 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubtask-Aware Visual Reward Learning from Segmented Demonstrations
Feb 28, 2025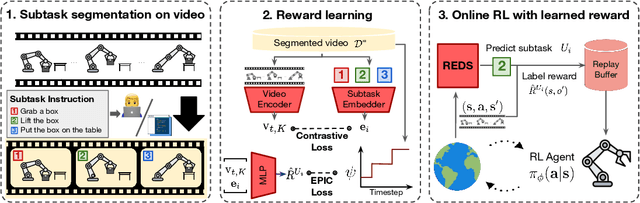



Reinforcement Learning (RL) agents have demonstrated their potential across various robotic tasks. However, they still heavily rely on human-engineered reward functions, requiring extensive trial-and-error and access to target behavior information, often unavailable in real-world settings. This paper introduces REDS: REward learning from Demonstration with Segmentations, a novel reward learning framework that leverages action-free videos with minimal supervision. Specifically, REDS employs video demonstrations segmented into subtasks from diverse sources and treats these segments as ground-truth rewards. We train a dense reward function conditioned on video segments and their corresponding subtasks to ensure alignment with ground-truth reward signals by minimizing the Equivalent-Policy Invariant Comparison distance. Additionally, we employ contrastive learning objectives to align video representations with subtasks, ensuring precise subtask inference during online interactions. Our experiments show that REDS significantly outperforms baseline methods on complex robotic manipulation tasks in Meta-World and more challenging real-world tasks, such as furniture assembly in FurnitureBench, with minimal human intervention. Moreover, REDS facilitates generalization to unseen tasks and robot embodiments, highlighting its potential for scalable deployment in diverse environments.
EXTRACT: Efficient Policy Learning by Extracting Transferrable Robot Skills from Offline Data
Jun 25, 2024



Most reinforcement learning (RL) methods focus on learning optimal policies over low-level action spaces. While these methods can perform well in their training environments, they lack the flexibility to transfer to new tasks. Instead, RL agents that can act over useful, temporally extended skills rather than low-level actions can learn new tasks more easily. Prior work in skill-based RL either requires expert supervision to define useful skills, which is hard to scale, or learns a skill-space from offline data with heuristics that limit the adaptability of the skills, making them difficult to transfer during downstream RL. Our approach, EXTRACT, instead utilizes pre-trained vision language models to extract a discrete set of semantically meaningful skills from offline data, each of which is parameterized by continuous arguments, without human supervision. This skill parameterization allows robots to learn new tasks by only needing to learn when to select a specific skill and how to modify its arguments for the specific task. We demonstrate through experiments in sparse-reward, image-based, robot manipulation environments that EXTRACT can more quickly learn new tasks than prior works, with major gains in sample efficiency and performance over prior skill-based RL. Website at https://www.jessezhang.net/projects/extract/.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
FurnitureBench: Reproducible Real-World Benchmark for Long-Horizon Complex Manipulation
May 22, 2023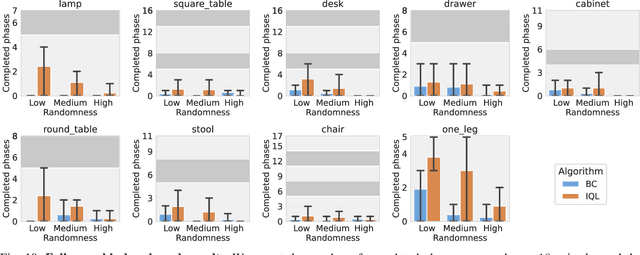
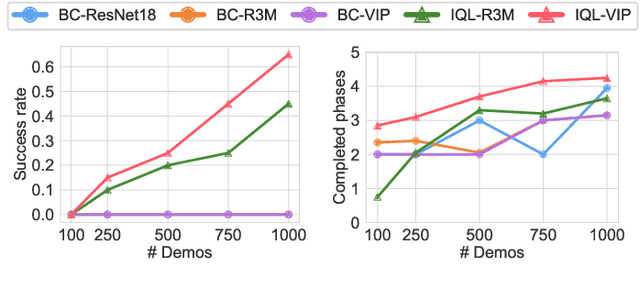
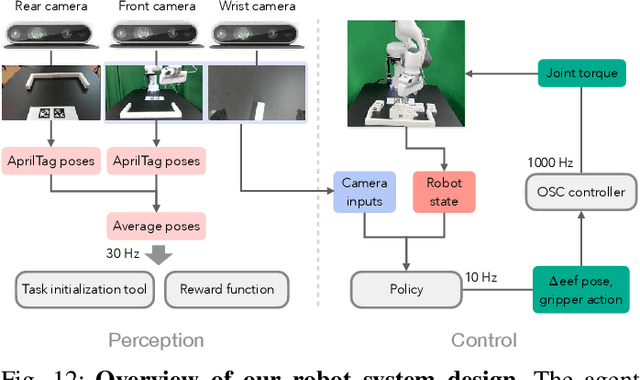

Reinforcement learning (RL), imitation learning (IL), and task and motion planning (TAMP) have demonstrated impressive performance across various robotic manipulation tasks. However, these approaches have been limited to learning simple behaviors in current real-world manipulation benchmarks, such as pushing or pick-and-place. To enable more complex, long-horizon behaviors of an autonomous robot, we propose to focus on real-world furniture assembly, a complex, long-horizon robot manipulation task that requires addressing many current robotic manipulation challenges to solve. We present FurnitureBench, a reproducible real-world furniture assembly benchmark aimed at providing a low barrier for entry and being easily reproducible, so that researchers across the world can reliably test their algorithms and compare them against prior work. For ease of use, we provide 200+ hours of pre-collected data (5000+ demonstrations), 3D printable furniture models, a robotic environment setup guide, and systematic task initialization. Furthermore, we provide FurnitureSim, a fast and realistic simulator of FurnitureBench. We benchmark the performance of offline RL and IL algorithms on our assembly tasks and demonstrate the need to improve such algorithms to be able to solve our tasks in the real world, providing ample opportunities for future research.