 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformer World Models Give Better Policy Gradients?
Feb 11, 2024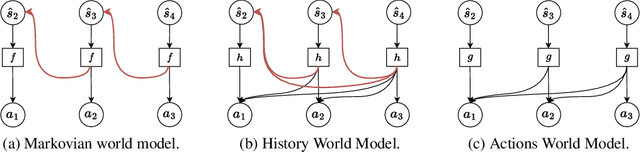

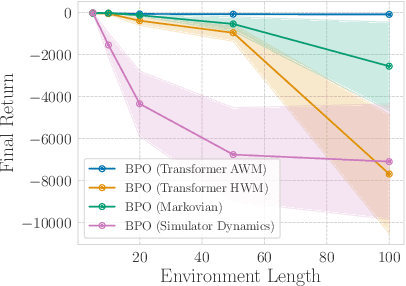

A natural approach for reinforcement learning is to predict future rewards by unrolling a neural network world model, and to backpropagate through the resulting computational graph to learn a policy. However, this method often becomes impractical for long horizons since typical world models induce hard-to-optimize loss landscapes. Transformers are known to efficiently propagate gradients over long horizons: could they be the solution to this problem? Surprisingly, we show that commonly-used transformer world models produce circuitous gradient paths, which can be detrimental to long-range policy gradients. To tackle this challenge, we propose a class of world models called Actions World Models (AWMs), designed to provide more direct routes for gradient propagation. We integrate such AWMs into a policy gradient framework that underscores the relationship between network architectures and the policy gradient updates they inherently represent. We demonstrate that AWMs can generate optimization landscapes that are easier to navigate even when compared to those from the simulator itself. This property allows transformer AWMs to produce better policies than competitive baselines in realistic long-horizon tasks.
Bridging State and History Representations: Understanding Self-Predictive RL
Jan 17, 2024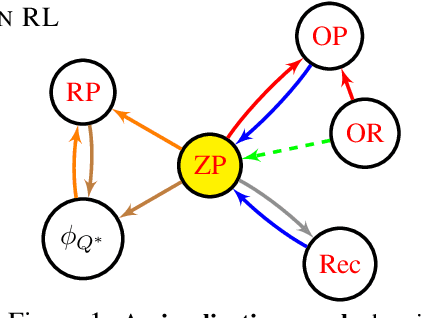
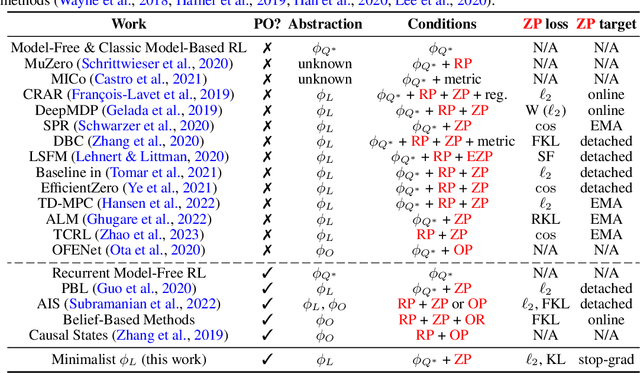
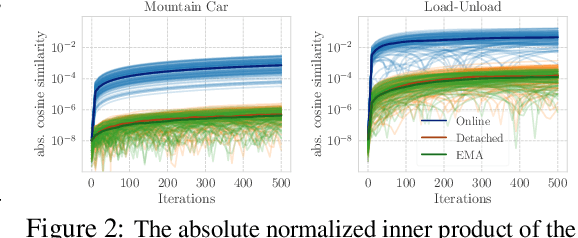
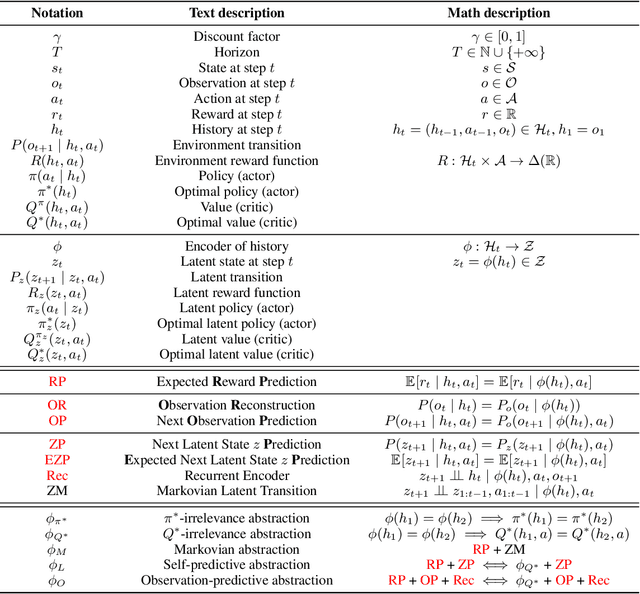
Representations are at the core of all deep reinforcement learning (RL) methods for both Markov decision processes (MDPs) and partially observable Markov decision processes (POMDPs). Many representation learning methods and theoretical frameworks have been developed to understand what constitutes an effective representation. However, the relationships between these methods and the shared properties among them remain unclear. In this paper, we show that many of these seemingly distinct methods and frameworks for state and history abstractions are, in fact, based on a common idea of self-predictive abstraction. Furthermore, we provide theoretical insights into the widely adopted objectives and optimization, such as the stop-gradient technique, in learning self-predictive representations. These findings together yield a minimalist algorithm to learn self-predictive representations for states and histories. We validate our theories by applying our algorithm to standard MDPs, MDPs with distractors, and POMDPs with sparse rewards. These findings culminate in a set of practical guidelines for RL practitioners.
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
Jul 31, 2023



Reinforcement learning (RL) algorithms face two distinct challenges: learning effective representations of past and present observations, and determining how actions influence future returns. Both challenges involve modeling long-term dependencies. The transformer architecture has been very successful to solve problems that involve long-term dependencies, including in the RL domain. However, the underlying reason for the strong performance of Transformer-based RL methods remains unclear: is it because they learn effective memory, or because they perform effective credit assignment? After introducing formal definitions of memory length and credit assignment length, we design simple configurable tasks to measure these distinct quantities. Our empirical results reveal that Transformers can enhance the memory capacity of RL algorithms, scaling up to tasks that require memorizing observations $1500$ steps ago. However, Transformers do not improve long-term credit assignment. In summary, our results provide an explanation for the success of Transformers in RL, while also highlighting an important area for future research and benchmark design.