 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Context Matters: Improving Conditioning for Autoregressive Models
Nov 18, 2025Recently, autoregressive (AR) models have shown strong potential in image generation, offering better scalability and easier integration with unified multi-modal systems compared to diffusion-based methods. However, extending AR models to general image editing remains challenging due to weak and inefficient conditioning, often leading to poor instruction adherence and visual artifacts. To address this, we propose SCAR, a Semantic-Context-driven method for Autoregressive models. SCAR introduces two key components: Compressed Semantic Prefilling, which encodes high-level semantics into a compact and efficient prefix, and Semantic Alignment Guidance, which aligns the last visual hidden states with target semantics during autoregressive decoding to enhance instruction fidelity. Unlike decoding-stage injection methods, SCAR builds upon the flexibility and generality of vector-quantized-based prefilling while overcoming its semantic limitations and high cost. It generalizes across both next-token and next-set AR paradigms with minimal architectural changes. SCAR achieves superior visual fidelity and semantic alignment on both instruction editing and controllable generation benchmarks, outperforming prior AR-based methods while maintaining controllability. All code will be released.
On Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
Exploring More from Multiple Gait Modalities for Human Identification
Dec 16, 2024



The gait, as a kind of soft biometric characteristic, can reflect the distinct walking patterns of individuals at a distance, exhibiting a promising technique for unrestrained human identification. With largely excluding gait-unrelated cues hidden in RGB videos, the silhouette and skeleton, though visually compact, have acted as two of the most prevailing gait modalities for a long time. Recently, several attempts have been made to introduce more informative data forms like human parsing and optical flow images to capture gait characteristics, along with multi-branch architectures. However, due to the inconsistency within model designs and experiment settings, we argue that a comprehensive and fair comparative study among these popular gait modalities, involving the representational capacity and fusion strategy exploration, is still lacking. From the perspectives of fine vs. coarse-grained shape and whole vs. pixel-wise motion modeling, this work presents an in-depth investigation of three popular gait representations, i.e., silhouette, human parsing, and optical flow, with various fusion evaluations, and experimentally exposes their similarities and differences. Based on the obtained insights, we further develop a C$^2$Fusion strategy, consequently building our new framework MultiGait++. C$^2$Fusion preserves commonalities while highlighting differences to enrich the learning of gait features. To verify our findings and conclusions, extensive experiments on Gait3D, GREW, CCPG, and SUSTech1K are conducted. The code is available at https://github.com/ShiqiYu/OpenGait.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024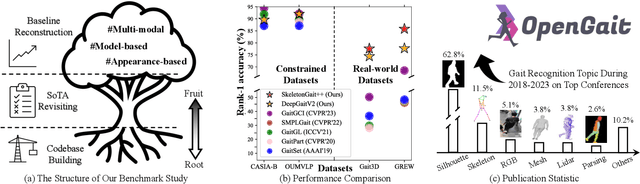
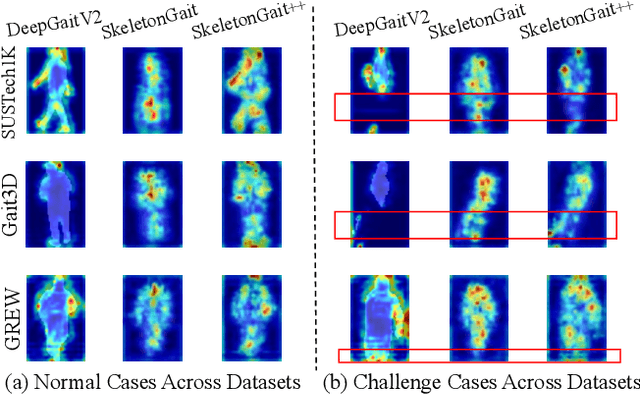
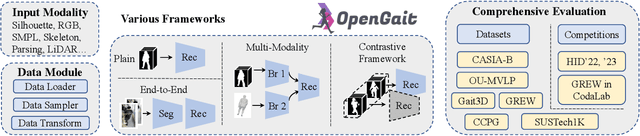
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
SkeletonGait: Gait Recognition Using Skeleton Maps
Nov 22, 2023


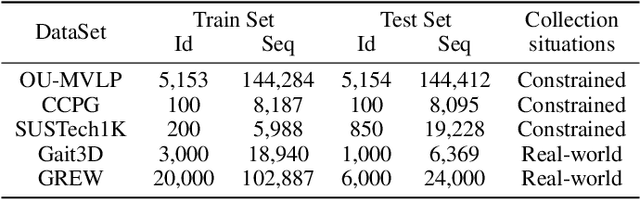
The choice of the representations is essential for deep gait recognition methods. The binary silhouettes and skeletal coordinates are two dominant representations in recent literature, achieving remarkable advances in many scenarios. However, inherent challenges remain, in which silhouettes are not always guaranteed in unconstrained scenes, and structural cues have not been fully utilized from skeletons. In this paper, we introduce a novel skeletal gait representation named Skeleton Map, together with SkeletonGait, a skeleton-based method to exploit structural information from human skeleton maps. Specifically, the skeleton map represents the coordinates of human joints as a heatmap with Gaussian approximation, exhibiting a silhouette-like image devoid of exact body structure. Beyond achieving state-of-the-art performances over five popular gait datasets, more importantly, SkeletonGait uncovers novel insights about how important structural features are in describing gait and when do they play a role. Furthermore, we propose a multi-branch architecture, named SkeletonGait++, to make use of complementary features from both skeletons and silhouettes. Experiments indicate that SkeletonGait++ outperforms existing state-of-the-art methods by a significant margin in various scenarios. For instance, it achieves an impressive rank-1 accuracy of over $85\%$ on the challenging GREW dataset. All the source code will be available at https://github.com/ShiqiYu/OpenGait.
Light field Rectification based on relative pose estimation
Jan 29, 2022



Hand-held light field (LF) cameras have unique advantages in computer vision such as 3D scene reconstruction and depth estimation. However, the related applications are limited by the ultra-small baseline, e.g., leading to the extremely low depth resolution in reconstruction. To solve this problem, we propose to rectify LF to obtain a large baseline. Specifically, the proposed method aligns two LFs captured by two hand-held LF cameras with a random relative pose, and extracts the corresponding row-aligned sub-aperture images (SAIs) to obtain an LF with a large baseline. For an accurate rectification, a method for pose estimation is also proposed, where the relative rotation and translation between the two LF cameras are estimated. The proposed pose estimation minimizes the degree of freedom (DoF) in the LF-point-LF-point correspondence model and explicitly solves this model in a linear way. The proposed pose estimation outperforms the state-of-the-art algorithms by providing more accurate results to support rectification. The significantly improved depth resolution in 3D reconstruction demonstrates the effectiveness of the proposed LF rectification.
A Light Field Camera Calibration Method Using Sub-Aperture Related Bipartition Projection Model and 4D Corner Detection
Jan 11, 2020

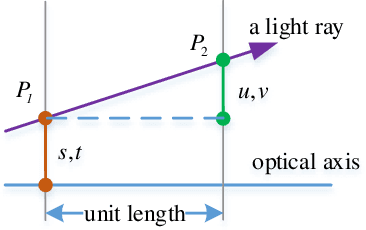
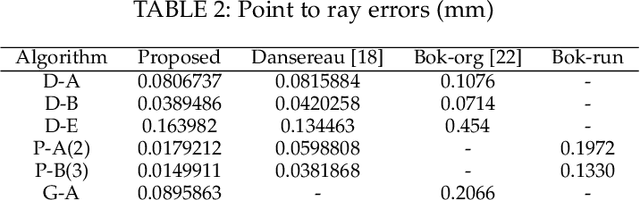
Accurate calibration of intrinsic parameters of the light field (LF) camera is the key issue of many applications, especially of the 3D reconstruction. In this paper, we propose the Sub-Aperture Related Bipartition (SARB) projection model to characterize the LF camera. This projection model is composed with two sets of parameters targeting on center view sub-aperture and relations between sub-apertures. Moreover, we also propose a corner point detection algorithm which fully utilizes the 4D LF information in the raw image. Experimental results have demonstrated the accuracy and robustness of the corner detection method. Both the 2D re-projection errors in the lateral direction and errors in the depth direction are minimized because two sets of parameters in SARB projection model are solved separately.