 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGA-MCTS: Decoupling Planning from Execution via Training-Free Atomic Experience Retrieval
Apr 16, 2026LLM-powered systems require complex multi-step decision-making abilities to solve real-world tasks, yet current planning approaches face a trade-off between the high latency of inference-time search and the limited generalization of supervised fine-tuning. To address this limitation, we introduce \textbf{SGA-MCTS}, a framework that casts LLM planning as non-parametric retrieval. Offline, we leverage Monte Carlo Tree Search (MCTS) to explore the solution space and distill high-fidelity trajectories into State-Goal-Action (SGA) atoms. These atoms are de-lexicalized primitives that abstract concrete entities into symbolic slots, preserving reusable causal logic while discarding domain-specific noise. Online, a retrieval-augmented agent employs a hybrid symbolic-semantic mechanism to fetch relevant SGAs and re-ground them into the current context as soft reasoning hints. Empirical results on complex benchmarks demonstrate that this paradigm enables frozen, open-weights models to match the performance of SOTA systems (e.g., GPT-5) without task-specific fine-tuning. By effectively amortizing the heavy computational cost of search, SGA-MCTS achieves System 2 reasoning depth at System 1 inference speeds, rendering autonomous planning both scalable and real-time feasible.
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Apr 06, 2026Learning from experience is critical for building capable large language model (LLM) agents, yet prevailing self-evolving paradigms remain inefficient: agents learn in isolation, repeatedly rediscover similar behaviors from limited experience, resulting in redundant exploration and poor generalization. To address this problem, we propose SkillX, a fully automated framework for constructing a \textbf{plug-and-play skill knowledge base} that can be reused across agents and environments. SkillX operates through a fully automated pipeline built on three synergistic innovations: \textit{(i) Multi-Level Skills Design}, which distills raw trajectories into three-tiered hierarchy of strategic plans, functional skills, and atomic skills; \textit{(ii) Iterative Skills Refinement}, which automatically revises skills based on execution feedback to continuously improve library quality; and \textit{(iii) Exploratory Skills Expansion}, which proactively generates and validates novel skills to expand coverage beyond seed training data. Using a strong backbone agent (GLM-4.6), we automatically build a reusable skill library and evaluate its transferability on challenging long-horizon, user-interactive benchmarks, including AppWorld, BFCL-v3, and $τ^2$-Bench. Experiments show that SkillKB consistently improves task success and execution efficiency when plugged into weaker base agents, highlighting the importance of structured, hierarchical experience representations for generalizable agent learning. Our code will be publicly available soon at https://github.com/zjunlp/SkillX.
CATNet: Collaborative Alignment and Transformation Network for Cooperative Perception
Mar 05, 2026Cooperative perception significantly enhances scene understanding by integrating complementary information from diverse agents. However, existing research often overlooks critical challenges inherent in real-world multi-source data integration, specifically high temporal latency and multi-source noise. To address these practical limitations, we propose Collaborative Alignment and Transformation Network (CATNet), an adaptive compensation framework that resolves temporal latency and noise interference in multi-agent systems. Our key innovations can be summarized in three aspects. First, we introduce a Spatio-Temporal Recurrent Synchronization (STSync) that aligns asynchronous feature streams via adjacent-frame differential modeling, establishing a temporal-spatially unified representation space. Second, we design a Dual-Branch Wavelet Enhanced Denoiser (WTDen) that suppresses global noise and reconstructs localized feature distortions within aligned representations. Third, we construct an Adaptive Feature Selector (AdpSel) that dynamically focuses on critical perceptual features for robust fusion. Extensive experiments on multiple datasets demonstrate that CATNet consistently outperforms existing methods under complex traffic conditions, proving its superior robustness and adaptability.
HyperAlign: Hypernetwork for Efficient Test-Time Alignment of Diffusion Models
Jan 22, 2026Diffusion models achieve state-of-the-art performance but often fail to generate outputs that align with human preferences and intentions, resulting in images with poor aesthetic quality and semantic inconsistencies. Existing alignment methods present a difficult trade-off: fine-tuning approaches suffer from loss of diversity with reward over-optimization, while test-time scaling methods introduce significant computational overhead and tend to under-optimize. To address these limitations, we propose HyperAlign, a novel framework that trains a hypernetwork for efficient and effective test-time alignment. Instead of modifying latent states, HyperAlign dynamically generates low-rank adaptation weights to modulate the diffusion model's generation operators. This allows the denoising trajectory to be adaptively adjusted based on input latents, timesteps and prompts for reward-conditioned alignment. We introduce multiple variants of HyperAlign that differ in how frequently the hypernetwork is applied, balancing between performance and efficiency. Furthermore, we optimize the hypernetwork using a reward score objective regularized with preference data to reduce reward hacking. We evaluate HyperAlign on multiple extended generative paradigms, including Stable Diffusion and FLUX. It significantly outperforms existing fine-tuning and test-time scaling baselines in enhancing semantic consistency and visual appeal.
Training-Free Motion Customization for Distilled Video Generators with Adaptive Test-Time Distillation
Jun 24, 2025Distilled video generation models offer fast and efficient synthesis but struggle with motion customization when guided by reference videos, especially under training-free settings. Existing training-free methods, originally designed for standard diffusion models, fail to generalize due to the accelerated generative process and large denoising steps in distilled models. To address this, we propose MotionEcho, a novel training-free test-time distillation framework that enables motion customization by leveraging diffusion teacher forcing. Our approach uses high-quality, slow teacher models to guide the inference of fast student models through endpoint prediction and interpolation. To maintain efficiency, we dynamically allocate computation across timesteps according to guidance needs. Extensive experiments across various distilled video generation models and benchmark datasets demonstrate that our method significantly improves motion fidelity and generation quality while preserving high efficiency. Project page: https://euminds.github.io/motionecho/
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Dec 13, 2024



We present DeepSeek-VL2, an advanced series of large Mixture-of-Experts (MoE) Vision-Language Models that significantly improves upon its predecessor, DeepSeek-VL, through two key major upgrades. For the vision component, we incorporate a dynamic tiling vision encoding strategy designed for processing high-resolution images with different aspect ratios. For the language component, we leverage DeepSeekMoE models with the Multi-head Latent Attention mechanism, which compresses Key-Value cache into latent vectors, to enable efficient inference and high throughput. Trained on an improved vision-language dataset, DeepSeek-VL2 demonstrates superior capabilities across various tasks, including but not limited to visual question answering, optical character recognition, document/table/chart understanding, and visual grounding. Our model series is composed of three variants: DeepSeek-VL2-Tiny, DeepSeek-VL2-Small and DeepSeek-VL2, with 1.0B, 2.8B and 4.5B activated parameters respectively. DeepSeek-VL2 achieves competitive or state-of-the-art performance with similar or fewer activated parameters compared to existing open-source dense and MoE-based models. Codes and pre-trained models are publicly accessible at https://github.com/deepseek-ai/DeepSeek-VL2.
DyMO: Training-Free Diffusion Model Alignment with Dynamic Multi-Objective Scheduling
Dec 03, 2024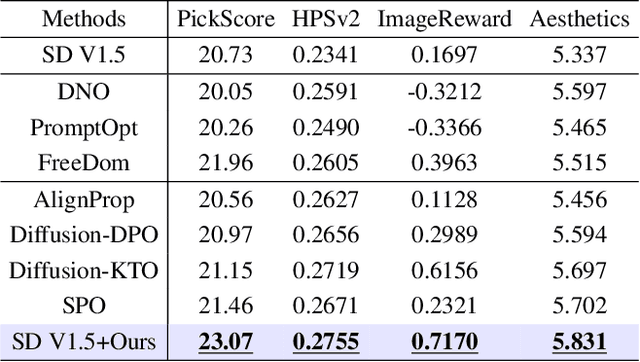
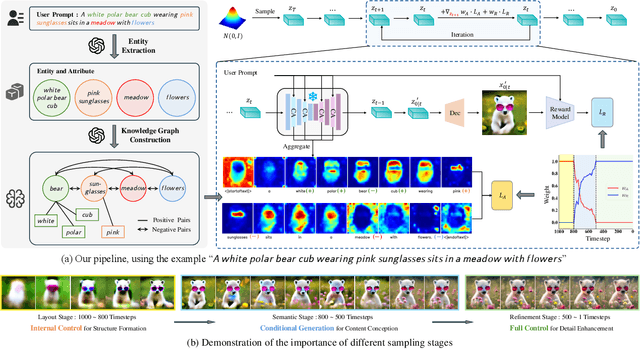


Text-to-image diffusion model alignment is critical for improving the alignment between the generated images and human preferences. While training-based methods are constrained by high computational costs and dataset requirements, training-free alignment methods remain underexplored and are often limited by inaccurate guidance. We propose a plug-and-play training-free alignment method, DyMO, for aligning the generated images and human preferences during inference. Apart from text-aware human preference scores, we introduce a semantic alignment objective for enhancing the semantic alignment in the early stages of diffusion, relying on the fact that the attention maps are effective reflections of the semantics in noisy images. We propose dynamic scheduling of multiple objectives and intermediate recurrent steps to reflect the requirements at different steps. Experiments with diverse pre-trained diffusion models and metrics demonstrate the effectiveness and robustness of the proposed method.
Learned HDR Image Compression for Perceptually Optimal Storage and Display
Jul 18, 2024



High dynamic range (HDR) capture and display have seen significant growth in popularity driven by the advancements in technology and increasing consumer demand for superior image quality. As a result, HDR image compression is crucial to fully realize the benefits of HDR imaging without suffering from large file sizes and inefficient data handling. Conventionally, this is achieved by introducing a residual/gain map as additional metadata to bridge the gap between HDR and low dynamic range (LDR) images, making the former compatible with LDR image codecs but offering suboptimal rate-distortion performance. In this work, we initiate efforts towards end-to-end optimized HDR image compression for perceptually optimal storage and display. Specifically, we learn to compress an HDR image into two bitstreams: one for generating an LDR image to ensure compatibility with legacy LDR displays, and another as side information to aid HDR image reconstruction from the output LDR image. To measure the perceptual quality of output HDR and LDR images, we use two recently proposed image distortion metrics, both validated against human perceptual data of image quality and with reference to the uncompressed HDR image. Through end-to-end optimization for rate-distortion performance, our method dramatically improves HDR and LDR image quality at all bit rates.
Collaborative Secret and Covert Communications for Multi-User Multi-Antenna Uplink UAV Systems: Design and Optimization
Jul 08, 2024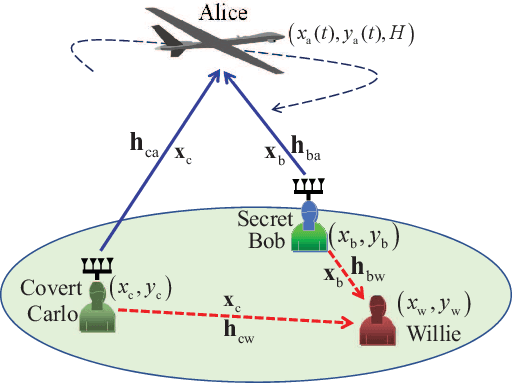
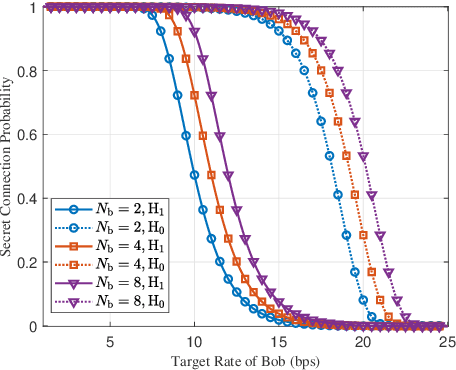
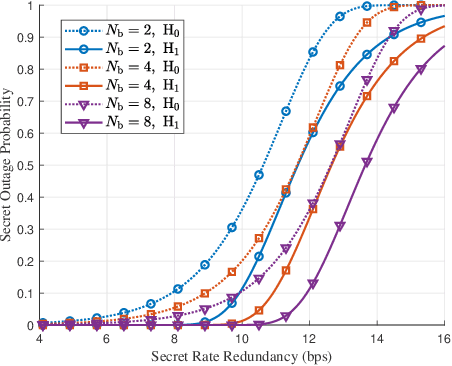
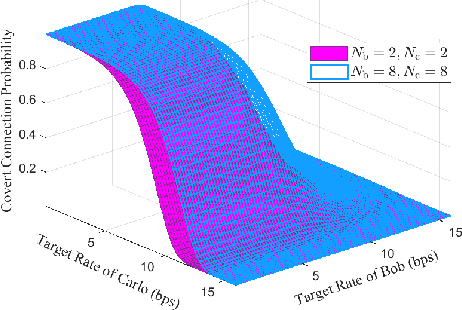
Motivated by diverse secure requirements of multi-user in UAV systems, we propose a collaborative secret and covert transmission method for multi-antenna ground users to unmanned aerial vehicle (UAV) communications. Specifically, based on the power domain non-orthogonal multiple access (NOMA), two ground users with distinct security requirements, named Bob and Carlo, superimpose their signals and transmit the combined signal to the UAV named Alice. An adversary Willie attempts to simultaneously eavesdrop Bob's confidential message and detect whether Carlo is transmitting or not. We derive close-form expressions of the secrecy connection probability (SCP) and the covert connection probability (CCP) to evaluate the link reliability for wiretap and covert transmissions, respectively. Furthermore, we bound the secrecy outage probability (SOP) from Bob to Alice and the detection error probability (DEP) of Willie to evaluate the link security for wiretap and covert transmissions, respectively. To characterize the theoretical benchmark of the above model, we formulate a weighted multi-objective optimization problem to maximize the average of secret and covert transmission rates subject to constraints SOP, DEP, the beamformers of Bob and Carlo, and UAV trajectory parameters. To solve the optimization problem, we propose an iterative optimization algorithm using successive convex approximation and block coordinate descent (SCA-BCD) methods. Our results reveal the influence of design parameters of the system on the wiretap and covert rates, analytically and numerically. In summary, our study fills the gaps in joint secret and covert transmission for multi-user multi-antenna uplink UAV communications and provides insights to construct such systems.