 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformer World Models Give Better Policy Gradients?
Paper and Code
Feb 11, 2024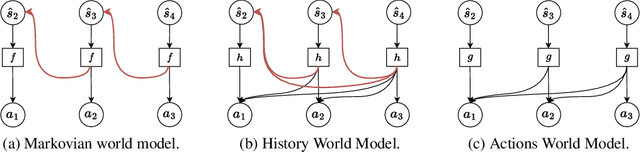

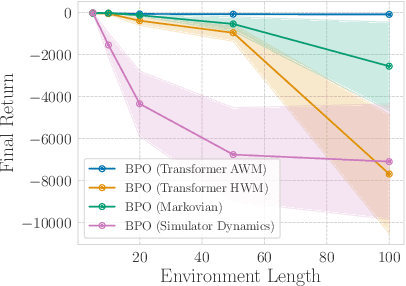

A natural approach for reinforcement learning is to predict future rewards by unrolling a neural network world model, and to backpropagate through the resulting computational graph to learn a policy. However, this method often becomes impractical for long horizons since typical world models induce hard-to-optimize loss landscapes. Transformers are known to efficiently propagate gradients over long horizons: could they be the solution to this problem? Surprisingly, we show that commonly-used transformer world models produce circuitous gradient paths, which can be detrimental to long-range policy gradients. To tackle this challenge, we propose a class of world models called Actions World Models (AWMs), designed to provide more direct routes for gradient propagation. We integrate such AWMs into a policy gradient framework that underscores the relationship between network architectures and the policy gradient updates they inherently represent. We demonstrate that AWMs can generate optimization landscapes that are easier to navigate even when compared to those from the simulator itself. This property allows transformer AWMs to produce better policies than competitive baselines in realistic long-horizon tasks.