 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDISPLAY: Directable Human-Object Interaction Video Generation via Sparse Motion Guidance and Multi-Task Auxiliary
Mar 10, 2026Human-centric video generation has advanced rapidly, yet existing methods struggle to produce controllable and physically consistent Human-Object Interaction (HOI) videos. Existing works rely on dense control signals, template videos, or carefully crafted text prompts, which limit flexibility and generalization to novel objects. We introduce a framework, namely DISPLAY, guided by Sparse Motion Guidance, composed only of wrist joint coordinates and a shape-agnostic object bounding box. This lightweight guidance alleviates the imbalance between human and object representations and enables intuitive user control. To enhance fidelity under such sparse conditions, we propose an Object-Stressed Attention mechanism that improves object robustness. To address the scarcity of high-quality HOI data, we further develop a Multi-Task Auxiliary Training strategy with a dedicated data curation pipeline, allowing the model to benefit from both reliable HOI samples and auxiliary tasks. Comprehensive experiments show that our method achieves high-fidelity, controllable HOI generation across diverse tasks. The project page can be found at \href{https://mumuwei.github.io/DISPLAY/}.
Gait Patterns as Biomarkers: A Video-Based Approach for Classifying Scoliosis
Jul 09, 2024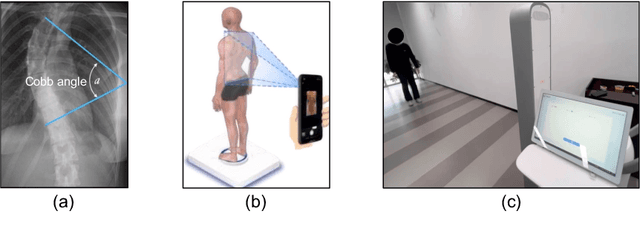
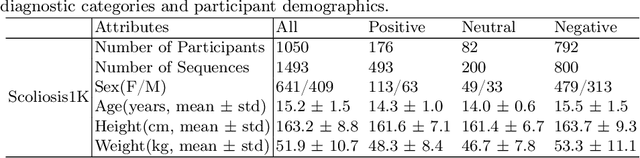

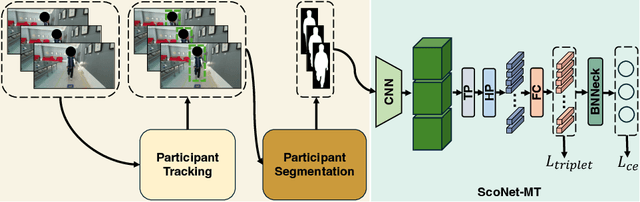
Scoliosis poses significant diagnostic challenges, particularly in adolescents, where early detection is crucial for effective treatment. Traditional diagnostic and follow-up methods, which rely on physical examinations and radiography, face limitations due to the need for clinical expertise and the risk of radiation exposure, thus restricting their use for widespread early screening. In response, we introduce a novel, video-based, non-invasive method for scoliosis classification using gait analysis, which circumvents these limitations. This study presents Scoliosis1K, the first large-scale dataset tailored for video-based scoliosis classification, encompassing over one thousand adolescents. Leveraging this dataset, we developed ScoNet, an initial model that encountered challenges in dealing with the complexities of real-world data. This led to the creation of ScoNet-MT, an enhanced model incorporating multi-task learning, which exhibits promising diagnostic accuracy for application purposes. Our findings demonstrate that gait can be a non-invasive biomarker for scoliosis, revolutionizing screening practices with deep learning and setting a precedent for non-invasive diagnostic methodologies. The dataset and code are publicly available at https://zhouzi180.github.io/Scoliosis1K/.
OpenGait: A Comprehensive Benchmark Study for Gait Recognition towards Better Practicality
May 15, 2024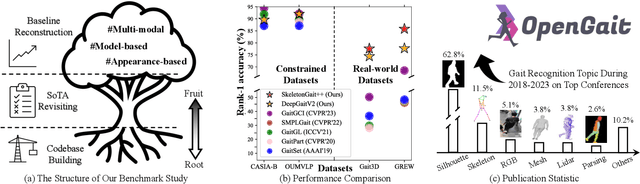
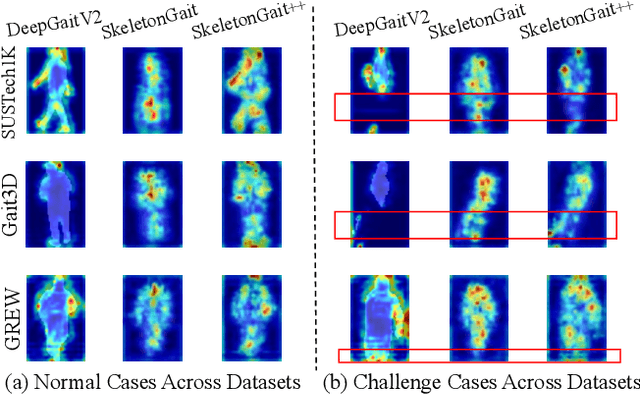
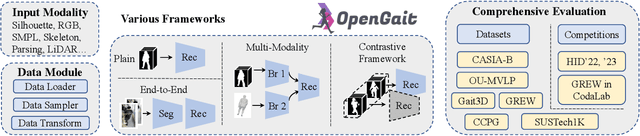
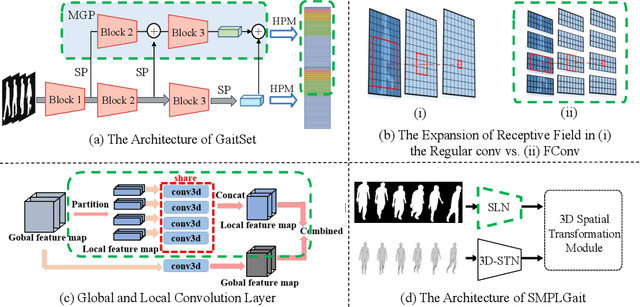
Gait recognition, a rapidly advancing vision technology for person identification from a distance, has made significant strides in indoor settings. However, evidence suggests that existing methods often yield unsatisfactory results when applied to newly released real-world gait datasets. Furthermore, conclusions drawn from indoor gait datasets may not easily generalize to outdoor ones. Therefore, the primary goal of this work is to present a comprehensive benchmark study aimed at improving practicality rather than solely focusing on enhancing performance. To this end, we first develop OpenGait, a flexible and efficient gait recognition platform. Using OpenGait as a foundation, we conduct in-depth ablation experiments to revisit recent developments in gait recognition. Surprisingly, we detect some imperfect parts of certain prior methods thereby resulting in several critical yet undiscovered insights. Inspired by these findings, we develop three structurally simple yet empirically powerful and practically robust baseline models, i.e., DeepGaitV2, SkeletonGait, and SkeletonGait++, respectively representing the appearance-based, model-based, and multi-modal methodology for gait pattern description. Beyond achieving SoTA performances, more importantly, our careful exploration sheds new light on the modeling experience of deep gait models, the representational capacity of typical gait modalities, and so on. We hope this work can inspire further research and application of gait recognition towards better practicality. The code is available at https://github.com/ShiqiYu/OpenGait.
Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning
Jul 21, 2023



Recent progress in personalized image generation using diffusion models has been significant. However, development in the area of open-domain and non-fine-tuning personalized image generation is proceeding rather slowly. In this paper, we propose Subject-Diffusion, a novel open-domain personalized image generation model that, in addition to not requiring test-time fine-tuning, also only requires a single reference image to support personalized generation of single- or multi-subject in any domain. Firstly, we construct an automatic data labeling tool and use the LAION-Aesthetics dataset to construct a large-scale dataset consisting of 76M images and their corresponding subject detection bounding boxes, segmentation masks and text descriptions. Secondly, we design a new unified framework that combines text and image semantics by incorporating coarse location and fine-grained reference image control to maximize subject fidelity and generalization. Furthermore, we also adopt an attention control mechanism to support multi-subject generation. Extensive qualitative and quantitative results demonstrate that our method outperforms other SOTA frameworks in single, multiple, and human customized image generation. Please refer to our \href{https://oppo-mente-lab.github.io/subject_diffusion/}{project page}
OpenGait: Revisiting Gait Recognition Toward Better Practicality
Nov 19, 2022



Gait recognition is one of the most important long-distance identification technologies and increasingly gains popularity in both research and industry communities. Although significant progress has been made in indoor datasets, much evidence shows that gait recognition techniques perform poorly in the wild. More importantly, we also find that many conclusions from prior works change with the evaluation datasets. Therefore, the more critical goal of this paper is to present a comprehensive benchmark study for better practicality rather than only a particular model for better performance. To this end, we first develop a flexible and efficient gait recognition codebase named OpenGait. Based on OpenGait, we deeply revisit the recent development of gait recognition by re-conducting the ablative experiments. Encouragingly, we find many hidden troubles of prior works and new insights for future research. Inspired by these discoveries, we develop a structurally simple, empirically powerful and practically robust baseline model, GaitBase. Experimentally, we comprehensively compare GaitBase with many current gait recognition methods on multiple public datasets, and the results reflect that GaitBase achieves significantly strong performance in most cases regardless of indoor or outdoor situations. The source code is available at \url{https://github.com/ShiqiYu/OpenGait}.
GaitEdge: Beyond Plain End-to-end Gait Recognition for Better Practicality
Mar 08, 2022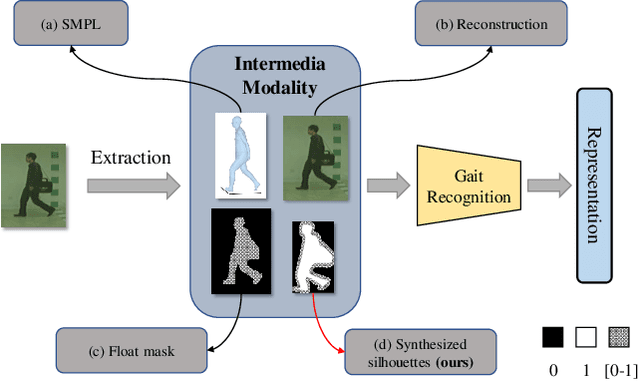
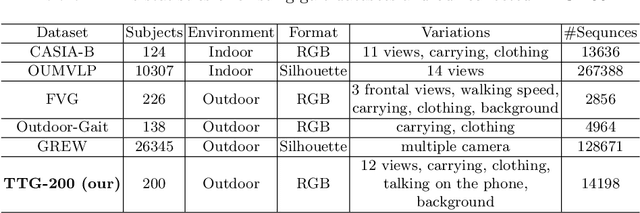
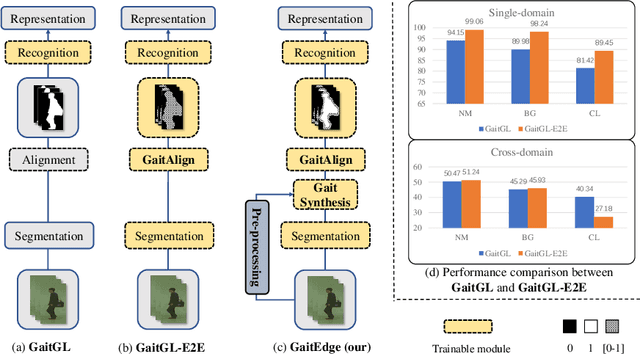
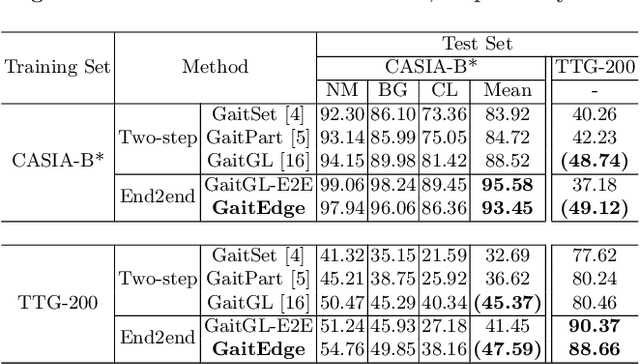
Gait is one of the most promising biometrics to identify individuals at a long distance. Although most previous methods have focused on recognizing the silhouettes, several end-to-end methods that extract gait features directly from RGB images perform better. However, we argue that these end-to-end methods inevitably suffer from the gait-unrelated noises, i.e., low-level texture and colorful information. Experimentally, we design both the cross-domain evaluation and visualization to stand for this view. In this work, we propose a novel end-to-end framework named GaitEdge which can effectively block gait-unrelated information and release end-to-end training potential. Specifically, GaitEdge synthesizes the output of the pedestrian segmentation network and then feeds it to the subsequent recognition network, where the synthetic silhouettes consist of trainable edges of bodies and fixed interiors to limit the information that the recognition network receives. Besides, GaitAlign for aligning silhouettes is embedded into the GaitEdge without loss of differentiability. Experimental results on CASIA-B and our newly built TTG-200 indicate that GaitEdge significantly outperforms the previous methods and provides a more practical end-to-end paradigm for blocking RGB noises effectively. All the source code will be released.