 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
Mar 19, 2026Video action models are an appealing foundation for Vision--Language--Action systems because they can learn visual dynamics from large-scale video data and transfer this knowledge to downstream robot control. Yet current diffusion-based video predictors are trained with likelihood-surrogate objectives, which encourage globally plausible predictions without explicitly optimizing the precision-critical visual dynamics needed for manipulation. This objective mismatch often leads to subtle errors in object pose, spatial relations, and contact timing that can be amplified by downstream policies. We propose VAMPO, a post-training framework that directly improves visual dynamics in video action models through policy optimization. Our key idea is to formulate multi-step denoising as a sequential decision process and optimize the denoising policy with rewards defined over expert visual dynamics in latent space. To make this optimization practical, we introduce an Euler Hybrid sampler that injects stochasticity only at the first denoising step, enabling tractable low-variance policy-gradient estimation while preserving the coherence of the remaining denoising trajectory. We further combine this design with GRPO and a verifiable non-adversarial reward. Across diverse simulated and real-world manipulation tasks, VAMPO improves task-relevant visual dynamics, leading to better downstream action generation and stronger generalization. The homepage is https://vampo-robot.github.io/VAMPO/.
LFD: Layer Fused Decoding to Exploit External Knowledge in Retrieval-Augmented Generation
Aug 27, 2025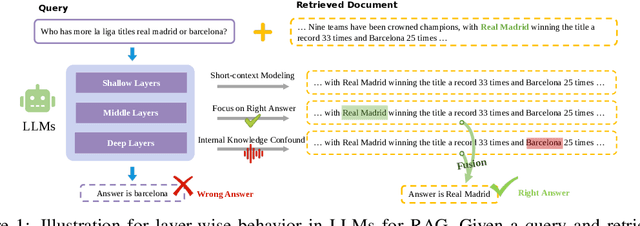
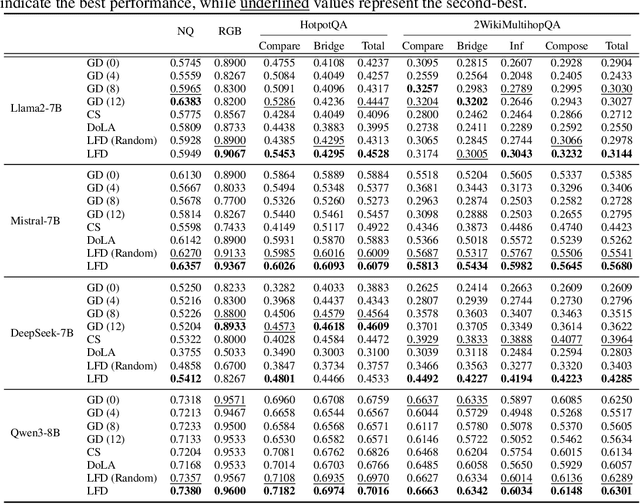
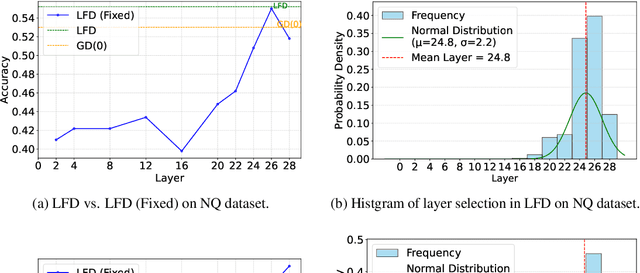

Retrieval-augmented generation (RAG) incorporates external knowledge into large language models (LLMs), improving their adaptability to downstream tasks and enabling information updates. Surprisingly, recent empirical evidence demonstrates that injecting noise into retrieved relevant documents paradoxically facilitates exploitation of external knowledge and improves generation quality. Although counterintuitive and challenging to apply in practice, this phenomenon enables granular control and rigorous analysis of how LLMs integrate external knowledge. Therefore, in this paper, we intervene on noise injection and establish a layer-specific functional demarcation within the LLM: shallow layers specialize in local context modeling, intermediate layers focus on integrating long-range external factual knowledge, and deeper layers primarily rely on parametric internal knowledge. Building on this insight, we propose Layer Fused Decoding (LFD), a simple decoding strategy that directly combines representations from an intermediate layer with final-layer decoding outputs to fully exploit the external factual knowledge. To identify the optimal intermediate layer, we introduce an internal knowledge score (IKS) criterion that selects the layer with the lowest IKS value in the latter half of layers. Experimental results across multiple benchmarks demonstrate that LFD helps RAG systems more effectively surface retrieved context knowledge with minimal cost.
Learned HDR Image Compression for Perceptually Optimal Storage and Display
Jul 18, 2024



High dynamic range (HDR) capture and display have seen significant growth in popularity driven by the advancements in technology and increasing consumer demand for superior image quality. As a result, HDR image compression is crucial to fully realize the benefits of HDR imaging without suffering from large file sizes and inefficient data handling. Conventionally, this is achieved by introducing a residual/gain map as additional metadata to bridge the gap between HDR and low dynamic range (LDR) images, making the former compatible with LDR image codecs but offering suboptimal rate-distortion performance. In this work, we initiate efforts towards end-to-end optimized HDR image compression for perceptually optimal storage and display. Specifically, we learn to compress an HDR image into two bitstreams: one for generating an LDR image to ensure compatibility with legacy LDR displays, and another as side information to aid HDR image reconstruction from the output LDR image. To measure the perceptual quality of output HDR and LDR images, we use two recently proposed image distortion metrics, both validated against human perceptual data of image quality and with reference to the uncompressed HDR image. Through end-to-end optimization for rate-distortion performance, our method dramatically improves HDR and LDR image quality at all bit rates.
Grad-CAMO: Learning Interpretable Single-Cell Morphological Profiles from 3D Cell Painting Images
Mar 26, 2024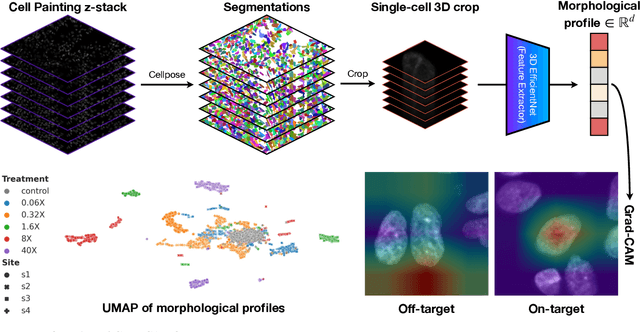
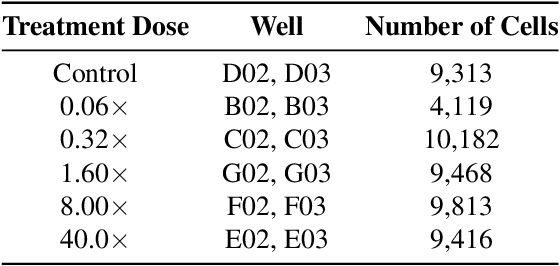
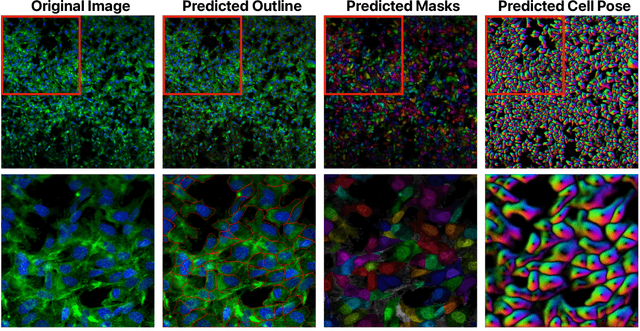
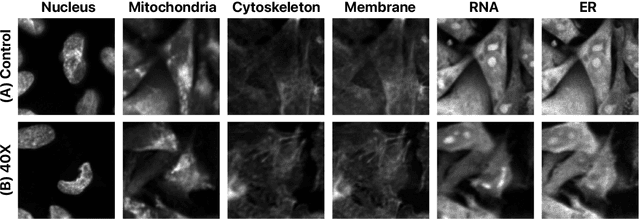
Despite their black-box nature, deep learning models are extensively used in image-based drug discovery to extract feature vectors from single cells in microscopy images. To better understand how these networks perform representation learning, we employ visual explainability techniques (e.g., Grad-CAM). Our analyses reveal several mechanisms by which supervised models cheat, exploiting biologically irrelevant pixels when extracting morphological features from images, such as noise in the background. This raises doubts regarding the fidelity of learned single-cell representations and their relevance when investigating downstream biological questions. To address this misalignment between researcher expectations and machine behavior, we introduce Grad-CAMO, a novel single-cell interpretability score for supervised feature extractors. Grad-CAMO measures the proportion of a model's attention that is concentrated on the cell of interest versus the background. This metric can be assessed per-cell or averaged across a validation set, offering a tool to audit individual features vectors or guide the improved design of deep learning architectures. Importantly, Grad-CAMO seamlessly integrates into existing workflows, requiring no dataset or model modifications, and is compatible with both 2D and 3D Cell Painting data. Additional results are available at https://github.com/eigenvivek/Grad-CAMO.