 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Customized Fashion Design with Image-into-Prompt benchmark and dataset from LMM
Sep 11, 2025Generative AI evolves the execution of complex workflows in industry, where the large multimodal model empowers fashion design in the garment industry. Current generation AI models magically transform brainstorming into fancy designs easily, but the fine-grained customization still suffers from text uncertainty without professional background knowledge from end-users. Thus, we propose the Better Understanding Generation (BUG) workflow with LMM to automatically create and fine-grain customize the cloth designs from chat with image-into-prompt. Our framework unleashes users' creative potential beyond words and also lowers the barriers of clothing design/editing without further human involvement. To prove the effectiveness of our model, we propose a new FashionEdit dataset that simulates the real-world clothing design workflow, evaluated from generation similarity, user satisfaction, and quality. The code and dataset: https://github.com/detectiveli/FashionEdit.
Distributed optimization: designed for federated learning
Aug 12, 2025Federated Learning (FL), as a distributed collaborative Machine Learning (ML) framework under privacy-preserving constraints, has garnered increasing research attention in cross-organizational data collaboration scenarios. This paper proposes a class of distributed optimization algorithms based on the augmented Lagrangian technique, designed to accommodate diverse communication topologies in both centralized and decentralized FL settings. Furthermore, we develop multiple termination criteria and parameter update mechanisms to enhance computational efficiency, accompanied by rigorous theoretical guarantees of convergence. By generalizing the augmented Lagrangian relaxation through the incorporation of proximal relaxation and quadratic approximation, our framework systematically recovers a broad of classical unconstrained optimization methods, including proximal algorithm, classic gradient descent, and stochastic gradient descent, among others. Notably, the convergence properties of these methods can be naturally derived within the proposed theoretical framework. Numerical experiments demonstrate that the proposed algorithm exhibits strong performance in large-scale settings with significant statistical heterogeneity across clients.
Cross-Modality Gait Recognition: Bridging LiDAR and Camera Modalities for Human Identification
Apr 04, 2024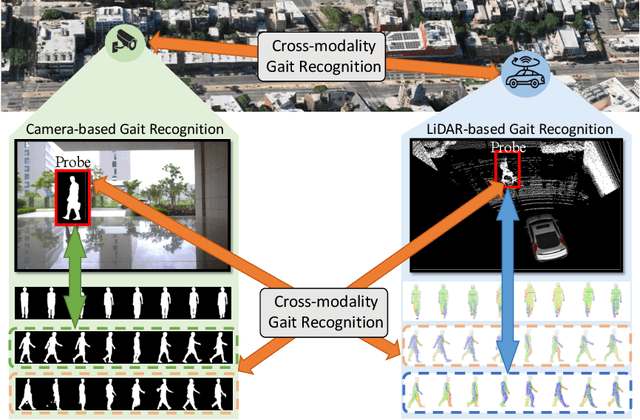



Current gait recognition research mainly focuses on identifying pedestrians captured by the same type of sensor, neglecting the fact that individuals may be captured by different sensors in order to adapt to various environments. A more practical approach should involve cross-modality matching across different sensors. Hence, this paper focuses on investigating the problem of cross-modality gait recognition, with the objective of accurately identifying pedestrians across diverse vision sensors. We present CrossGait inspired by the feature alignment strategy, capable of cross retrieving diverse data modalities. Specifically, we investigate the cross-modality recognition task by initially extracting features within each modality and subsequently aligning these features across modalities. To further enhance the cross-modality performance, we propose a Prototypical Modality-shared Attention Module that learns modality-shared features from two modality-specific features. Additionally, we design a Cross-modality Feature Adapter that transforms the learned modality-specific features into a unified feature space. Extensive experiments conducted on the SUSTech1K dataset demonstrate the effectiveness of CrossGait: (1) it exhibits promising cross-modality ability in retrieving pedestrians across various modalities from different sensors in diverse scenes, and (2) CrossGait not only learns modality-shared features for cross-modality gait recognition but also maintains modality-specific features for single-modality recognition.
LIDAR GAIT: Benchmarking 3D Gait Recognition with Point Clouds
Nov 19, 2022Video-based gait recognition has achieved impressive results in constrained scenarios. However, visual cameras neglect human 3D structure information, which limits the feasibility of gait recognition in the 3D wild world. In this work, instead of extracting gait features from images, we explore precise 3D gait features from point clouds and propose a simple yet efficient 3D gait recognition framework, termed multi-view projection network (MVPNet). MVPNet first projects point clouds into multiple depth maps from different perspectives, and then fuse depth images together, to learn the compact representation with 3D geometry information. Due to the lack of point cloud datasets, we build the first large-scale Lidar-based gait recognition dataset, LIDAR GAIT, collected by a Lidar sensor and an RGB camera mounted on a robot. The dataset contains 25,279 sequences from 1,050 subjects and covers many different variations, including visibility, views, occlusions, clothing, carrying, and scenes. Extensive experiments show that, (1) 3D structure information serves as a significant feature for gait recognition. (2) MVPNet not only competes with five representative point-based methods, but it also outperforms existing camera-based methods by large margins. (3) The Lidar sensor is superior to the RGB camera for gait recognition in the wild. LIDAR GAIT dataset and MVPNet code will be publicly available.
A Comprehensive Survey on Deep Gait Recognition: Algorithms, Datasets and Challenges
Jun 28, 2022


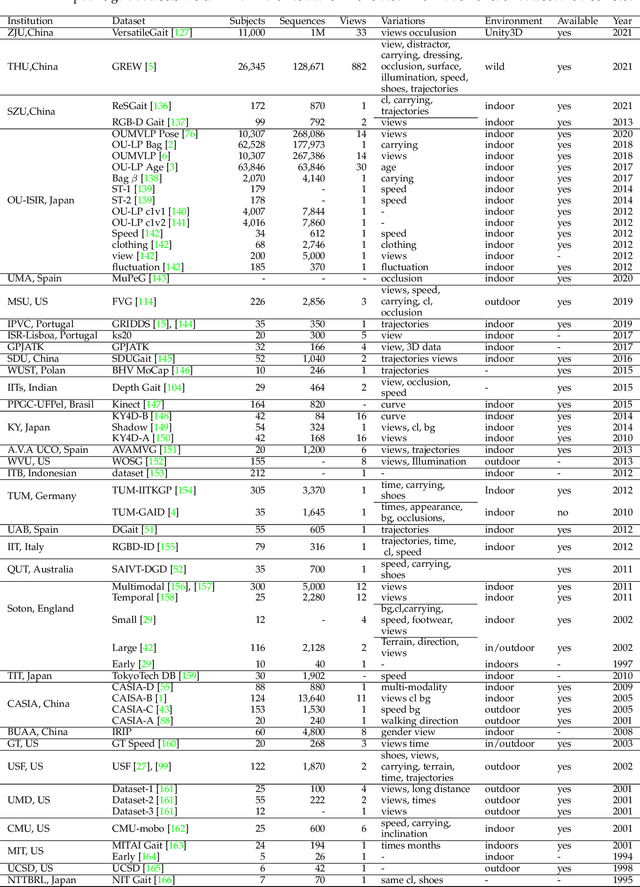
Gait recognition aims at identifying a person at a distance through visual cameras. With the emergence of deep learning, significant advancements in gait recognition have achieved inspiring success in many scenarios by utilizing deep learning techniques. Nevertheless, the increasing need for video surveillance introduces more challenges, including robust recognition under various variances, modeling motion information in gait sequences, unfair performance comparison due to protocol variances, biometrics security, and privacy prevention. This paper provides a comprehensive survey of deep learning for gait recognition. We first present the odyssey of gait recognition from traditional algorithms to deep models, providing explicit knowledge of the whole workflow of a gait recognition system. Then deep learning for gait recognition is discussed from the perspective of deep representations and architecture with an in-depth summary. Specifically, deep gait representations are categorized into static and dynamic features, while deep architectures include single-stream and multi-stream architecture. Following our proposed taxonomy with novelty, it can be beneficial for providing inspiration and promoting the perception of deep gait recognition. Besides, we also present a comprehensive summary of all vision-based gait datasets and the performance analysis. Finally, the article discusses some open issues with significant potential prospects.
Gait Recognition with Mask-based Regularization
Mar 08, 2022


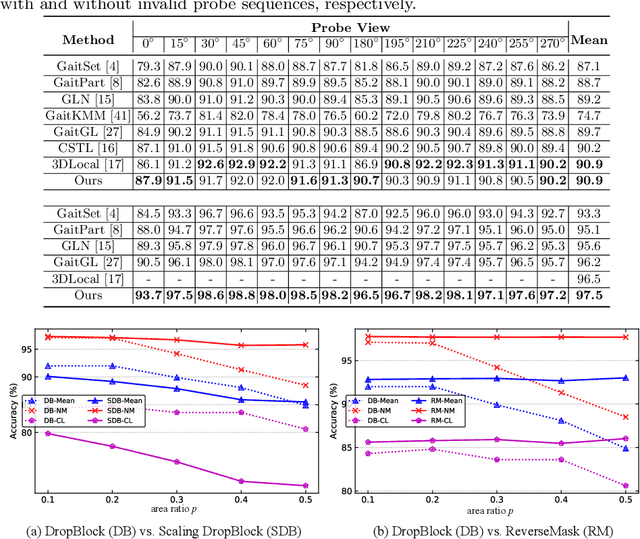
Most gait recognition methods exploit spatial-temporal representations from static appearances and dynamic walking patterns. However, we observe that many part-based methods neglect representations at boundaries. In addition, the phenomenon of overfitting on training data is relatively common in gait recognition, which is perhaps due to insufficient data and low-informative gait silhouettes. Motivated by these observations, we propose a novel mask-based regularization method named ReverseMask. By injecting perturbation on the feature map, the proposed regularization method helps convolutional architecture learn the discriminative representations and enhances generalization. Also, we design an Inception-like ReverseMask Block, which has three branches composed of a global branch, a feature dropping branch, and a feature scaling branch. Precisely, the dropping branch can extract fine-grained representations when partial activations are zero-outed. Meanwhile, the scaling branch randomly scales the feature map, keeping structural information of activations and preventing overfitting. The plug-and-play Inception-like ReverseMask block is simple and effective to generalize networks, and it also improves the performance of many state-of-the-art methods. Extensive experiments demonstrate that the ReverseMask regularization help baseline achieves higher accuracy and better generalization. Moreover, the baseline with Inception-like Block significantly outperforms state-of-the-art methods on the two most popular datasets, CASIA-B and OUMVLP. The source code will be released.