 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust the Batch, On- or Off-Policy: Adaptive Policy Optimization for RL Post-Training
May 12, 2026Reinforcement learning is structurally harder than supervised learning because the policy changes the data distribution it learns from. The resulting fragility is especially visible in large-model training, where the training and rollout systems differ in numerical precision, sampling, and other implementation details. Existing methods manage this fragility by adding hyper-parameters to the training objective, which makes the algorithm more sensitive to its configuration and requires retuning whenever the task, model scale, or distribution mismatch changes. This fragility traces to two concerns that current objectives entangle through hyper-parameters set before training begins: a trust-region concern, that updates should not move the policy too far from its current value, and an off-policy concern, that data from older or different behavior policies should influence the update only to the extent that it remains reliable. Neither concern is a constant to set in advance, and their severity is reflected in the policy-ratio distribution of the current batch. We present a simple yet effective batch-adaptive objective that replaces fixed clipping with the normalized effective sample size of the policy ratios. The same statistic caps the score-function weight and sets the strength of an off-policy regularizer, so the update stays close to the usual on-policy score-function update when ratios are nearly uniform, and tightens automatically when stale or mismatched data cause ratio concentration, while retaining a nonzero learning signal on high-ratio tokens. Experiments across a wide range of settings show that our method matches or exceeds tuned baselines, introducing no new objective hyper-parameters and removing several existing ones. The code is available at https://github.com/FeynRL-project/FeynRL.
Understanding the Challenges in Iterative Generative Optimization with LLMs
Mar 25, 2026Generative optimization uses large language models (LLMs) to iteratively improve artifacts (such as code, workflows or prompts) using execution feedback. It is a promising approach to building self-improving agents, yet in practice remains brittle: despite active research, only 9% of surveyed agents used any automated optimization. We argue that this brittleness arises because, to set up a learning loop, an engineer must make ``hidden'' design choices: What can the optimizer edit and what is the "right" learning evidence to provide at each update? We investigate three factors that affect most applications: the starting artifact, the credit horizon for execution traces, and batching trials and errors into learning evidence. Through case studies in MLAgentBench, Atari, and BigBench Extra Hard, we find that these design decisions can determine whether generative optimization succeeds, yet they are rarely made explicit in prior work. Different starting artifacts determine which solutions are reachable in MLAgentBench, truncated traces can still improve Atari agents, and larger minibatches do not monotonically improve generalization on BBEH. We conclude that the lack of a simple, universal way to set up learning loops across domains is a major hurdle for productionization and adoption. We provide practical guidance for making these choices.
Teaching Large Language Models to Reason through Learning and Forgetting
Apr 15, 2025Leveraging inference-time search in large language models has proven effective in further enhancing a trained model's capability to solve complex mathematical and reasoning problems. However, this approach significantly increases computational costs and inference time, as the model must generate and evaluate multiple candidate solutions to identify a viable reasoning path. To address this, we propose an effective approach that integrates search capabilities directly into the model by fine-tuning it using both successful (learning) and failed reasoning paths (forgetting) derived from diverse search methods. While fine-tuning the model with these data might seem straightforward, we identify a critical issue: the model's search capability tends to degrade rapidly if fine-tuning is performed naively. We show that this degradation can be substantially mitigated by employing a smaller learning rate. Extensive experiments on the challenging Game-of-24 and Countdown mathematical reasoning benchmarks show that our approach not only outperforms both standard fine-tuning and inference-time search baselines but also significantly reduces inference time by 180$\times$.
From Demonstrations to Rewards: Alignment Without Explicit Human Preferences
Mar 15, 2025One of the challenges of aligning large models with human preferences lies in both the data requirements and the technical complexities of current approaches. Predominant methods, such as RLHF, involve multiple steps, each demanding distinct types of data, including demonstration data and preference data. In RLHF, human preferences are typically modeled through a reward model, which serves as a proxy to guide policy learning during the reinforcement learning stage, ultimately producing a policy aligned with human preferences. However, in this paper, we propose a fresh perspective on learning alignment based on inverse reinforcement learning principles, where the optimal policy is still derived from reward maximization. However, instead of relying on preference data, we directly learn the reward model from demonstration data. This new formulation offers the flexibility to be applied even when only demonstration data is available, a capability that current RLHF methods lack, and it also shows that demonstration data offers more utility than what conventional wisdom suggests. Our extensive evaluation, based on public reward benchmark, HuggingFace Open LLM Leaderboard and MT-Bench, demonstrates that our approach compares favorably to state-of-the-art methods that rely solely on demonstration data.
Bridging the Training-Inference Gap in LLMs by Leveraging Self-Generated Tokens
Oct 18, 2024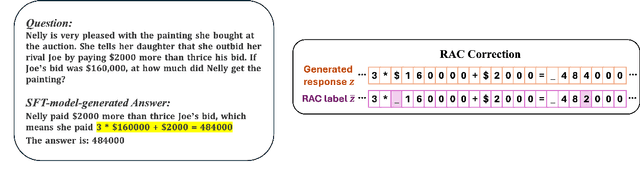
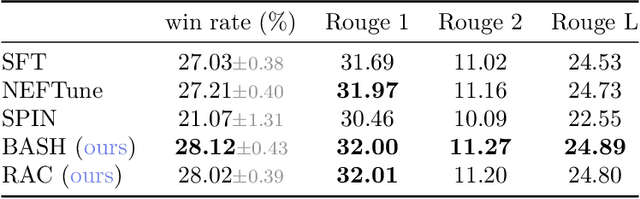
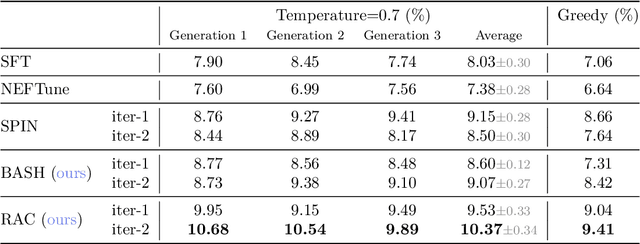
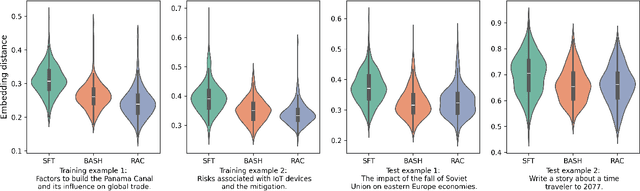
Language models are often trained to maximize the likelihood of the next token given past tokens in the training dataset. However, during inference time, they are utilized differently, generating text sequentially and auto-regressively by using previously generated tokens as input to predict the next one. Marginal differences in predictions at each step can cascade over successive steps, resulting in different distributions from what the models were trained for and potentially leading to unpredictable behavior. This paper proposes two simple approaches based on model own generation to address this discrepancy between the training and inference time. Our first approach is Batch-Scheduled Sampling, where, during training, we stochastically choose between the ground-truth token from the dataset and the model's own generated token as input to predict the next token. This is done in an offline manner, modifying the context window by interleaving ground-truth tokens with those generated by the model. Our second approach is Reference-Answer-based Correction, where we explicitly incorporate a self-correction capability into the model during training. This enables the model to effectively self-correct the gaps between the generated sequences and the ground truth data without relying on an external oracle model. By incorporating our proposed strategies during training, we have observed an overall improvement in performance compared to baseline methods, as demonstrated by our extensive experiments using summarization, general question-answering, and math question-answering tasks.
AgentOccam: A Simple Yet Strong Baseline for LLM-Based Web Agents
Oct 17, 2024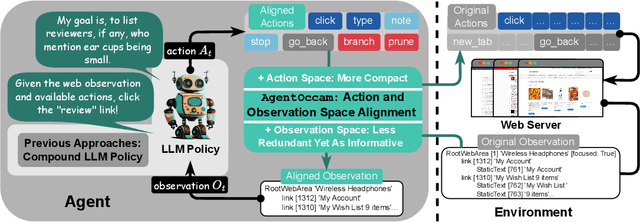
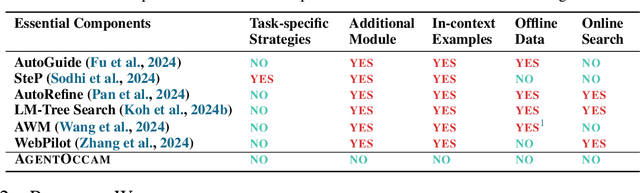
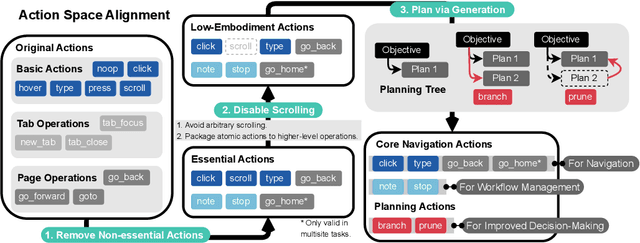

Autonomy via agents using large language models (LLMs) for personalized, standardized tasks boosts human efficiency. Automating web tasks (like booking hotels within a budget) is increasingly sought after. Fulfilling practical needs, the web agent also serves as an important proof-of-concept example for various agent grounding scenarios, with its success promising advancements in many future applications. Prior research often handcrafts web agent strategies (e.g., prompting templates, multi-agent systems, search methods, etc.) and the corresponding in-context examples, which may not generalize well across all real-world scenarios. On the other hand, there has been limited study on the misalignment between a web agent's observation/action representation and the pre-training data of the LLM it's based on. This discrepancy is especially notable when LLMs are primarily trained for language completion rather than tasks involving embodied navigation actions and symbolic web elements. Our study enhances an LLM-based web agent by simply refining its observation and action space to better align with the LLM's capabilities. This approach enables our base agent to significantly outperform previous methods on a wide variety of web tasks. Specifically, on WebArena, a benchmark featuring general-purpose web interaction tasks, our agent AgentOccam surpasses the previous state-of-the-art and concurrent work by 9.8 (+29.4%) and 5.9 (+15.8%) absolute points respectively, and boosts the success rate by 26.6 points (+161%) over similar plain web agents with its observation and action space alignment. We achieve this without using in-context examples, new agent roles, online feedback or search strategies. AgentOccam's simple design highlights LLMs' impressive zero-shot performance on web tasks, and underlines the critical role of carefully tuning observation and action spaces for LLM-based agents.
AlphaRouter: Quantum Circuit Routing with Reinforcement Learning and Tree Search
Oct 07, 2024Quantum computers have the potential to outperform classical computers in important tasks such as optimization and number factoring. They are characterized by limited connectivity, which necessitates the routing of their computational bits, known as qubits, to specific locations during program execution to carry out quantum operations. Traditionally, the NP-hard optimization problem of minimizing the routing overhead has been addressed through sub-optimal rule-based routing techniques with inherent human biases embedded within the cost function design. This paper introduces a solution that integrates Monte Carlo Tree Search (MCTS) with Reinforcement Learning (RL). Our RL-based router, called AlphaRouter, outperforms the current state-of-the-art routing methods and generates quantum programs with up to $20\%$ less routing overhead, thus significantly enhancing the overall efficiency and feasibility of quantum computing.
EXTRACT: Efficient Policy Learning by Extracting Transferrable Robot Skills from Offline Data
Jun 25, 2024



Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.
Learning the Target Network in Function Space
Jun 03, 2024



We focus on the task of learning the value function in the reinforcement learning (RL) setting. This task is often solved by updating a pair of online and target networks while ensuring that the parameters of these two networks are equivalent. We propose Lookahead-Replicate (LR), a new value-function approximation algorithm that is agnostic to this parameter-space equivalence. Instead, the LR algorithm is designed to maintain an equivalence between the two networks in the function space. This value-based equivalence is obtained by employing a new target-network update. We show that LR leads to a convergent behavior in learning the value function. We also present empirical results demonstrating that LR-based target-network updates significantly improve deep RL on the Atari benchmark.
TAIL: Task-specific Adapters for Imitation Learning with Large Pretrained Models
Oct 09, 2023



The full potential of large pretrained models remains largely untapped in control domains like robotics. This is mainly because of the scarcity of data and the computational challenges associated with training or fine-tuning these large models for such applications. Prior work mainly emphasizes effective pretraining of large models for decision-making, with little exploration into how to perform data-efficient continual adaptation of these models for new tasks. Recognizing these constraints, we introduce TAIL (Task-specific Adapters for Imitation Learning), a framework for efficient adaptation to new control tasks. Inspired by recent advancements in parameter-efficient fine-tuning in language domains, we explore efficient fine-tuning techniques -- e.g., Bottleneck Adapters, P-Tuning, and Low-Rank Adaptation (LoRA) -- in TAIL to adapt large pretrained models for new tasks with limited demonstration data. Our extensive experiments in large-scale language-conditioned manipulation tasks comparing prevalent parameter-efficient fine-tuning techniques and adaptation baselines suggest that TAIL with LoRA can achieve the best post-adaptation performance with only 1\% of the trainable parameters of full fine-tuning, while avoiding catastrophic forgetting and preserving adaptation plasticity in continual learning settings.