 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust Region Q Adjoint Matching
May 26, 2026Off-policy reinforcement learning of pretrained flow policies remains challenging due to the instability of optimization arising from the multi-step sampling process. Recently, Q-learning with Adjoint Matching (QAM) addressed this issue by reformulating into a memoryless stochastic optimal control (SOC) problem with a learned critic. However, QAM inherits a fundamental fragility of critic-guided improvement: small critic errors are amplified when critics are ill-conditioned, often leading to model collapse. This paper introduces Trust Region Q-Adjoint Matching (TRQAM), a stable off-policy fine-tuning algorithm that adaptively controls the path-space KL with pretrained flow policies through projected dual descent. Specifically, we optimize the trust-region parameter $λ$ in SOC dynamics, and theoretically show that the path-space KL can be represented by a closed-form function of $λ$. As a result, our method can precisely control the exact deviation from pretrained flow policies, achieving stable off-policy RL. Through experiments on 50 OGBench tasks, TRQAM consistently outperforms prior arts in both offline RL and offline-to-online RL. In particular, TRQAM achieves an overall success rate of 68% in offline RL, substantially improves the strongest baseline at 46%.
Learning Multi-View Spatial Reasoning from Cross-View Relations
Mar 30, 2026Vision-language models (VLMs) have achieved impressive results on single-view vision tasks, but lack the multi-view spatial reasoning capabilities essential for embodied AI systems to understand 3D environments and manipulate objects across different viewpoints. In this work, we introduce Cross-View Relations (XVR), a large-scale dataset designed to teach VLMs spatial reasoning across multiple views. XVR comprises 100K vision-question-answer samples derived from 18K diverse 3D scenes and 70K robotic manipulation trajectories, spanning three fundamental spatial reasoning tasks: Correspondence (matching objects across views), Verification (validating spatial relationships), and Localization (identifying object positions). VLMs fine-tuned on XVR achieve substantial improvements on established multi-view and robotic spatial reasoning benchmarks (MindCube and RoboSpatial). When integrated as backbones in Vision-Language-Action models, XVR-trained representations improve success rates on RoboCasa. Our results demonstrate that explicit training on cross-view spatial relations significantly enhances multi-view reasoning and transfers effectively to real-world robotic manipulation.
Pretrained Vision-Language-Action Models are Surprisingly Resistant to Forgetting in Continual Learning
Mar 04, 2026Continual learning is a long-standing challenge in robot policy learning, where a policy must acquire new skills over time without catastrophically forgetting previously learned ones. While prior work has extensively studied continual learning in relatively small behavior cloning (BC) policy models trained from scratch, its behavior in modern large-scale pretrained Vision-Language-Action (VLA) models remains underexplored. In this work, we found that pretrained VLAs are remarkably resistant to forgetting compared with smaller policy models trained from scratch. Simple Experience Replay (ER) works surprisingly well on VLAs, sometimes achieving zero forgetting even with a small replay data size. Our analysis reveals that pretraining plays a critical role in downstream continual learning performance: large pretrained models mitigate forgetting with a small replay buffer size while maintaining strong forward learning capabilities. Furthermore, we found that VLAs can retain relevant knowledge from prior tasks despite performance degradation during learning new tasks. This knowledge retention enables rapid recovery of seemingly forgotten skills through finetuning. Together, these insights imply that large-scale pretraining fundamentally changes the dynamics of continual learning, enabling models to continually acquire new skills over time with simple replay. Code and more information can be found at https://ut-austin-rpl.github.io/continual-vla
DEAS: DEtached value learning with Action Sequence for Scalable Offline RL
Oct 09, 2025



Offline reinforcement learning (RL) presents an attractive paradigm for training intelligent agents without expensive online interactions. However, current approaches still struggle with complex, long-horizon sequential decision making. In this work, we introduce DEtached value learning with Action Sequence (DEAS), a simple yet effective offline RL framework that leverages action sequences for value learning. These temporally extended actions provide richer information than single-step actions and can be interpreted through the options framework via semi-Markov decision process Q-learning, enabling reduction of the effective planning horizon by considering longer sequences at once. However, directly adopting such sequences in actor-critic algorithms introduces excessive value overestimation, which we address through detached value learning that steers value estimates toward in-distribution actions that achieve high return in the offline dataset. We demonstrate that DEAS consistently outperforms baselines on complex, long-horizon tasks from OGBench and can be applied to enhance the performance of large-scale Vision-Language-Action models that predict action sequences, significantly boosting performance in both RoboCasa Kitchen simulation tasks and real-world manipulation tasks.
Contrastive Representation Regularization for Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.
HAMLET: Switch your Vision-Language-Action Model into a History-Aware Policy
Oct 02, 2025Inherently, robotic manipulation tasks are history-dependent: leveraging past context could be beneficial. However, most existing Vision-Language-Action models (VLAs) have been designed without considering this aspect, i.e., they rely solely on the current observation, ignoring preceding context. In this paper, we propose HAMLET, a scalable framework to adapt VLAs to attend to the historical context during action prediction. Specifically, we introduce moment tokens that compactly encode perceptual information at each timestep. Their representations are initialized with time-contrastive learning, allowing them to better capture temporally distinctive aspects. Next, we employ a lightweight memory module that integrates the moment tokens across past timesteps into memory features, which are then leveraged for action prediction. Through empirical evaluation, we show that HAMLET successfully transforms a state-of-the-art VLA into a history-aware policy, especially demonstrating significant improvements on long-horizon tasks that require historical context. In particular, on top of GR00T N1.5, HAMLET achieves an average success rate of 76.4% on history-dependent real-world tasks, surpassing the baseline performance by 47.2%. Furthermore, HAMLET pushes prior art performance from 64.1% to 66.4% on RoboCasa Kitchen (100-demo setup) and from 95.6% to 97.7% on LIBERO, highlighting its effectiveness even under generic robot-manipulation benchmarks.
Subtask-Aware Visual Reward Learning from Segmented Demonstrations
Feb 28, 2025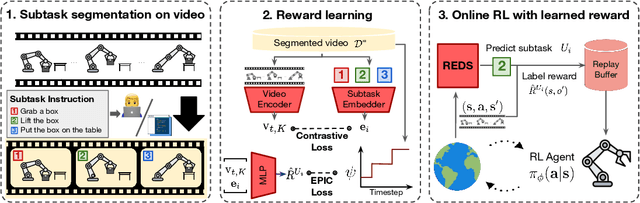



Reinforcement Learning (RL) agents have demonstrated their potential across various robotic tasks. However, they still heavily rely on human-engineered reward functions, requiring extensive trial-and-error and access to target behavior information, often unavailable in real-world settings. This paper introduces REDS: REward learning from Demonstration with Segmentations, a novel reward learning framework that leverages action-free videos with minimal supervision. Specifically, REDS employs video demonstrations segmented into subtasks from diverse sources and treats these segments as ground-truth rewards. We train a dense reward function conditioned on video segments and their corresponding subtasks to ensure alignment with ground-truth reward signals by minimizing the Equivalent-Policy Invariant Comparison distance. Additionally, we employ contrastive learning objectives to align video representations with subtasks, ensuring precise subtask inference during online interactions. Our experiments show that REDS significantly outperforms baseline methods on complex robotic manipulation tasks in Meta-World and more challenging real-world tasks, such as furniture assembly in FurnitureBench, with minimal human intervention. Moreover, REDS facilitates generalization to unseen tasks and robot embodiments, highlighting its potential for scalable deployment in diverse environments.
Benchmarking Mobile Device Control Agents across Diverse Configurations
Apr 25, 2024Developing autonomous agents for mobile devices can significantly enhance user interactions by offering increased efficiency and accessibility. However, despite the growing interest in mobile device control agents, the absence of a commonly adopted benchmark makes it challenging to quantify scientific progress in this area. In this work, we introduce B-MoCA: a novel benchmark designed specifically for evaluating mobile device control agents. To create a realistic benchmark, we develop B-MoCA based on the Android operating system and define 60 common daily tasks. Importantly, we incorporate a randomization feature that changes various aspects of mobile devices, including user interface layouts and language settings, to assess generalization performance. We benchmark diverse agents, including agents employing large language models (LLMs) or multi-modal LLMs as well as agents trained from scratch using human expert demonstrations. While these agents demonstrate proficiency in executing straightforward tasks, their poor performance on complex tasks highlights significant opportunities for future research to enhance their effectiveness. Our source code is publicly available at https://b-moca.github.io.
Guide Your Agent with Adaptive Multimodal Rewards
Sep 19, 2023Developing an agent capable of adapting to unseen environments remains a difficult challenge in imitation learning. In this work, we present Adaptive Return-conditioned Policy (ARP), an efficient framework designed to enhance the agent's generalization ability using natural language task descriptions and pre-trained multimodal encoders. Our key idea is to calculate a similarity between visual observations and natural language instructions in the pre-trained multimodal embedding space (such as CLIP) and use it as a reward signal. We then train a return-conditioned policy using expert demonstrations labeled with multimodal rewards. Because the multimodal rewards provide adaptive signals at each timestep, our ARP effectively mitigates the goal misgeneralization. This results in superior generalization performances even when faced with unseen text instructions, compared to existing text-conditioned policies. To improve the quality of rewards, we also introduce a fine-tuning method for pre-trained multimodal encoders, further enhancing the performance. Video demonstrations and source code are available on the project website: https://sites.google.com/view/2023arp.
Preference Transformer: Modeling Human Preferences using Transformers for RL
Mar 02, 2023Preference-based reinforcement learning (RL) provides a framework to train agents using human preferences between two behaviors. However, preference-based RL has been challenging to scale since it requires a large amount of human feedback to learn a reward function aligned with human intent. In this paper, we present Preference Transformer, a neural architecture that models human preferences using transformers. Unlike prior approaches assuming human judgment is based on the Markovian rewards which contribute to the decision equally, we introduce a new preference model based on the weighted sum of non-Markovian rewards. We then design the proposed preference model using a transformer architecture that stacks causal and bidirectional self-attention layers. We demonstrate that Preference Transformer can solve a variety of control tasks using real human preferences, while prior approaches fail to work. We also show that Preference Transformer can induce a well-specified reward and attend to critical events in the trajectory by automatically capturing the temporal dependencies in human decision-making. Code is available on the project website: https://sites.google.com/view/preference-transformer.