 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Three Regimes of Offline-to-Online Reinforcement Learning
Oct 01, 2025



Offline-to-online reinforcement learning (RL) has emerged as a practical paradigm that leverages offline datasets for pretraining and online interactions for fine-tuning. However, its empirical behavior is highly inconsistent: design choices of online-fine tuning that work well in one setting can fail completely in another. We propose a stability--plasticity principle that can explain this inconsistency: we should preserve the knowledge of pretrained policy or offline dataset during online fine-tuning, whichever is better, while maintaining sufficient plasticity. This perspective identifies three regimes of online fine-tuning, each requiring distinct stability properties. We validate this framework through a large-scale empirical study, finding that the results strongly align with its predictions in 45 of 63 cases. This work provides a principled framework for guiding design choices in offline-to-online RL based on the relative performance of the offline dataset and the pretrained policy.
Teaching Large Language Models to Reason through Learning and Forgetting
Apr 15, 2025Leveraging inference-time search in large language models has proven effective in further enhancing a trained model's capability to solve complex mathematical and reasoning problems. However, this approach significantly increases computational costs and inference time, as the model must generate and evaluate multiple candidate solutions to identify a viable reasoning path. To address this, we propose an effective approach that integrates search capabilities directly into the model by fine-tuning it using both successful (learning) and failed reasoning paths (forgetting) derived from diverse search methods. While fine-tuning the model with these data might seem straightforward, we identify a critical issue: the model's search capability tends to degrade rapidly if fine-tuning is performed naively. We show that this degradation can be substantially mitigated by employing a smaller learning rate. Extensive experiments on the challenging Game-of-24 and Countdown mathematical reasoning benchmarks show that our approach not only outperforms both standard fine-tuning and inference-time search baselines but also significantly reduces inference time by 180$\times$.
Genetic Quantization-Aware Approximation for Non-Linear Operations in Transformers
Mar 29, 2024



Non-linear functions are prevalent in Transformers and their lightweight variants, incurring substantial and frequently underestimated hardware costs. Previous state-of-the-art works optimize these operations by piece-wise linear approximation and store the parameters in look-up tables (LUT), but most of them require unfriendly high-precision arithmetics such as FP/INT 32 and lack consideration of integer-only INT quantization. This paper proposed a genetic LUT-Approximation algorithm namely GQA-LUT that can automatically determine the parameters with quantization awareness. The results demonstrate that GQA-LUT achieves negligible degradation on the challenging semantic segmentation task for both vanilla and linear Transformer models. Besides, proposed GQA-LUT enables the employment of INT8-based LUT-Approximation that achieves an area savings of 81.3~81.7% and a power reduction of 79.3~80.2% compared to the high-precision FP/INT 32 alternatives. Code is available at https:// github.com/PingchengDong/GQA-LUT.
Do Transformer World Models Give Better Policy Gradients?
Feb 11, 2024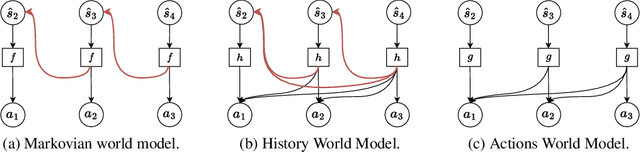

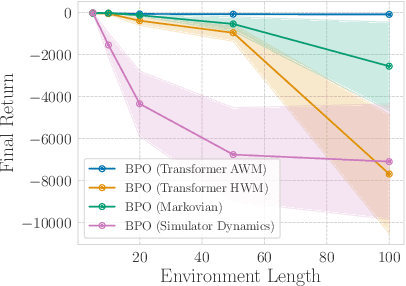

A natural approach for reinforcement learning is to predict future rewards by unrolling a neural network world model, and to backpropagate through the resulting computational graph to learn a policy. However, this method often becomes impractical for long horizons since typical world models induce hard-to-optimize loss landscapes. Transformers are known to efficiently propagate gradients over long horizons: could they be the solution to this problem? Surprisingly, we show that commonly-used transformer world models produce circuitous gradient paths, which can be detrimental to long-range policy gradients. To tackle this challenge, we propose a class of world models called Actions World Models (AWMs), designed to provide more direct routes for gradient propagation. We integrate such AWMs into a policy gradient framework that underscores the relationship between network architectures and the policy gradient updates they inherently represent. We demonstrate that AWMs can generate optimization landscapes that are easier to navigate even when compared to those from the simulator itself. This property allows transformer AWMs to produce better policies than competitive baselines in realistic long-horizon tasks.
Bridging State and History Representations: Understanding Self-Predictive RL
Jan 17, 2024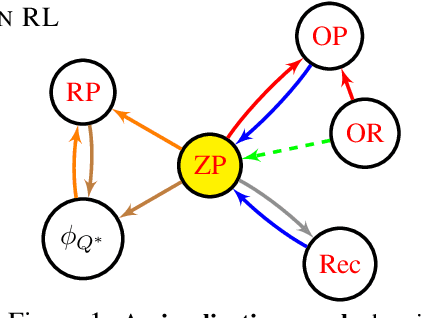
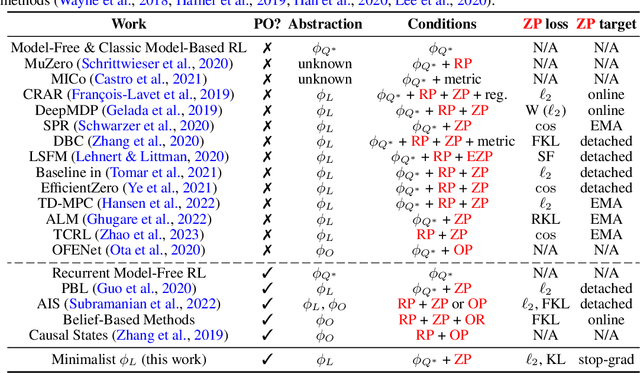
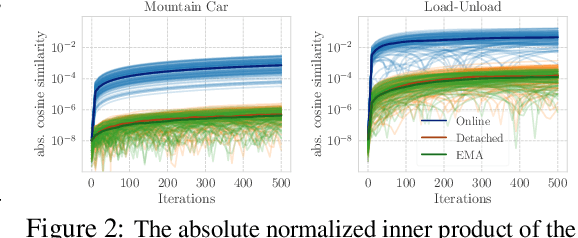
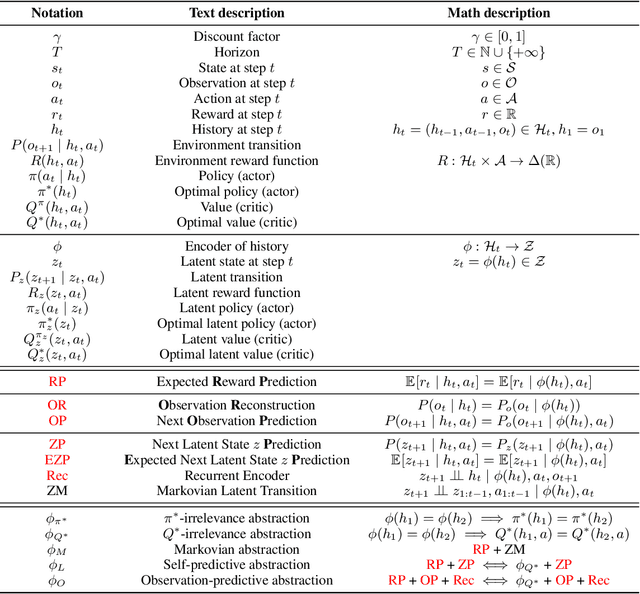
Representations are at the core of all deep reinforcement learning (RL) methods for both Markov decision processes (MDPs) and partially observable Markov decision processes (POMDPs). Many representation learning methods and theoretical frameworks have been developed to understand what constitutes an effective representation. However, the relationships between these methods and the shared properties among them remain unclear. In this paper, we show that many of these seemingly distinct methods and frameworks for state and history abstractions are, in fact, based on a common idea of self-predictive abstraction. Furthermore, we provide theoretical insights into the widely adopted objectives and optimization, such as the stop-gradient technique, in learning self-predictive representations. These findings together yield a minimalist algorithm to learn self-predictive representations for states and histories. We validate our theories by applying our algorithm to standard MDPs, MDPs with distractors, and POMDPs with sparse rewards. These findings culminate in a set of practical guidelines for RL practitioners.
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
Jul 31, 2023



Reinforcement learning (RL) algorithms face two distinct challenges: learning effective representations of past and present observations, and determining how actions influence future returns. Both challenges involve modeling long-term dependencies. The transformer architecture has been very successful to solve problems that involve long-term dependencies, including in the RL domain. However, the underlying reason for the strong performance of Transformer-based RL methods remains unclear: is it because they learn effective memory, or because they perform effective credit assignment? After introducing formal definitions of memory length and credit assignment length, we design simple configurable tasks to measure these distinct quantities. Our empirical results reveal that Transformers can enhance the memory capacity of RL algorithms, scaling up to tasks that require memorizing observations $1500$ steps ago. However, Transformers do not improve long-term credit assignment. In summary, our results provide an explanation for the success of Transformers in RL, while also highlighting an important area for future research and benchmark design.
Towards Disturbance-Free Visual Mobile Manipulation
Dec 17, 2021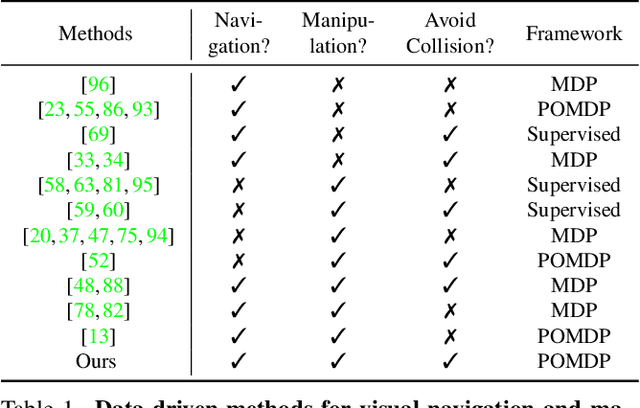
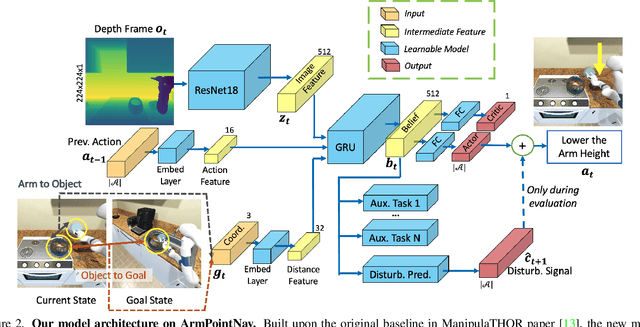
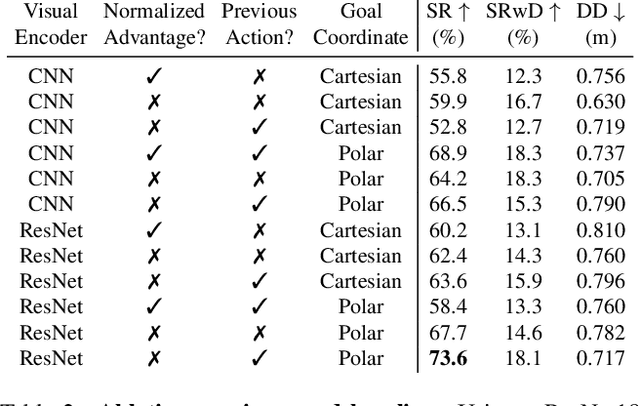
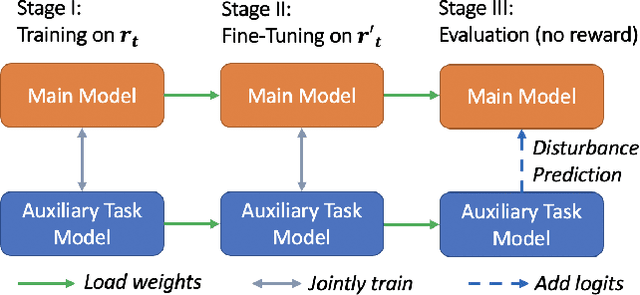
Embodied AI has shown promising results on an abundance of robotic tasks in simulation, including visual navigation and manipulation. The prior work generally pursues high success rates with shortest paths while largely ignoring the problems caused by collision during interaction. This lack of prioritization is understandable: in simulated environments there is no inherent cost to breaking virtual objects. As a result, well-trained agents frequently have catastrophic collision with objects despite final success. In the robotics community, where the cost of collision is large, collision avoidance is a long-standing and crucial topic to ensure that robots can be safely deployed in the real world. In this work, we take the first step towards collision/disturbance-free embodied AI agents for visual mobile manipulation, facilitating safe deployment in real robots. We develop a new disturbance-avoidance methodology at the heart of which is the auxiliary task of disturbance prediction. When combined with a disturbance penalty, our auxiliary task greatly enhances sample efficiency and final performance by knowledge distillation of disturbance into the agent. Our experiments on ManipulaTHOR show that, on testing scenes with novel objects, our method improves the success rate from 61.7% to 85.6% and the success rate without disturbance from 29.8% to 50.2% over the original baseline. Extensive ablation studies show the value of our pipelined approach. Project site is at https://sites.google.com/view/disturb-free
Recurrent Model-Free RL is a Strong Baseline for Many POMDPs
Oct 11, 2021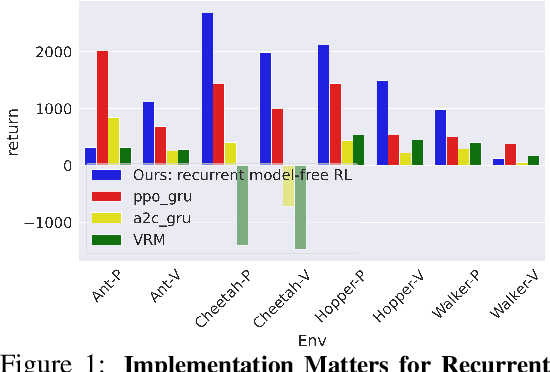

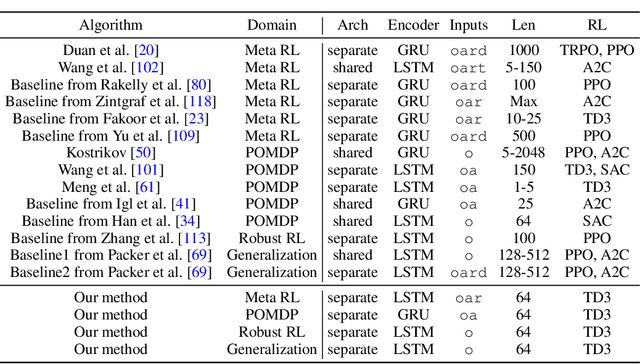
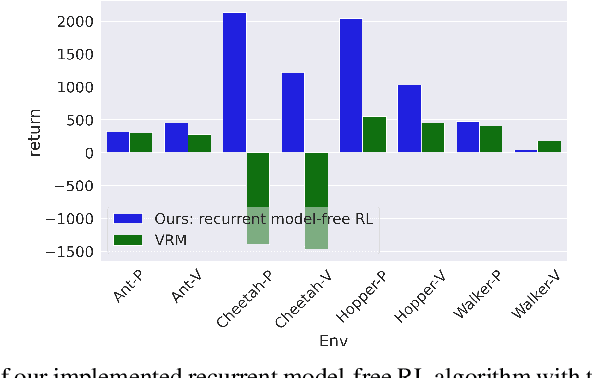
Many problems in RL, such as meta RL, robust RL, and generalization in RL, can be cast as POMDPs. In theory, simply augmenting model-free RL with memory, such as recurrent neural networks, provides a general approach to solving all types of POMDPs. However, prior work has found that such recurrent model-free RL methods tend to perform worse than more specialized algorithms that are designed for specific types of POMDPs. This paper revisits this claim. We find that careful architecture and hyperparameter decisions yield a recurrent model-free implementation that performs on par with (and occasionally substantially better than) more sophisticated recent techniques in their respective domains. We also release a simple and efficient implementation of recurrent model-free RL for future work to use as a baseline for POMDPs. Code is available at https://github.com/twni2016/pomdp-baselines
Adaptive Agent Architecture for Real-time Human-Agent Teaming
Mar 07, 2021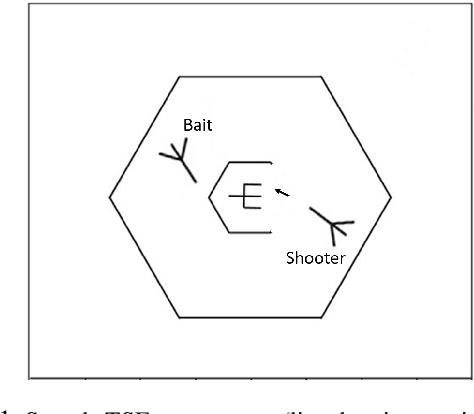
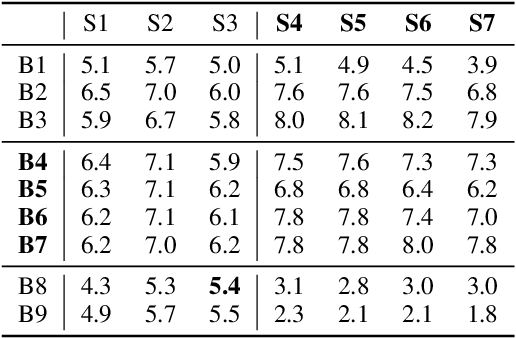
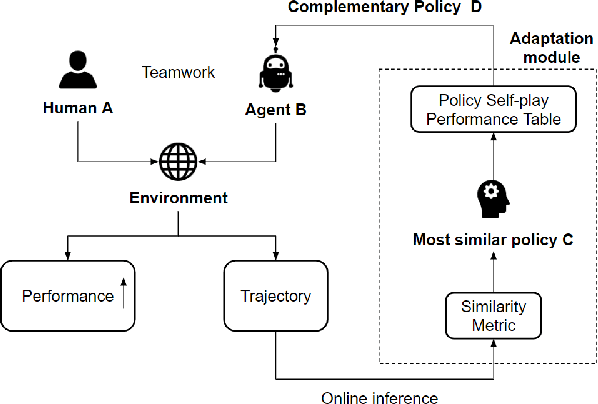
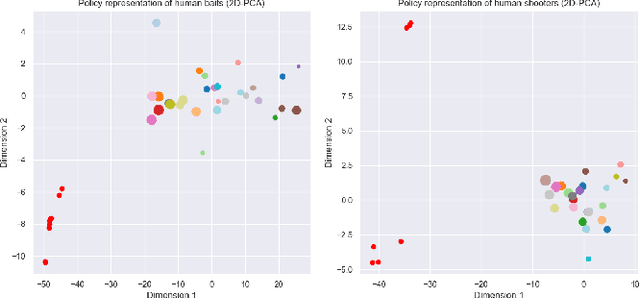
Teamwork is a set of interrelated reasoning, actions and behaviors of team members that facilitate common objectives. Teamwork theory and experiments have resulted in a set of states and processes for team effectiveness in both human-human and agent-agent teams. However, human-agent teaming is less well studied because it is so new and involves asymmetry in policy and intent not present in human teams. To optimize team performance in human-agent teaming, it is critical that agents infer human intent and adapt their polices for smooth coordination. Most literature in human-agent teaming builds agents referencing a learned human model. Though these agents are guaranteed to perform well with the learned model, they lay heavy assumptions on human policy such as optimality and consistency, which is unlikely in many real-world scenarios. In this paper, we propose a novel adaptive agent architecture in human-model-free setting on a two-player cooperative game, namely Team Space Fortress (TSF). Previous human-human team research have shown complementary policies in TSF game and diversity in human players' skill, which encourages us to relax the assumptions on human policy. Therefore, we discard learning human models from human data, and instead use an adaptation strategy on a pre-trained library of exemplar policies composed of RL algorithms or rule-based methods with minimal assumptions of human behavior. The adaptation strategy relies on a novel similarity metric to infer human policy and then selects the most complementary policy in our library to maximize the team performance. The adaptive agent architecture can be deployed in real-time and generalize to any off-the-shelf static agents. We conducted human-agent experiments to evaluate the proposed adaptive agent framework, and demonstrated the suboptimality, diversity, and adaptability of human policies in human-agent teams.
f-IRL: Inverse Reinforcement Learning via State Marginal Matching
Nov 09, 2020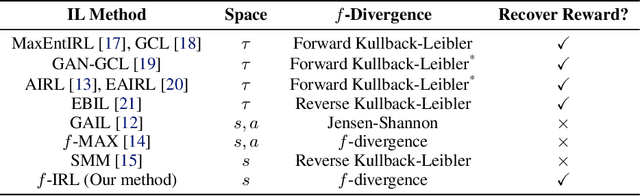


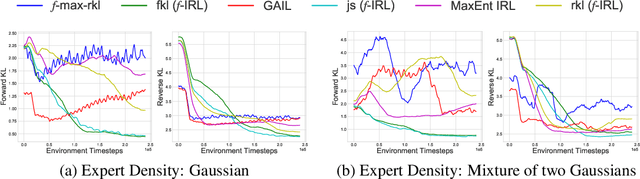
Imitation learning is well-suited for robotic tasks where it is difficult to directly program the behavior or specify a cost for optimal control. In this work, we propose a method for learning the reward function (and the corresponding policy) to match the expert state density. Our main result is the analytic gradient of any f-divergence between the agent and expert state distribution w.r.t. reward parameters. Based on the derived gradient, we present an algorithm, f-IRL, that recovers a stationary reward function from the expert density by gradient descent. We show that f-IRL can learn behaviors from a hand-designed target state density or implicitly through expert observations. Our method outperforms adversarial imitation learning methods in terms of sample efficiency and the required number of expert trajectories on IRL benchmarks. Moreover, we show that the recovered reward function can be used to quickly solve downstream tasks, and empirically demonstrate its utility on hard-to-explore tasks and for behavior transfer across changes in dynamics.