 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Generative Game Engine: Breaking the Resolution Wall via Hardware-Algorithm Co-Design
Jan 31, 2026Real-time generative game engines represent a paradigm shift in interactive simulation, promising to replace traditional graphics pipelines with neural world models. However, existing approaches are fundamentally constrained by the ``Memory Wall,'' restricting practical deployments to low resolutions (e.g., $64 \times 64$). This paper bridges the gap between generative models and high-resolution neural simulations by introducing a scalable \textit{Hardware-Algorithm Co-Design} framework. We identify that high-resolution generation suffers from a critical resource mismatch: the World Model is compute-bound while the Decoder is memory-bound. To address this, we propose a heterogeneous architecture that intelligently decouples these components across a cluster of AI accelerators. Our system features three core innovations: (1) an asymmetric resource allocation strategy that optimizes throughput under sequence parallelism constraints; (2) a memory-centric operator fusion scheme that minimizes off-chip bandwidth usage; and (3) a manifold-aware latent extrapolation mechanism that exploits temporal redundancy to mask latency. We validate our approach on a cluster of programmable AI accelerators, enabling real-time generation at $720 \times 480$ resolution -- a $50\times$ increase in pixel throughput over prior baselines. Evaluated on both continuous 3D racing and discrete 2D platformer benchmarks, our system delivers fluid 26.4 FPS and 48.3 FPS respectively, with an amortized effective latency of 2.7 ms. This work demonstrates that resolving the ``Memory Wall'' via architectural co-design is not merely an optimization, but a prerequisite for enabling high-fidelity, responsive neural gameplay.
Gait Patterns as Biomarkers: A Video-Based Approach for Classifying Scoliosis
Jul 09, 2024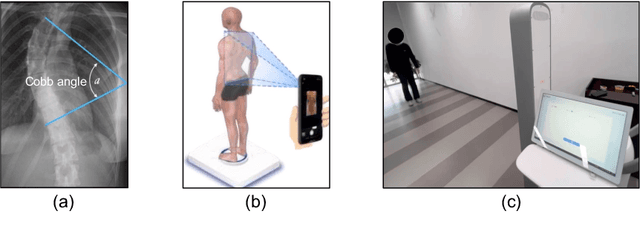
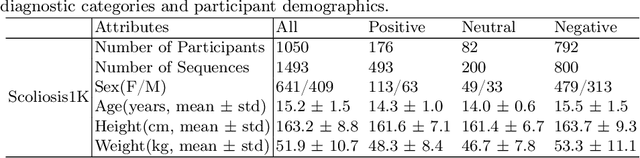

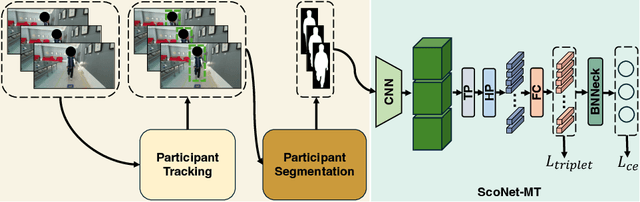
Scoliosis poses significant diagnostic challenges, particularly in adolescents, where early detection is crucial for effective treatment. Traditional diagnostic and follow-up methods, which rely on physical examinations and radiography, face limitations due to the need for clinical expertise and the risk of radiation exposure, thus restricting their use for widespread early screening. In response, we introduce a novel, video-based, non-invasive method for scoliosis classification using gait analysis, which circumvents these limitations. This study presents Scoliosis1K, the first large-scale dataset tailored for video-based scoliosis classification, encompassing over one thousand adolescents. Leveraging this dataset, we developed ScoNet, an initial model that encountered challenges in dealing with the complexities of real-world data. This led to the creation of ScoNet-MT, an enhanced model incorporating multi-task learning, which exhibits promising diagnostic accuracy for application purposes. Our findings demonstrate that gait can be a non-invasive biomarker for scoliosis, revolutionizing screening practices with deep learning and setting a precedent for non-invasive diagnostic methodologies. The dataset and code are publicly available at https://zhouzi180.github.io/Scoliosis1K/.
Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
Mar 29, 2024



Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
BESA: Pruning Large Language Models with Blockwise Parameter-Efficient Sparsity Allocation
Feb 18, 2024Large language models (LLMs) have demonstrated outstanding performance in various tasks, such as text summarization, text question-answering, and etc. While their performance is impressive, the computational footprint due to their vast number of parameters can be prohibitive. Existing solutions such as SparseGPT and Wanda attempt to alleviate this issue through weight pruning. However, their layer-wise approach results in significant perturbation to the model's output and requires meticulous hyperparameter tuning, such as the pruning rate, which can adversely affect overall model performance. To address this, this paper introduces a novel LLM pruning technique dubbed blockwise parameter-efficient sparsity allocation (BESA) by applying a blockwise reconstruction loss. In contrast to the typical layer-wise pruning techniques, BESA is characterized by two distinctive attributes: i) it targets the overall pruning error with respect to individual transformer blocks, and ii) it allocates layer-specific sparsity in a differentiable manner, both of which ensure reduced performance degradation after pruning. Our experiments show that BESA achieves state-of-the-art performance, efficiently pruning LLMs like LLaMA1, and LLaMA2 with 7B to 70B parameters on a single A100 GPU in just five hours. Code is available at \href{https://github.com/OpenGVLab/LLMPrune-BESA}{here}.