac.at/landslide4sense/challenge/}, and researchers are invited to submit more prediction results, evaluate the accuracy of their methods, compare them with those of other users, and, ideally, improve the landslide detection results reported in this article.
A Near Sensor Edge Computing System for Point Cloud Semantic Segmentation
Jul 12, 2022
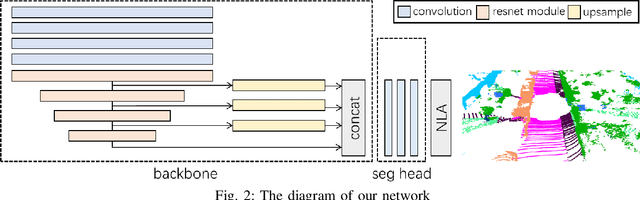
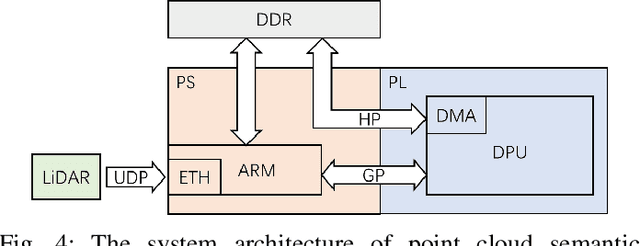
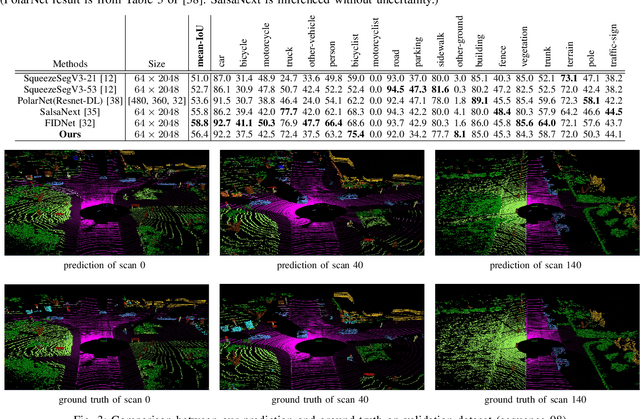
Point cloud semantic segmentation has attracted attentions due to its robustness to light condition. This makes it an ideal semantic solution for autonomous driving. However, considering the large computation burden and bandwidth demanding of neural networks, putting all the computing into vehicle Electronic Control Unit (ECU) is not efficient or practical. In this paper, we proposed a light weighted point cloud semantic segmentation network based on range view. Due to its simple pre-processing and standard convolution, it is efficient when running on deep learning accelerator like DPU. Furthermore, a near sensor computing system is built for autonomous vehicles. In this system, a FPGA-based deep learning accelerator core (DPU) is placed next to the LiDAR sensor, to perform point cloud pre-processing and segmentation neural network. By leaving only the post-processing step to ECU, this solution heavily alleviate the computation burden of ECU and consequently shortens the decision making and vehicles reaction latency. Our semantic segmentation network achieved 10 frame per second (fps) on Xilinx DPU with computation efficiency 42.5 GOP/W.