 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Generalized Gait Recognition: Reducing Redundancy and Noise within Indoor and Outdoor Datasets
May 21, 2025Generalized gait recognition, which aims to achieve robust performance across diverse domains, remains a challenging problem due to severe domain shifts in viewpoints, appearances, and environments. While mixed-dataset training is widely used to enhance generalization, it introduces new obstacles including inter-dataset optimization conflicts and redundant or noisy samples, both of which hinder effective representation learning. To address these challenges, we propose a unified framework that systematically improves cross-domain gait recognition. First, we design a disentangled triplet loss that isolates supervision signals across datasets, mitigating gradient conflicts during optimization. Second, we introduce a targeted dataset distillation strategy that filters out the least informative 20\% of training samples based on feature redundancy and prediction uncertainty, enhancing data efficiency. Extensive experiments on CASIA-B, OU-MVLP, Gait3D, and GREW demonstrate that our method significantly improves cross-dataset recognition for both GaitBase and DeepGaitV2 backbones, without sacrificing source-domain accuracy. Code will be released at https://github.com/li1er3/Generalized_Gait.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024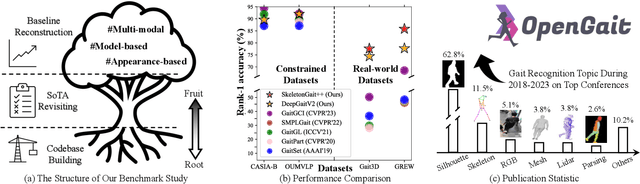
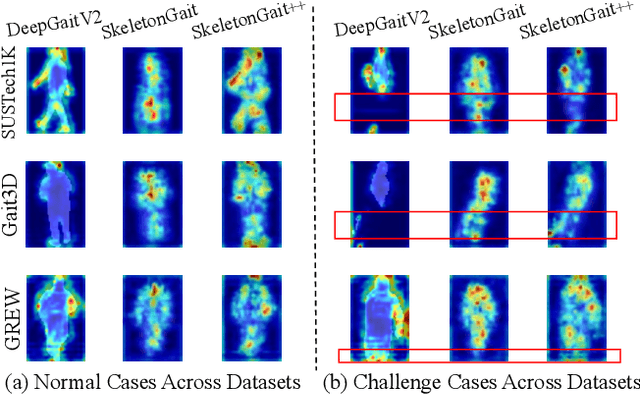
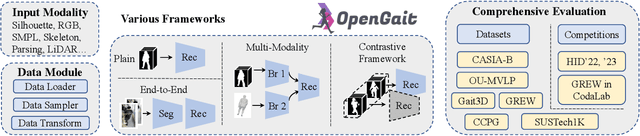
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
Cross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification
Apr 04, 2024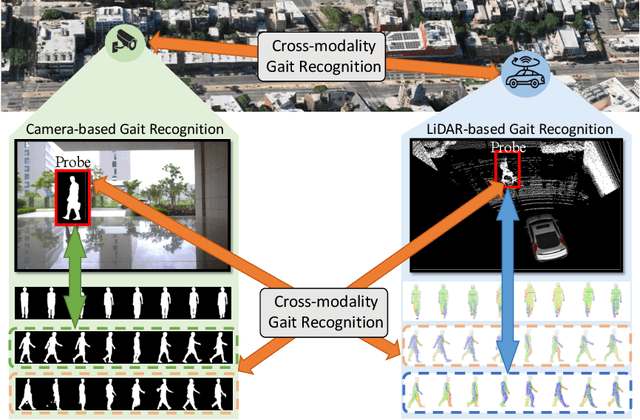



Current gait recognition research mainly focuses on identifying pedestrians captured by the same type of sensor, neglecting the fact that individuals may be captured by different sensors in order to adapt to various environments. A more practical approach should involve cross-modality matching across different sensors. Hence, this paper focuses on investigating the problem of cross-modality gait recognition, with the objective of accurately identifying pedestrians across diverse vision sensors. We present CrossGait inspired by the feature alignment strategy, capable of cross retrieving diverse data modalities. Specifically, we investigate the cross-modality recognition task by initially extracting features within each modality and subsequently aligning these features across modalities. To further enhance the cross-modality performance, we propose a Prototypical Modality-shared Attention Module that learns modality-shared features from two modality-specific features. Additionally, we design a Cross-modality Feature Adapter that transforms the learned modality-specific features into a unified feature space. Extensive experiments conducted on the SUSTech1K dataset demonstrate the effectiveness of CrossGait: (1) it exhibits promising cross-modality ability in retrieving pedestrians across various modalities from different sensors in diverse scenes, and (2) CrossGait not only learns modality-shared features for cross-modality gait recognition but also maintains modality-specific features for single-modality recognition.
Cross-Covariate Gait Recognition: A Benchmark
Jan 05, 2024Gait datasets are essential for gait research. However, this paper observes that present benchmarks, whether conventional constrained or emerging real-world datasets, fall short regarding covariate diversity. To bridge this gap, we undertake an arduous 20-month effort to collect a cross-covariate gait recognition (CCGR) dataset. The CCGR dataset has 970 subjects and about 1.6 million sequences; almost every subject has 33 views and 53 different covariates. Compared to existing datasets, CCGR has both population and individual-level diversity. In addition, the views and covariates are well labeled, enabling the analysis of the effects of different factors. CCGR provides multiple types of gait data, including RGB, parsing, silhouette, and pose, offering researchers a comprehensive resource for exploration. In order to delve deeper into addressing cross-covariate gait recognition, we propose parsing-based gait recognition (ParsingGait) by utilizing the newly proposed parsing data. We have conducted extensive experiments. Our main results show: 1) Cross-covariate emerges as a pivotal challenge for practical applications of gait recognition. 2) ParsingGait demonstrates remarkable potential for further advancement. 3) Alarmingly, existing SOTA methods achieve less than 43% accuracy on the CCGR, highlighting the urgency of exploring cross-covariate gait recognition. Link: https://github.com/ShinanZou/CCGR.
* This paper has been accepted by AAAI2024
SkeletonGait: Gait Recognition Using Skeleton Maps
Nov 22, 2023The choice of the representations is essential for deep gait recognition methods. The binary silhouettes and skeletal coordinates are two dominant representations in recent literature, achieving remarkable advances in many scenarios. However, inherent challenges remain, in which silhouettes are not always guaranteed in unconstrained scenes, and structural cues have not been fully utilized from skeletons. In this paper, we introduce a novel skeletal gait representation named Skeleton Map, together with SkeletonGait, a skeleton-based method to exploit structural information from human skeleton maps. Specifically, the skeleton map represents the coordinates of human joints as a heatmap with Gaussian approximation, exhibiting a silhouette-like image devoid of exact body structure. Beyond achieving state-of-the-art performances over five popular gait datasets, more importantly, SkeletonGait uncovers novel insights about how important structural features are in describing gait and when do they play a role. Furthermore, we propose a multi-branch architecture, named SkeletonGait++, to make use of complementary features from both skeletons and silhouettes. Experiments indicate that SkeletonGait++ outperforms existing state-of-the-art methods by a significant margin in various scenarios. For instance, it achieves an impressive rank-1 accuracy of over $85\%$ on the challenging GREW dataset. All the source code will be available at https://github.com/ShiqiYu/OpenGait.
OpenGait: Revisiting Gait Recognition Toward Better Practicality
Nov 19, 2022Gait recognition is one of the most important long-distance identification technologies and increasingly gains popularity in both research and industry communities. Although significant progress has been made in indoor datasets, much evidence shows that gait recognition techniques perform poorly in the wild. More importantly, we also find that many conclusions from prior works change with the evaluation datasets. Therefore, the more critical goal of this paper is to present a comprehensive benchmark study for better practicality rather than only a particular model for better performance. To this end, we first develop a flexible and efficient gait recognition codebase named OpenGait. Based on OpenGait, we deeply revisit the recent development of gait recognition by re-conducting the ablative experiments. Encouragingly, we find many hidden troubles of prior works and new insights for future research. Inspired by these discoveries, we develop a structurally simple, empirically powerful and practically robust baseline model, GaitBase. Experimentally, we comprehensively compare GaitBase with many current gait recognition methods on multiple public datasets, and the results reflect that GaitBase achieves significantly strong performance in most cases regardless of indoor or outdoor situations. The source code is available at \url{https://github.com/ShiqiYu/OpenGait}.
LIDAR GAIT: Benchmarking 3D Gait Recognition with Point Clouds
Nov 19, 2022Video-based gait recognition has achieved impressive results in constrained scenarios. However, visual cameras neglect human 3D structure information, which limits the feasibility of gait recognition in the 3D wild world. In this work, instead of extracting gait features from images, we explore precise 3D gait features from point clouds and propose a simple yet efficient 3D gait recognition framework, termed multi-view projection network (MVPNet). MVPNet first projects point clouds into multiple depth maps from different perspectives, and then fuse depth images together, to learn the compact representation with 3D geometry information. Due to the lack of point cloud datasets, we build the first large-scale Lidar-based gait recognition dataset, LIDAR GAIT, collected by a Lidar sensor and an RGB camera mounted on a robot. The dataset contains 25,279 sequences from 1,050 subjects and covers many different variations, including visibility, views, occlusions, clothing, carrying, and scenes. Extensive experiments show that, (1) 3D structure information serves as a significant feature for gait recognition. (2) MVPNet not only competes with five representative point-based methods, but it also outperforms existing camera-based methods by large margins. (3) The Lidar sensor is superior to the RGB camera for gait recognition in the wild. LIDAR GAIT dataset and MVPNet code will be publicly available.
A Comprehensive Survey on Deep Gait Recognition: Algorithms, Datasets and Challenges
Jun 28, 2022


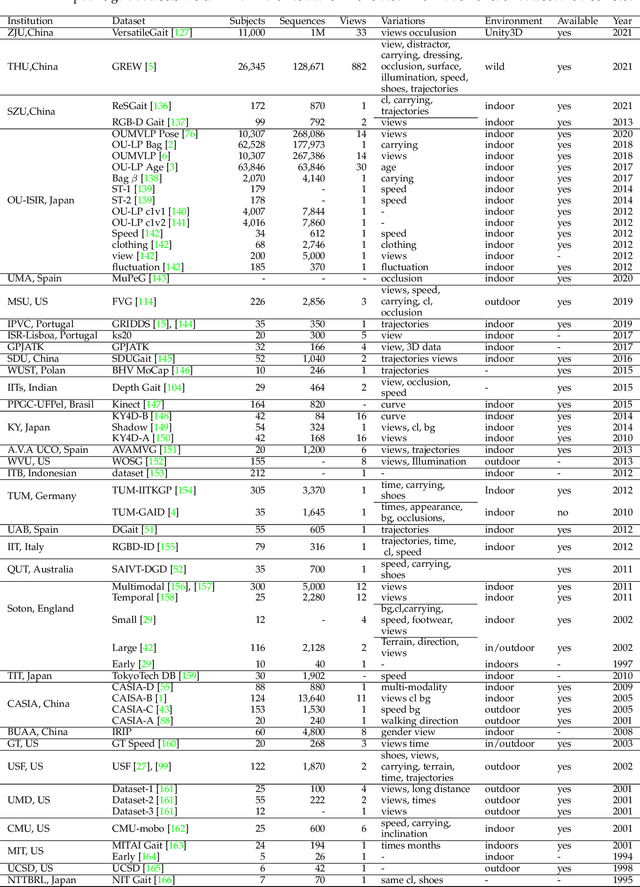
Gait recognition aims at identifying a person at a distance through visual cameras. With the emergence of deep learning, significant advancements in gait recognition have achieved inspiring success in many scenarios by utilizing deep learning techniques. Nevertheless, the increasing need for video surveillance introduces more challenges, including robust recognition under various variances, modeling motion information in gait sequences, unfair performance comparison due to protocol variances, biometrics security, and privacy prevention. This paper provides a comprehensive survey of deep learning for gait recognition. We first present the odyssey of gait recognition from traditional algorithms to deep models, providing explicit knowledge of the whole workflow of a gait recognition system. Then deep learning for gait recognition is discussed from the perspective of deep representations and architecture with an in-depth summary. Specifically, deep gait representations are categorized into static and dynamic features, while deep architectures include single-stream and multi-stream architecture. Following our proposed taxonomy with novelty, it can be beneficial for providing inspiration and promoting the perception of deep gait recognition. Besides, we also present a comprehensive summary of all vision-based gait datasets and the performance analysis. Finally, the article discusses some open issues with significant potential prospects.
Gait Recognition with Mask-based Regularization
Mar 08, 2022


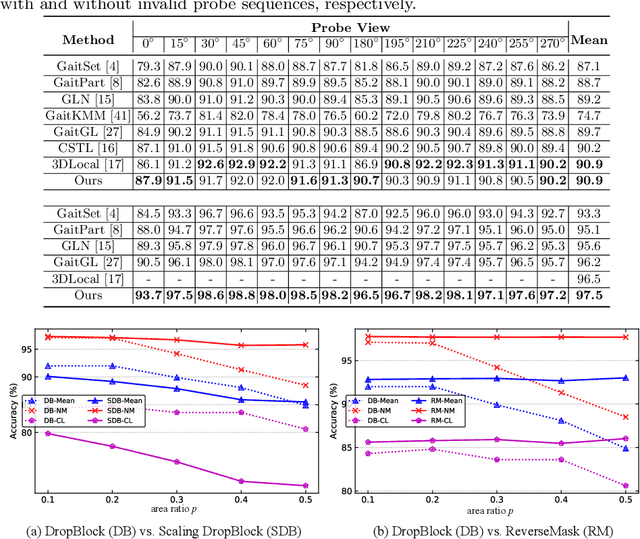
Most gait recognition methods exploit spatial-temporal representations from static appearances and dynamic walking patterns. However, we observe that many part-based methods neglect representations at boundaries. In addition, the phenomenon of overfitting on training data is relatively common in gait recognition, which is perhaps due to insufficient data and low-informative gait silhouettes. Motivated by these observations, we propose a novel mask-based regularization method named ReverseMask. By injecting perturbation on the feature map, the proposed regularization method helps convolutional architecture learn the discriminative representations and enhances generalization. Also, we design an Inception-like ReverseMask Block, which has three branches composed of a global branch, a feature dropping branch, and a feature scaling branch. Precisely, the dropping branch can extract fine-grained representations when partial activations are zero-outed. Meanwhile, the scaling branch randomly scales the feature map, keeping structural information of activations and preventing overfitting. The plug-and-play Inception-like ReverseMask block is simple and effective to generalize networks, and it also improves the performance of many state-of-the-art methods. Extensive experiments demonstrate that the ReverseMask regularization help baseline achieves higher accuracy and better generalization. Moreover, the baseline with Inception-like Block significantly outperforms state-of-the-art methods on the two most popular datasets, CASIA-B and OUMVLP. The source code will be released.
GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality
Mar 08, 2022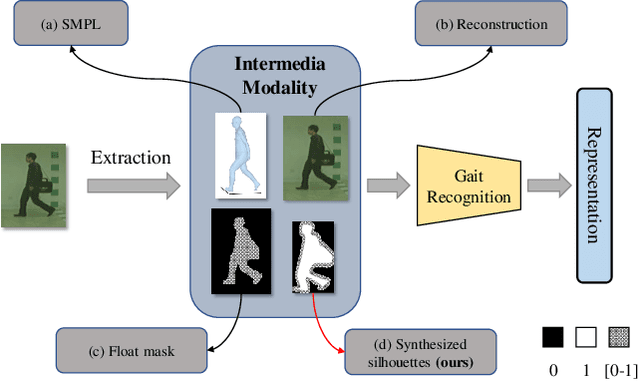
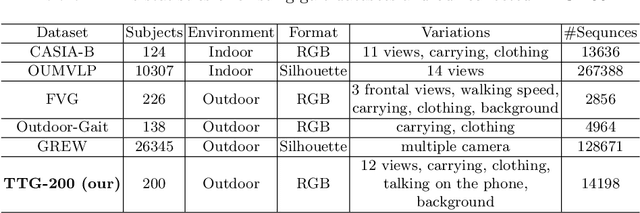
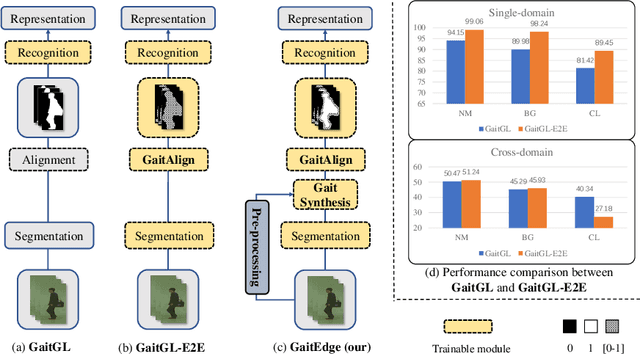
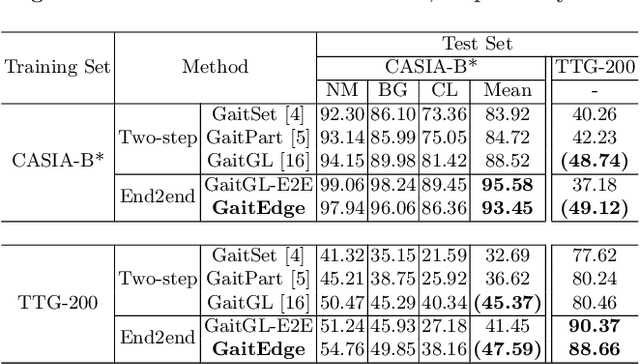
Gait is one of the most promising biometrics to identify individuals at a long distance. Although most previous methods have focused on recognizing the silhouettes, several end-to-end methods that extract gait features directly from RGB images perform better. However, we argue that these end-to-end methods inevitably suffer from the gait-unrelated noises, i.e., low-level texture and colorful information. Experimentally, we design both the cross-domain evaluation and visualization to stand for this view. In this work, we propose a novel end-to-end framework named GaitEdge which can effectively block gait-unrelated information and release end-to-end training potential. Specifically, GaitEdge synthesizes the output of the pedestrian segmentation network and then feeds it to the subsequent recognition network, where the synthetic silhouettes consist of trainable edges of bodies and fixed interiors to limit the information that the recognition network receives. Besides, GaitAlign for aligning silhouettes is embedded into the GaitEdge without loss of differentiability. Experimental results on CASIA-B and our newly built TTG-200 indicate that GaitEdge significantly outperforms the previous methods and provides a more practical end-to-end paradigm for blocking RGB noises effectively. All the source code will be released.