 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
Learned HDR Image Compression for Perceptually Optimal Storage and Display
Jul 18, 2024



High dynamic range (HDR) capture and display have seen significant growth in popularity driven by the advancements in technology and increasing consumer demand for superior image quality. As a result, HDR image compression is crucial to fully realize the benefits of HDR imaging without suffering from large file sizes and inefficient data handling. Conventionally, this is achieved by introducing a residual/gain map as additional metadata to bridge the gap between HDR and low dynamic range (LDR) images, making the former compatible with LDR image codecs but offering suboptimal rate-distortion performance. In this work, we initiate efforts towards end-to-end optimized HDR image compression for perceptually optimal storage and display. Specifically, we learn to compress an HDR image into two bitstreams: one for generating an LDR image to ensure compatibility with legacy LDR displays, and another as side information to aid HDR image reconstruction from the output LDR image. To measure the perceptual quality of output HDR and LDR images, we use two recently proposed image distortion metrics, both validated against human perceptual data of image quality and with reference to the uncompressed HDR image. Through end-to-end optimization for rate-distortion performance, our method dramatically improves HDR and LDR image quality at all bit rates.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024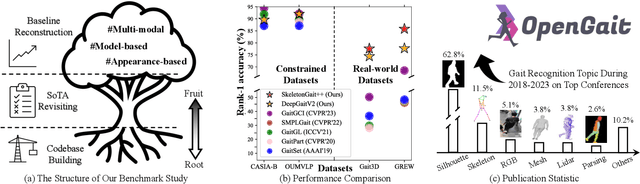
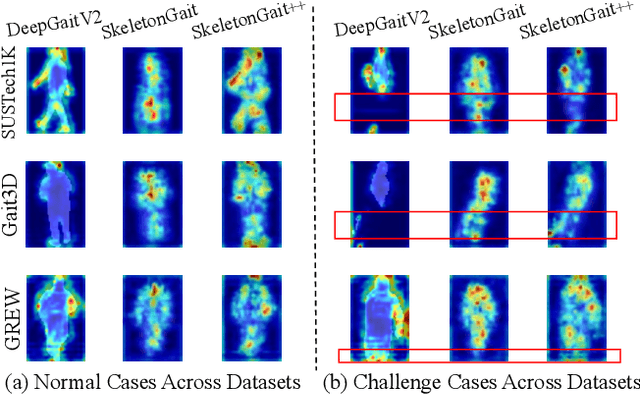
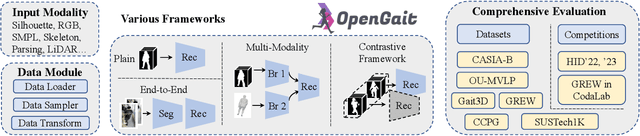
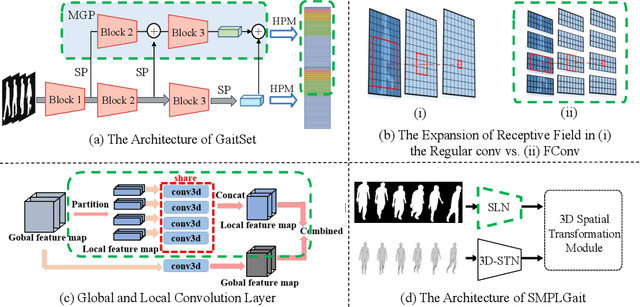
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
Grad-CAMO: Learning Interpretable Single-Cell Morphological Profiles from 3D Cell Painting Images
Mar 26, 2024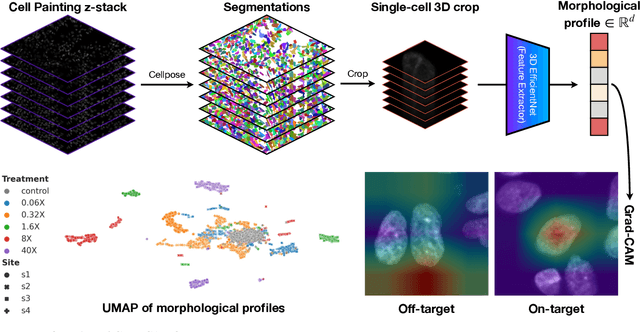
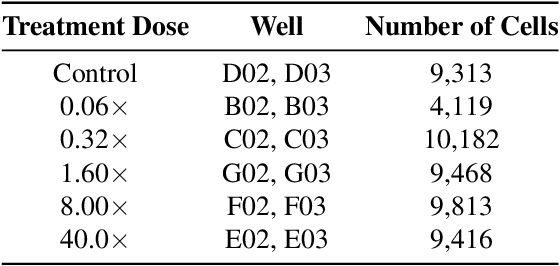
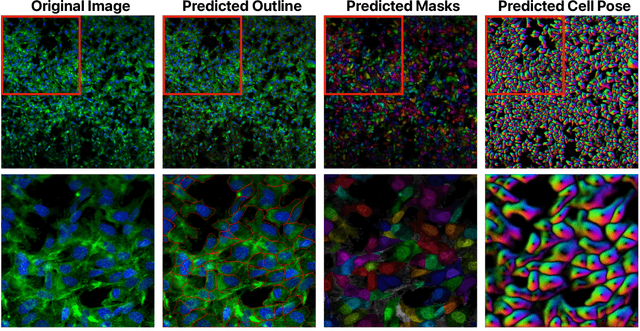
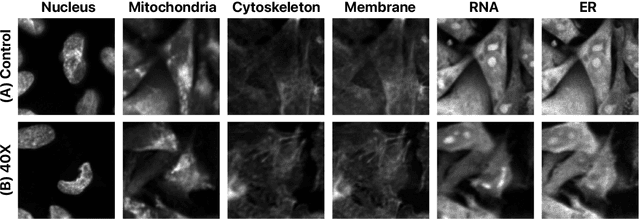
Despite their black-box nature, deep learning models are extensively used in image-based drug discovery to extract feature vectors from single cells in microscopy images. To better understand how these networks perform representation learning, we employ visual explainability techniques (e.g., Grad-CAM). Our analyses reveal several mechanisms by which supervised models cheat, exploiting biologically irrelevant pixels when extracting morphological features from images, such as noise in the background. This raises doubts regarding the fidelity of learned single-cell representations and their relevance when investigating downstream biological questions. To address this misalignment between researcher expectations and machine behavior, we introduce Grad-CAMO, a novel single-cell interpretability score for supervised feature extractors. Grad-CAMO measures the proportion of a model's attention that is concentrated on the cell of interest versus the background. This metric can be assessed per-cell or averaged across a validation set, offering a tool to audit individual features vectors or guide the improved design of deep learning architectures. Importantly, Grad-CAMO seamlessly integrates into existing workflows, requiring no dataset or model modifications, and is compatible with both 2D and 3D Cell Painting data. Additional results are available at https://github.com/eigenvivek/Grad-CAMO.
BigGait: Learning Gait Representation You Want by Large Vision Models
Feb 29, 2024



Gait recognition stands as one of the most pivotal remote identification technologies and progressively expands across research and industrial communities. However, existing gait recognition methods heavily rely on task-specific upstream driven by supervised learning to provide explicit gait representations, which inevitably introduce expensive annotation costs and potentially cause cumulative errors. Escaping from this trend, this work explores effective gait representations based on the all-purpose knowledge produced by task-agnostic Large Vision Models (LVMs) and proposes a simple yet efficient gait framework, termed BigGait. Specifically, the Gait Representation Extractor (GRE) in BigGait effectively transforms all-purpose knowledge into implicit gait features in an unsupervised manner, drawing from design principles of established gait representation construction approaches. Experimental results on CCPG, CAISA-B* and SUSTech1K indicate that BigGait significantly outperforms the previous methods in both self-domain and cross-domain tasks in most cases, and provides a more practical paradigm for learning the next-generation gait representation. Eventually, we delve into prospective challenges and promising directions in LVMs-based gait recognition, aiming to inspire future work in this emerging topic. The source code will be available at https://github.com/ShiqiYu/OpenGait.
SkeletonGait: Gait Recognition Using Skeleton Maps
Nov 22, 2023The choice of the representations is essential for deep gait recognition methods. The binary silhouettes and skeletal coordinates are two dominant representations in recent literature, achieving remarkable advances in many scenarios. However, inherent challenges remain, in which silhouettes are not always guaranteed in unconstrained scenes, and structural cues have not been fully utilized from skeletons. In this paper, we introduce a novel skeletal gait representation named Skeleton Map, together with SkeletonGait, a skeleton-based method to exploit structural information from human skeleton maps. Specifically, the skeleton map represents the coordinates of human joints as a heatmap with Gaussian approximation, exhibiting a silhouette-like image devoid of exact body structure. Beyond achieving state-of-the-art performances over five popular gait datasets, more importantly, SkeletonGait uncovers novel insights about how important structural features are in describing gait and when do they play a role. Furthermore, we propose a multi-branch architecture, named SkeletonGait++, to make use of complementary features from both skeletons and silhouettes. Experiments indicate that SkeletonGait++ outperforms existing state-of-the-art methods by a significant margin in various scenarios. For instance, it achieves an impressive rank-1 accuracy of over $85\%$ on the challenging GREW dataset. All the source code will be available at https://github.com/ShiqiYu/OpenGait.
GaitEditer: Attribute Editing for Gait Representation Learning
Mar 09, 2023Gait pattern is a promising biometric for applications, as it can be captured from a distance without requiring individual cooperation. Nevertheless, existing gait datasets typically suffer from limited diversity, with indoor datasets requiring participants to walk along a fixed route in a restricted setting, and outdoor datasets containing only few walking sequences per subject. Prior generative methods have attempted to mitigate these limitations by building virtual gait datasets. They primarily focus on manipulating a single, specific gait attribute (e.g., viewpoint or carrying), and require the supervised data pairs for training, thus lacking the flexibility and diversity for practical usage. In contrast, our GaitEditer can act as an online module to edit a broad range of gait attributes, such as pants, viewpoint, and even age, in an unsupervised manner, which current gait generative methods struggle with. Additionally, GaitEidter also finely preserves both temporal continuity and identity characteristics in generated gait sequences. Experiments show that GaitEditer provides extensive knowledge for clothing-invariant and view-invariant gait representation learning under various challenging scenarios. The source code will be available.
Human Identity-Preserved Motion Retargeting in Video Synthesis by Feature Disentanglement
Apr 14, 2022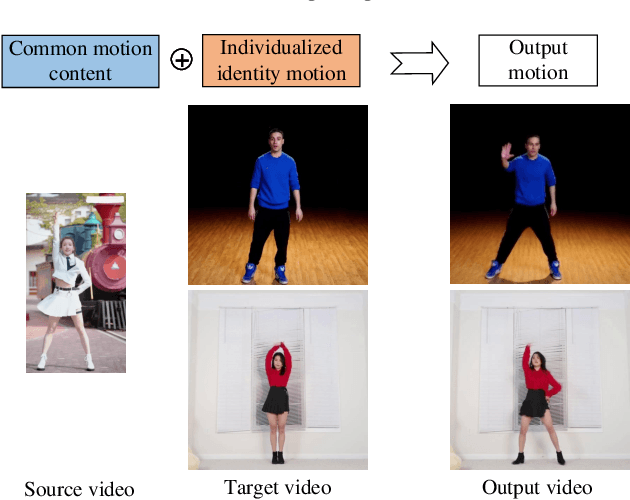

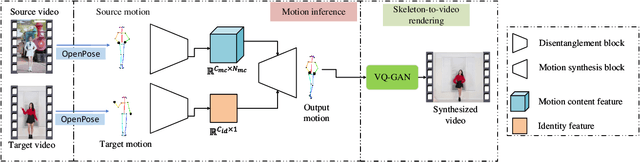
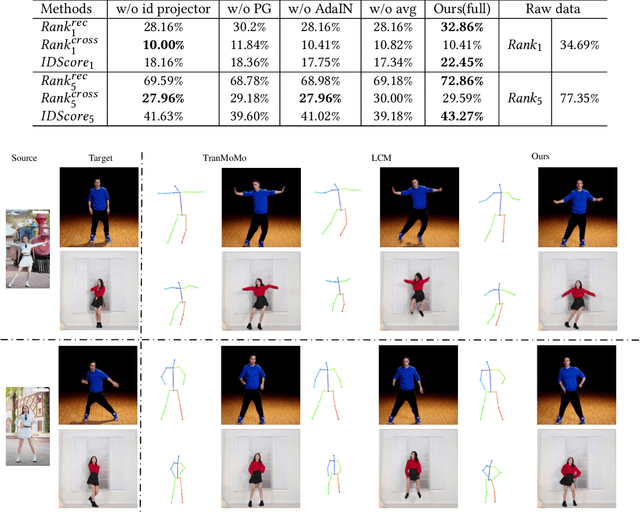
Most motion retargeting methods in human action video synthesis decompose the input video to motion (dynamic information) and shape (static information). However, we observe if the dynamic information is directly transferred to another subject, it will result in unnatural synthesised motion. This phenomenon is mainly caused by neglecting subject-dependent information in motion. To solve the problem, we propose a novel motion retargeting method which can combine both subject-independent (common motion content) information from a source video and subject-dependent (individualized identity motion) information from a target video. So it can synthesize videos with a much natural appearance along with identity-preserved motion. In the proposed method two encoders are employed to extract identity and motion content representations respectively. We employ the adaptive instance normalization (AdaIN) layer in the generator and the instance normalization (IN) layer in the motion content encoder to synthesize the new motion. Besides, we also collected a dataset, named $Chuang101$, with 101 subjects in total. Each subject performs identical dancing movement, and so it is convenient for feature disentanglement among motion and identity of each subject. Furthermore, an efficient quantitative metric for identify information is designed by gait recognition. The experiments show the proposed method can synthesize videos more naturally when the subject's identity is preserved.
Identifying the Absorption Bump with Deep Learning
Nov 20, 2015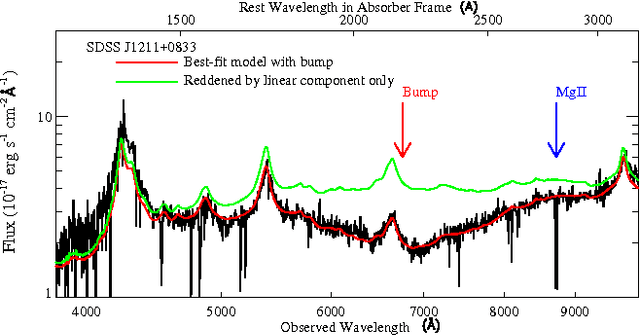
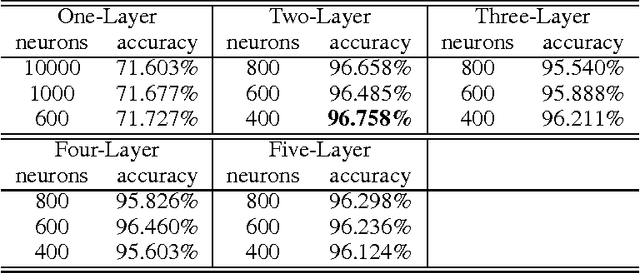
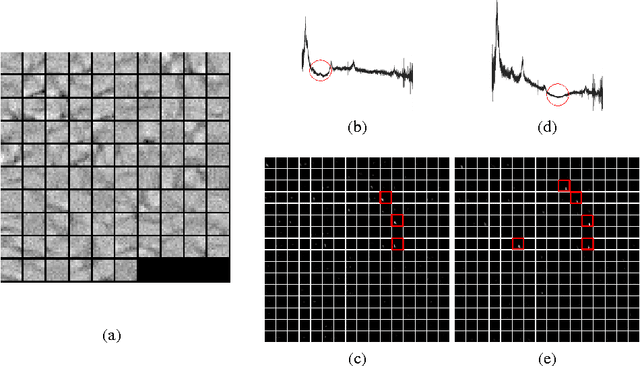
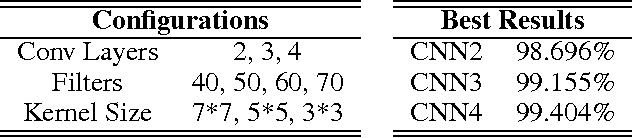
The pervasive interstellar dust grains provide significant insights to understand the formation and evolution of the stars, planetary systems, and the galaxies, and may harbor the building blocks of life. One of the most effective way to analyze the dust is via their interaction with the light from background sources. The observed extinction curves and spectral features carry the size and composition information of dust. The broad absorption bump at 2175 Angstrom is the most prominent feature in the extinction curves. Traditionally, statistical methods are applied to detect the existence of the absorption bump. These methods require heavy preprocessing and the co-existence of other reference features to alleviate the influence from the noises. In this paper, we apply Deep Learning techniques to detect the broad absorption bump. We demonstrate the key steps for training the selected models and their results. The success of Deep Learning based method inspires us to generalize a common methodology for broader science discovery problems. We present our on-going work to build the DeepDis system for such kind of applications.