 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstantHDR: Single-forward Gaussian Splatting for High Dynamic Range 3D Reconstruction
Mar 11, 2026High dynamic range (HDR) novel view synthesis (NVS) aims to reconstruct HDR scenes from multi-exposure low dynamic range (LDR) images. Existing HDR pipelines heavily rely on known camera poses, well-initialized dense point clouds, and time-consuming per-scene optimization. Current feed-forward alternatives overlook the HDR problem by assuming exposure-invariant appearance. To bridge this gap, we propose InstantHDR, a feed-forward network that reconstructs 3D HDR scenes from uncalibrated multi-exposure LDR collections in a single forward pass. Specifically, we design a geometry-guided appearance modeling for multi-exposure fusion, and a meta-network for generalizable scene-specific tone mapping. Due to the lack of HDR scene data, we build a pre-training dataset, called HDR-Pretrain, for generalizable feed-forward HDR models, featuring 168 Blender-rendered scenes, diverse lighting types, and multiple camera response functions. Comprehensive experiments show that our InstantHDR delivers comparable synthesis performance to the state-of-the-art optimization-based HDR methods while enjoying $\sim700\times$ and $\sim20\times$ reconstruction speed improvement with our single-forward and post-optimization settings. All code, models, and datasets will be released after the review process.
On Denoising Walking Videos for Gait Recognition
May 24, 2025To capture individual gait patterns, excluding identity-irrelevant cues in walking videos, such as clothing texture and color, remains a persistent challenge for vision-based gait recognition. Traditional silhouette- and pose-based methods, though theoretically effective at removing such distractions, often fall short of high accuracy due to their sparse and less informative inputs. Emerging end-to-end methods address this by directly denoising RGB videos using human priors. Building on this trend, we propose DenoisingGait, a novel gait denoising method. Inspired by the philosophy that "what I cannot create, I do not understand", we turn to generative diffusion models, uncovering how they partially filter out irrelevant factors for gait understanding. Additionally, we introduce a geometry-driven Feature Matching module, which, combined with background removal via human silhouettes, condenses the multi-channel diffusion features at each foreground pixel into a two-channel direction vector. Specifically, the proposed within- and cross-frame matching respectively capture the local vectorized structures of gait appearance and motion, producing a novel flow-like gait representation termed Gait Feature Field, which further reduces residual noise in diffusion features. Experiments on the CCPG, CASIA-B*, and SUSTech1K datasets demonstrate that DenoisingGait achieves a new SoTA performance in most cases for both within- and cross-domain evaluations. Code is available at https://github.com/ShiqiYu/OpenGait.
BiggerGait: Unlocking Gait Recognition with Layer-wise Representations from Large Vision Models
May 23, 2025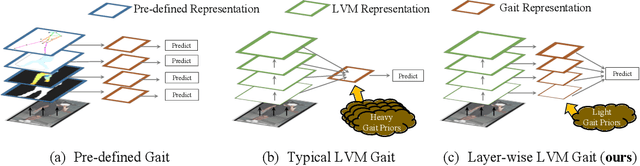
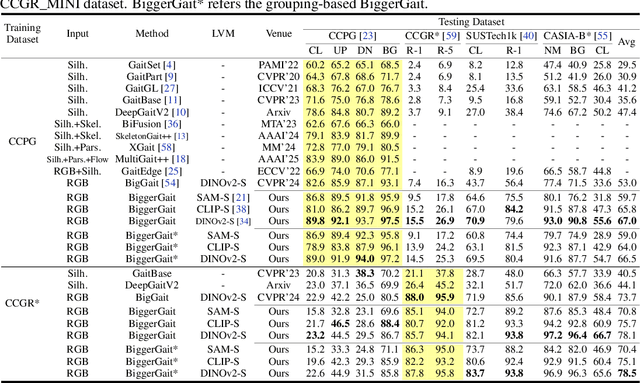
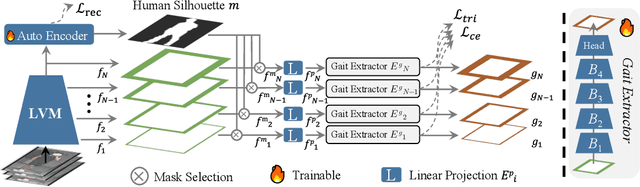
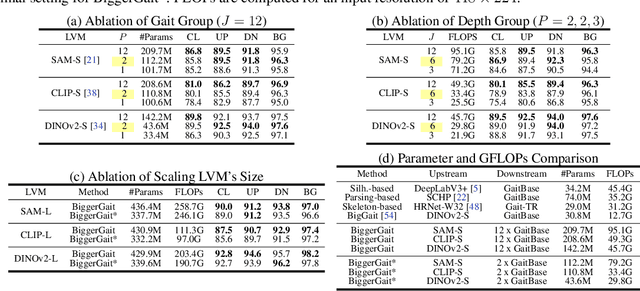
Large vision models (LVM) based gait recognition has achieved impressive performance. However, existing LVM-based approaches may overemphasize gait priors while neglecting the intrinsic value of LVM itself, particularly the rich, distinct representations across its multi-layers. To adequately unlock LVM's potential, this work investigates the impact of layer-wise representations on downstream recognition tasks. Our analysis reveals that LVM's intermediate layers offer complementary properties across tasks, integrating them yields an impressive improvement even without rich well-designed gait priors. Building on this insight, we propose a simple and universal baseline for LVM-based gait recognition, termed BiggerGait. Comprehensive evaluations on CCPG, CAISA-B*, SUSTech1K, and CCGR\_MINI validate the superiority of BiggerGait across both within- and cross-domain tasks, establishing it as a simple yet practical baseline for gait representation learning. All the models and code will be publicly available.
RealisDance-DiT: Simple yet Strong Baseline towards Controllable Character Animation in the Wild
Apr 21, 2025
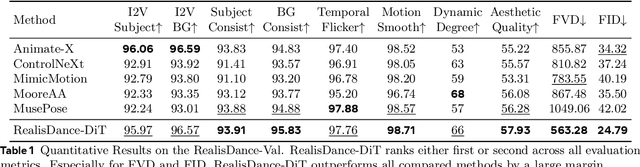

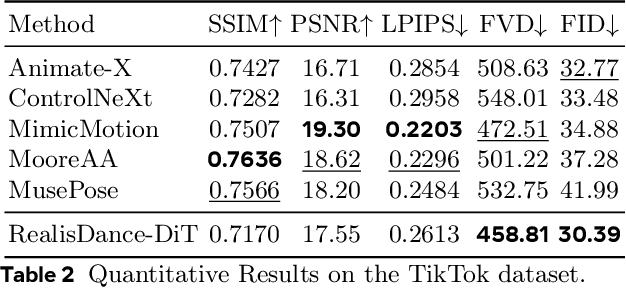
Controllable character animation remains a challenging problem, particularly in handling rare poses, stylized characters, character-object interactions, complex illumination, and dynamic scenes. To tackle these issues, prior work has largely focused on injecting pose and appearance guidance via elaborate bypass networks, but often struggles to generalize to open-world scenarios. In this paper, we propose a new perspective that, as long as the foundation model is powerful enough, straightforward model modifications with flexible fine-tuning strategies can largely address the above challenges, taking a step towards controllable character animation in the wild. Specifically, we introduce RealisDance-DiT, built upon the Wan-2.1 video foundation model. Our sufficient analysis reveals that the widely adopted Reference Net design is suboptimal for large-scale DiT models. Instead, we demonstrate that minimal modifications to the foundation model architecture yield a surprisingly strong baseline. We further propose the low-noise warmup and "large batches and small iterations" strategies to accelerate model convergence during fine-tuning while maximally preserving the priors of the foundation model. In addition, we introduce a new test dataset that captures diverse real-world challenges, complementing existing benchmarks such as TikTok dataset and UBC fashion video dataset, to comprehensively evaluate the proposed method. Extensive experiments show that RealisDance-DiT outperforms existing methods by a large margin.
ErgoChat: a Visual Query System for the Ergonomic Risk Assessment of Construction Workers
Dec 27, 2024



In the construction sector, workers often endure prolonged periods of high-intensity physical work and prolonged use of tools, resulting in injuries and illnesses primarily linked to postural ergonomic risks, a longstanding predominant health concern. To mitigate these risks, researchers have applied various technological methods to identify the ergonomic risks that construction workers face. However, traditional ergonomic risk assessment (ERA) techniques do not offer interactive feedback. The rapidly developing vision-language models (VLMs), capable of generating textual descriptions or answering questions about ergonomic risks based on image inputs, have not yet received widespread attention. This research introduces an interactive visual query system tailored to assess the postural ergonomic risks of construction workers. The system's capabilities include visual question answering (VQA), which responds to visual queries regarding workers' exposure to postural ergonomic risks, and image captioning (IC), which generates textual descriptions of these risks from images. Additionally, this study proposes a dataset designed for training and testing such methodologies. Systematic testing indicates that the VQA functionality delivers an accuracy of 96.5%. Moreover, evaluations using nine metrics for IC and assessments from human experts indicate that the proposed approach surpasses the performance of a method using the same architecture trained solely on generic datasets. This study sets a new direction for future developments in interactive ERA using generative artificial intelligence (AI) technologies.
Exploring More from Multiple Gait Modalities for Human Identification
Dec 16, 2024



The gait, as a kind of soft biometric characteristic, can reflect the distinct walking patterns of individuals at a distance, exhibiting a promising technique for unrestrained human identification. With largely excluding gait-unrelated cues hidden in RGB videos, the silhouette and skeleton, though visually compact, have acted as two of the most prevailing gait modalities for a long time. Recently, several attempts have been made to introduce more informative data forms like human parsing and optical flow images to capture gait characteristics, along with multi-branch architectures. However, due to the inconsistency within model designs and experiment settings, we argue that a comprehensive and fair comparative study among these popular gait modalities, involving the representational capacity and fusion strategy exploration, is still lacking. From the perspectives of fine vs. coarse-grained shape and whole vs. pixel-wise motion modeling, this work presents an in-depth investigation of three popular gait representations, i.e., silhouette, human parsing, and optical flow, with various fusion evaluations, and experimentally exposes their similarities and differences. Based on the obtained insights, we further develop a C$^2$Fusion strategy, consequently building our new framework MultiGait++. C$^2$Fusion preserves commonalities while highlighting differences to enrich the learning of gait features. To verify our findings and conclusions, extensive experiments on Gait3D, GREW, CCPG, and SUSTech1K are conducted. The code is available at https://github.com/ShiqiYu/OpenGait.
SliceMamba for Medical Image Segmentation
Jul 11, 2024



Despite the progress made in Mamba-based medical image segmentation models, current methods utilizing unidirectional or multi-directional feature scanning mechanisms fail to well model dependencies between neighboring positions in the image, hindering the effective modeling of local features. However, local features are crucial for medical image segmentation as they provide vital information about lesions and tissue structures. To address this limitation, we propose a simple yet effective method named SliceMamba, a locally sensitive pure Mamba medical image segmentation model. The proposed SliceMamba includes an efffcient Bidirectional Slice Scan module (BSS), which performs bidirectional feature segmentation while employing varied scanning mechanisms for distinct features. This ensures that spatially adjacent features maintain proximity in the scanning sequence, thereby enhancing segmentation performance. Extensive experiments on skin lesion and polyp segmentation datasets validate the effectiveness of our method.
Gait Patterns as Biomarkers: A Video-Based Approach for Classifying Scoliosis
Jul 09, 2024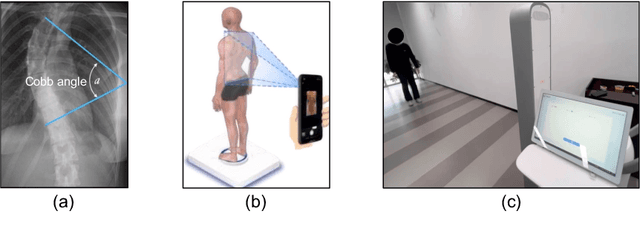
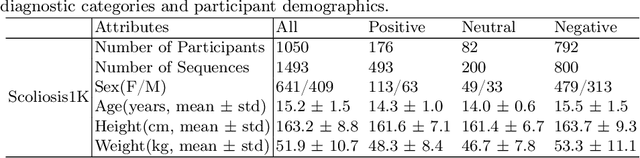

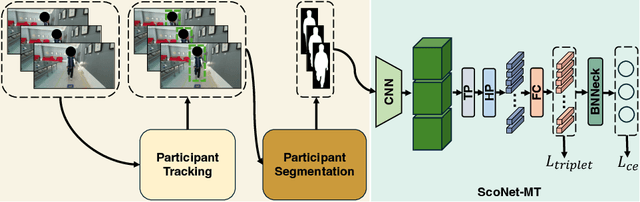
Scoliosis poses significant diagnostic challenges, particularly in adolescents, where early detection is crucial for effective treatment. Traditional diagnostic and follow-up methods, which rely on physical examinations and radiography, face limitations due to the need for clinical expertise and the risk of radiation exposure, thus restricting their use for widespread early screening. In response, we introduce a novel, video-based, non-invasive method for scoliosis classification using gait analysis, which circumvents these limitations. This study presents Scoliosis1K, the first large-scale dataset tailored for video-based scoliosis classification, encompassing over one thousand adolescents. Leveraging this dataset, we developed ScoNet, an initial model that encountered challenges in dealing with the complexities of real-world data. This led to the creation of ScoNet-MT, an enhanced model incorporating multi-task learning, which exhibits promising diagnostic accuracy for application purposes. Our findings demonstrate that gait can be a non-invasive biomarker for scoliosis, revolutionizing screening practices with deep learning and setting a precedent for non-invasive diagnostic methodologies. The dataset and code are publicly available at https://zhouzi180.github.io/Scoliosis1K/.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024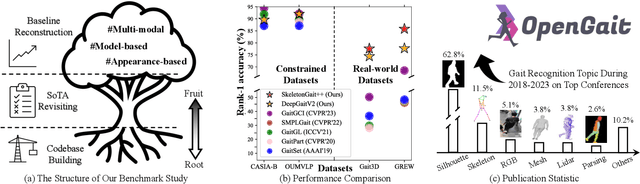
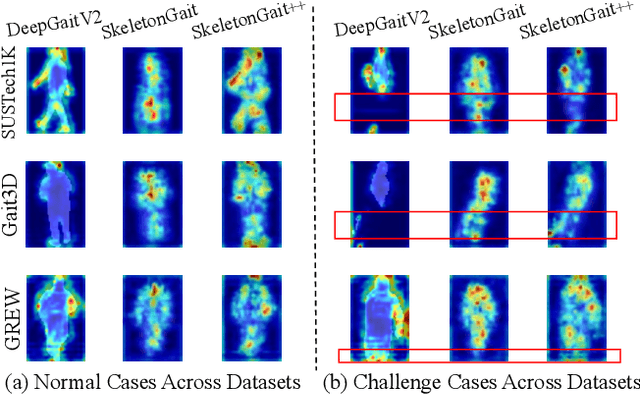
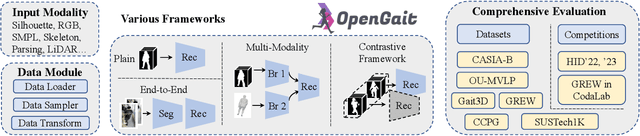
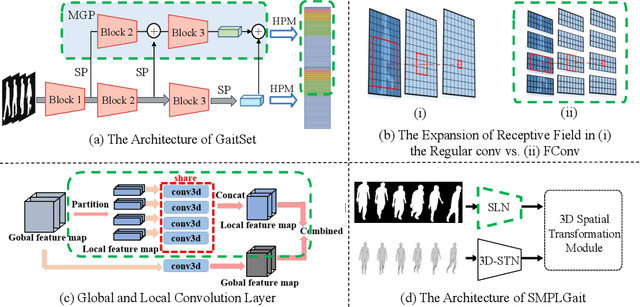
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
The Ninth NTIRE 2024 Efficient Super-Resolution Challenge Report
Apr 16, 2024



This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at https://github.com/Amazingren/NTIRE2024_ESR/.