 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyPose: Localizing Deformable Anatomy in 3D from Sparse 2D X-ray Images using Polyrigid Transforms
May 25, 2025
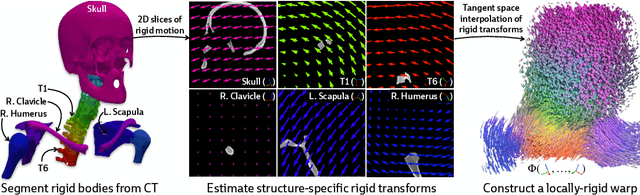


Determining the 3D pose of a patient from a limited set of 2D X-ray images is a critical task in interventional settings. While preoperative volumetric imaging (e.g., CT and MRI) provides precise 3D localization and visualization of anatomical targets, these modalities cannot be acquired during procedures, where fast 2D imaging (X-ray) is used instead. To integrate volumetric guidance into intraoperative procedures, we present PolyPose, a simple and robust method for deformable 2D/3D registration. PolyPose parameterizes complex 3D deformation fields as a composition of rigid transforms, leveraging the biological constraint that individual bones do not bend in typical motion. Unlike existing methods that either assume no inter-joint movement or fail outright in this under-determined setting, our polyrigid formulation enforces anatomically plausible priors that respect the piecewise rigid nature of human movement. This approach eliminates the need for expensive deformation regularizers that require patient- and procedure-specific hyperparameter optimization. Across extensive experiments on diverse datasets from orthopedic surgery and radiotherapy, we show that this strong inductive bias enables PolyPose to successfully align the patient's preoperative volume to as few as two X-ray images, thereby providing crucial 3D guidance in challenging sparse-view and limited-angle settings where current registration methods fail.
Rapid patient-specific neural networks for intraoperative X-ray to volume registration
Mar 20, 2025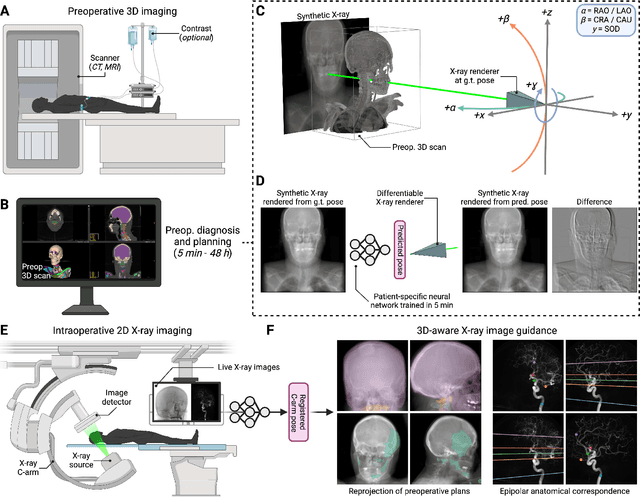


The integration of artificial intelligence in image-guided interventions holds transformative potential, promising to extract 3D geometric and quantitative information from conventional 2D imaging modalities during complex procedures. Achieving this requires the rapid and precise alignment of 2D intraoperative images (e.g., X-ray) with 3D preoperative volumes (e.g., CT, MRI). However, current 2D/3D registration methods fail across the broad spectrum of procedures dependent on X-ray guidance: traditional optimization techniques require custom parameter tuning for each subject, whereas neural networks trained on small datasets do not generalize to new patients or require labor-intensive manual annotations, increasing clinical burden and precluding application to new anatomical targets. To address these challenges, we present xvr, a fully automated framework for training patient-specific neural networks for 2D/3D registration. xvr uses physics-based simulation to generate abundant high-quality training data from a patient's own preoperative volumetric imaging, thereby overcoming the inherently limited ability of supervised models to generalize to new patients and procedures. Furthermore, xvr requires only 5 minutes of training per patient, making it suitable for emergency interventions as well as planned procedures. We perform the largest evaluation of a 2D/3D registration algorithm on real X-ray data to date and find that xvr robustly generalizes across a diverse dataset comprising multiple anatomical structures, imaging modalities, and hospitals. Across surgical tasks, xvr achieves submillimeter-accurate registration at intraoperative speeds, improving upon existing methods by an order of magnitude. xvr is released as open-source software freely available at https://github.com/eigenvivek/xvr.
Differentiable Voxel-based X-ray Rendering Improves Sparse-View 3D CBCT Reconstruction
Dec 02, 2024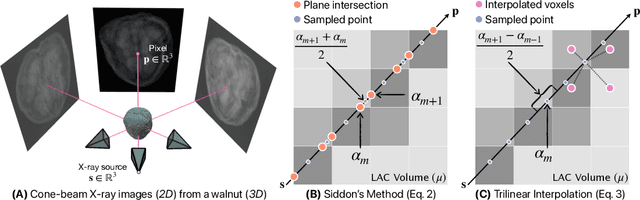
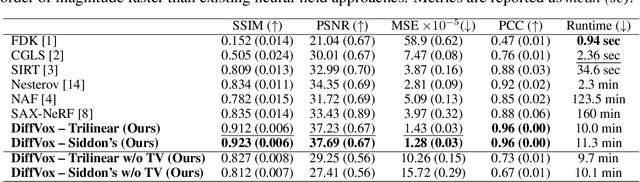
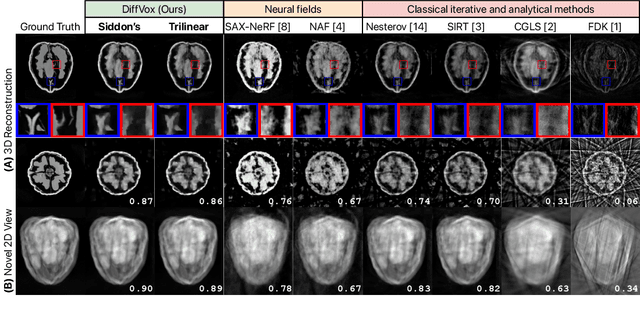
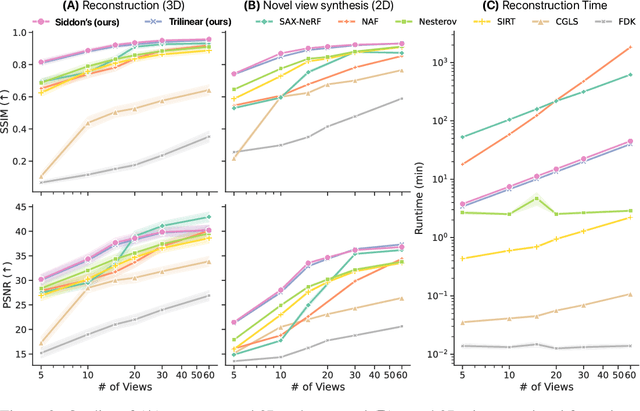
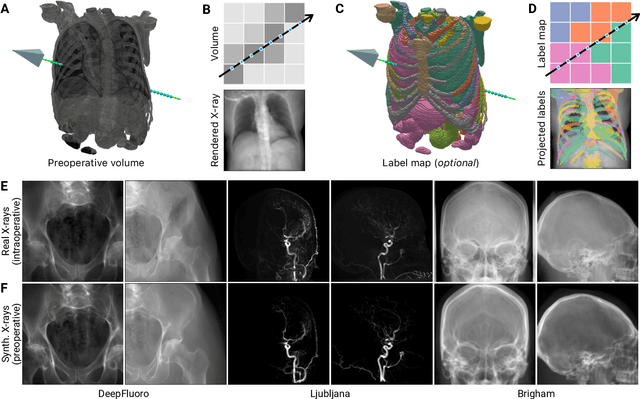
We present DiffVox, a self-supervised framework for Cone-Beam Computed Tomography (CBCT) reconstruction by directly optimizing a voxelgrid representation using physics-based differentiable X-ray rendering. Further, we investigate how the different implementations of the X-ray image formation model in the renderer affect the quality of 3D reconstruction and novel view synthesis. When combined with our regularized voxel-based learning framework, we find that using an exact implementation of the discrete Beer-Lambert law for X-ray attenuation in the renderer outperforms both widely used iterative CBCT reconstruction algorithms and modern neural field approaches, particularly when given only a few input views. As a result, we reconstruct high-fidelity 3D CBCT volumes from fewer X-rays, potentially reducing ionizing radiation exposure and improving diagnostic utility. Our implementation is available at https://github.com/hossein-momeni/DiffVox.
Grad-CAMO: Learning Interpretable Single-Cell Morphological Profiles from 3D Cell Painting Images
Mar 26, 2024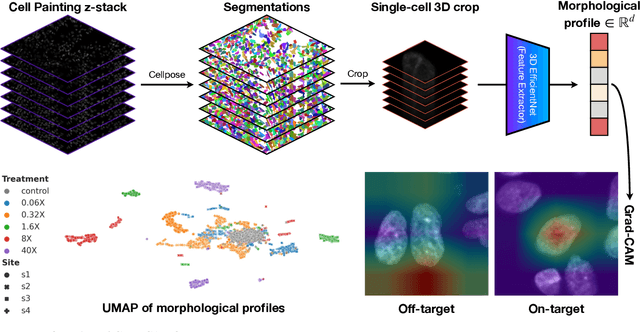
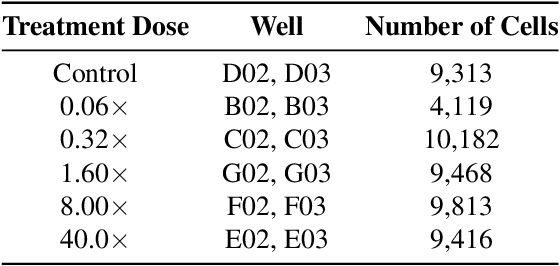
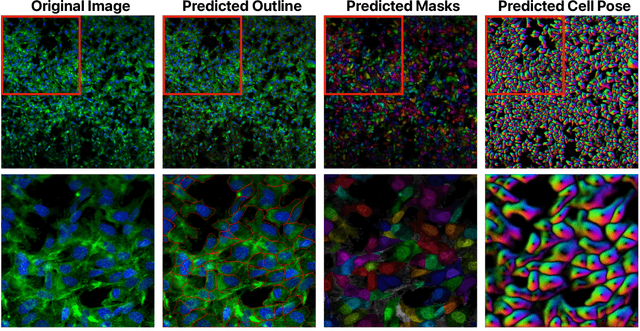
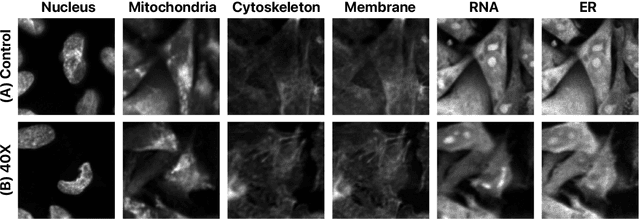
Despite their black-box nature, deep learning models are extensively used in image-based drug discovery to extract feature vectors from single cells in microscopy images. To better understand how these networks perform representation learning, we employ visual explainability techniques (e.g., Grad-CAM). Our analyses reveal several mechanisms by which supervised models cheat, exploiting biologically irrelevant pixels when extracting morphological features from images, such as noise in the background. This raises doubts regarding the fidelity of learned single-cell representations and their relevance when investigating downstream biological questions. To address this misalignment between researcher expectations and machine behavior, we introduce Grad-CAMO, a novel single-cell interpretability score for supervised feature extractors. Grad-CAMO measures the proportion of a model's attention that is concentrated on the cell of interest versus the background. This metric can be assessed per-cell or averaged across a validation set, offering a tool to audit individual features vectors or guide the improved design of deep learning architectures. Importantly, Grad-CAMO seamlessly integrates into existing workflows, requiring no dataset or model modifications, and is compatible with both 2D and 3D Cell Painting data. Additional results are available at https://github.com/eigenvivek/Grad-CAMO.
Intraoperative 2D/3D Image Registration via Differentiable X-ray Rendering
Dec 11, 2023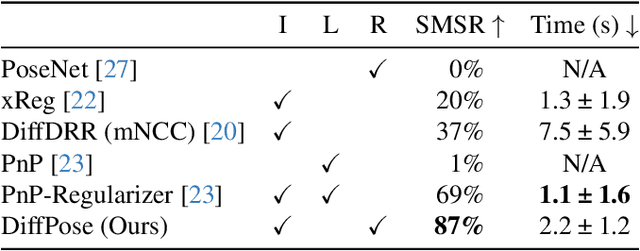
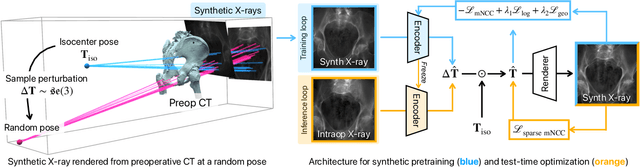
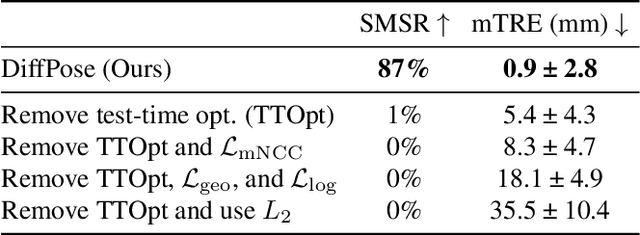
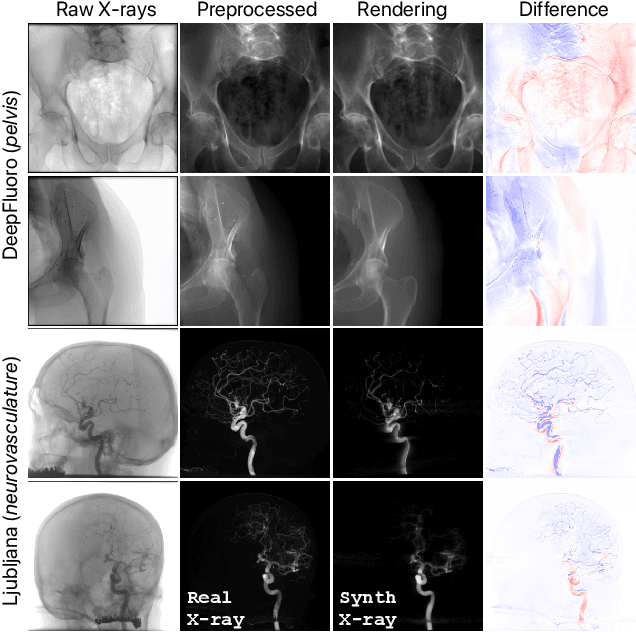
Surgical decisions are informed by aligning rapid portable 2D intraoperative images (e.g., X-rays) to a high-fidelity 3D preoperative reference scan (e.g., CT). 2D/3D image registration often fails in practice: conventional optimization methods are prohibitively slow and susceptible to local minima, while neural networks trained on small datasets fail on new patients or require impractical landmark supervision. We present DiffPose, a self-supervised approach that leverages patient-specific simulation and differentiable physics-based rendering to achieve accurate 2D/3D registration without relying on manually labeled data. Preoperatively, a CNN is trained to regress the pose of a randomly oriented synthetic X-ray rendered from the preoperative CT. The CNN then initializes rapid intraoperative test-time optimization that uses the differentiable X-ray renderer to refine the solution. Our work further proposes several geometrically principled methods for sampling camera poses from $\mathbf{SE}(3)$, for sparse differentiable rendering, and for driving registration in the tangent space $\mathfrak{se}(3)$ with geodesic and multiscale locality-sensitive losses. DiffPose achieves sub-millimeter accuracy across surgical datasets at intraoperative speeds, improving upon existing unsupervised methods by an order of magnitude and even outperforming supervised baselines. Our code is available at https://github.com/eigenvivek/DiffPose.
Fast Auto-Differentiable Digitally Reconstructed Radiographs for Solving Inverse Problems in Intraoperative Imaging
Aug 26, 2022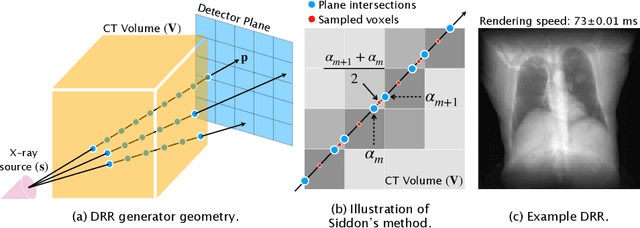
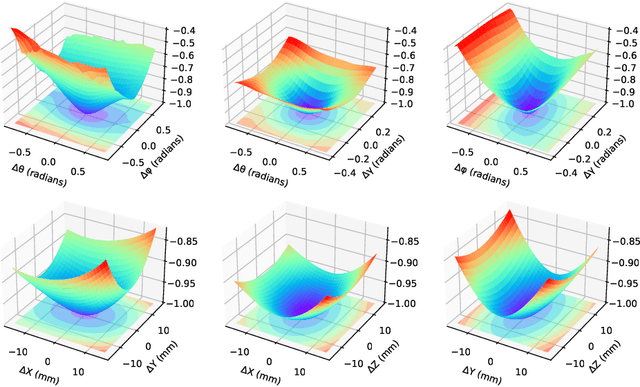
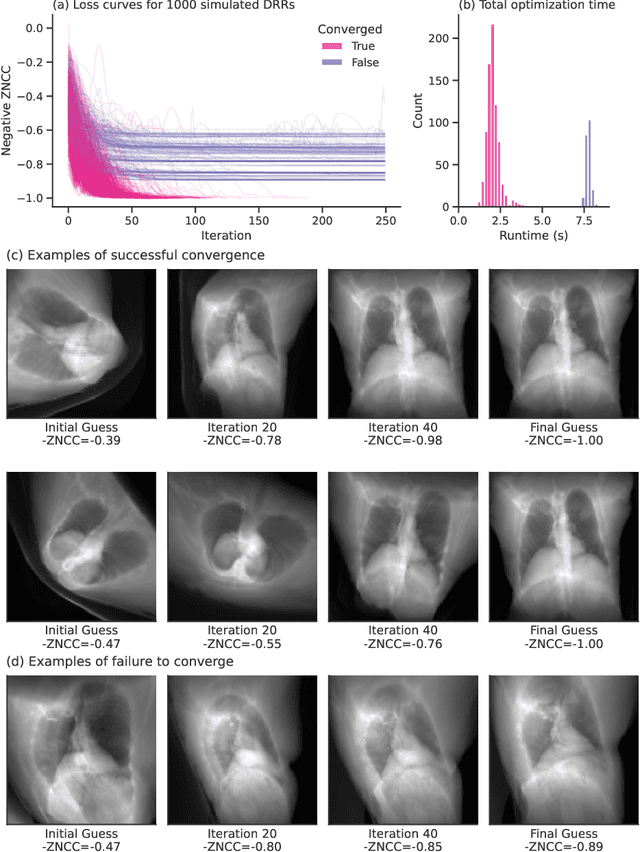
The use of digitally reconstructed radiographs (DRRs) to solve inverse problems such as slice-to-volume registration and 3D reconstruction is well-studied in preoperative settings. In intraoperative imaging, the utility of DRRs is limited by the challenges in generating them in real-time and supporting optimization procedures that rely on repeated DRR synthesis. While immense progress has been made in accelerating the generation of DRRs through algorithmic refinements and GPU implementations, DRR-based optimization remains slow because most DRR generators do not offer a straightforward way to obtain gradients with respect to the imaging parameters. To make DRRs interoperable with gradient-based optimization and deep learning frameworks, we have reformulated Siddon's method, the most popular ray-tracing algorithm used in DRR generation, as a series of vectorized tensor operations. We implemented this vectorized version of Siddon's method in PyTorch, taking advantage of the library's strong automatic differentiation engine to make this DRR generator fully differentiable with respect to its parameters. Additionally, using GPU-accelerated tensor computation enables our vectorized implementation to achieve rendering speeds equivalent to state-of-the-art DRR generators implemented in CUDA and C++. We illustrate the resulting method in the context of slice-to-volume registration. Moreover, our simulations suggest that the loss landscapes for the slice-to-volume registration problem are convex in the neighborhood of the optimal solution, and gradient-based registration promises a much faster solution than prevailing gradient-free optimization strategies. The proposed DRR generator enables fast computer vision algorithms to support image guidance in minimally invasive procedures. Our implementation is publically available at https://github.com/v715/DiffDRR.