 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTETO: Tracking Events with Teacher Observation for Motion Estimation and Frame Interpolation
Mar 24, 2026Event cameras capture per-pixel brightness changes with microsecond resolution, offering continuous motion information lost between RGB frames. However, existing event-based motion estimators depend on large-scale synthetic data that often suffers from a significant sim-to-real gap. We propose TETO (Tracking Events with Teacher Observation), a teacher-student framework that learns event motion estimation from only $\sim$25 minutes of unannotated real-world recordings through knowledge distillation from a pretrained RGB tracker. Our motion-aware data curation and query sampling strategy maximizes learning from limited data by disentangling object motion from dominant ego-motion. The resulting estimator jointly predicts point trajectories and dense optical flow, which we leverage as explicit motion priors to condition a pretrained video diffusion transformer for frame interpolation. We achieve state-of-the-art point tracking on EVIMO2 and optical flow on DSEC using orders of magnitude less training data, and demonstrate that accurate motion estimation translates directly to superior frame interpolation quality on BS-ERGB and HQ-EVFI.
Moving Beyond Sparse Grounding with Complete Screen Parsing Supervision
Feb 15, 2026Modern computer-use agents (CUA) must perceive a screen as a structured state, what elements are visible, where they are, and what text they contain, before they can reliably ground instructions and act. Yet, most available grounding datasets provide sparse supervision, with insufficient and low-diversity labels that annotate only a small subset of task-relevant elements per screen, which limits both coverage and generalization; moreover, practical deployment requires efficiency to enable low-latency, on-device use. We introduce ScreenParse, a large-scale dataset for complete screen parsing, with dense annotations of all visible UI elements (boxes, 55-class types, and text) across 771K web screenshots (21M elements). ScreenParse is generated by Webshot, an automated, scalable pipeline that renders diverse urls, extracts annotations and applies VLM-based relabeling and quality filtering. Using ScreenParse, we train ScreenVLM, a compact, 316M-parameter vision language model (VLM) that decodes a compact ScreenTag markup representation with a structure-aware loss that upweights structure-critical tokens. ScreenVLM substantially outperforms much larger foundation VLMs on dense parsing (e.g., 0.592 vs. 0.294 PageIoU on ScreenParse) and shows strong transfer to public benchmarks. Moreover, finetuning foundation VLMs on ScreenParse consistently improves their grounding performance, suggesting that dense screen supervision provides transferable structural priors for UI understanding. Project page: https://saidgurbuz.github.io/screenparse/.
LitePT: Lighter Yet Stronger Point Transformer
Dec 15, 2025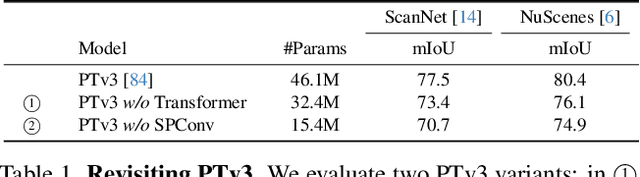
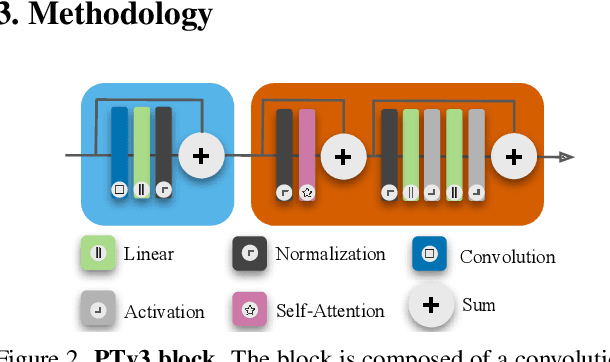
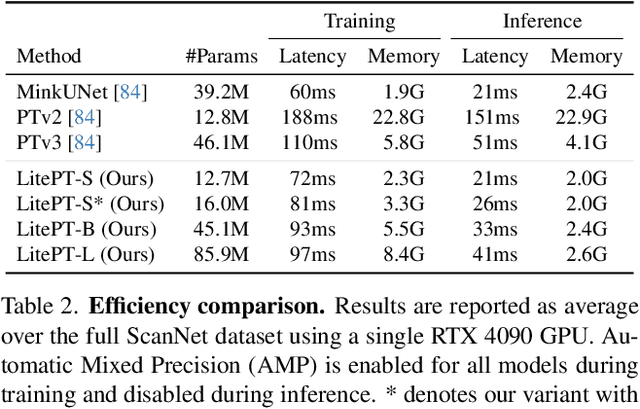
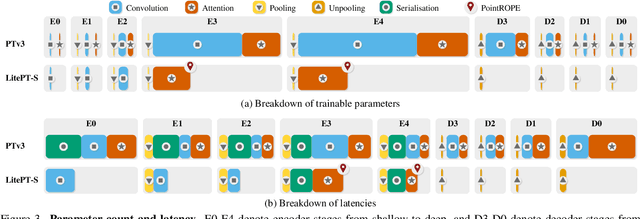
Modern neural architectures for 3D point cloud processing contain both convolutional layers and attention blocks, but the best way to assemble them remains unclear. We analyse the role of different computational blocks in 3D point cloud networks and find an intuitive behaviour: convolution is adequate to extract low-level geometry at high-resolution in early layers, where attention is expensive without bringing any benefits; attention captures high-level semantics and context in low-resolution, deep layers more efficiently. Guided by this design principle, we propose a new, improved 3D point cloud backbone that employs convolutions in early stages and switches to attention for deeper layers. To avoid the loss of spatial layout information when discarding redundant convolution layers, we introduce a novel, training-free 3D positional encoding, PointROPE. The resulting LitePT model has $3.6\times$ fewer parameters, runs $2\times$ faster, and uses $2\times$ less memory than the state-of-the-art Point Transformer V3, but nonetheless matches or even outperforms it on a range of tasks and datasets. Code and models are available at: https://github.com/prs-eth/LitePT.
Visual Representation Alignment for Multimodal Large Language Models
Sep 09, 2025Multimodal large language models (MLLMs) trained with visual instruction tuning have achieved strong performance across diverse tasks, yet they remain limited in vision-centric tasks such as object counting or spatial reasoning. We attribute this gap to the prevailing text-only supervision paradigm, which provides only indirect guidance for the visual pathway and often leads MLLMs to discard fine-grained visual details during training. In this paper, we present VIsual Representation ALignment (VIRAL), a simple yet effective regularization strategy that aligns the internal visual representations of MLLMs with those of pre-trained vision foundation models (VFMs). By explicitly enforcing this alignment, VIRAL enables the model not only to retain critical visual details from the input vision encoder but also to complement additional visual knowledge from VFMs, thereby enhancing its ability to reason over complex visual inputs. Our experiments demonstrate consistent improvements across all tasks on widely adopted multimodal benchmarks. Furthermore, we conduct comprehensive ablation studies to validate the key design choices underlying our framework. We believe this simple finding opens up an important direction for the effective integration of visual information in training MLLMs.
D^2USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Apr 08, 2025We address the task of 3D reconstruction in dynamic scenes, where object motions degrade the quality of previous 3D pointmap regression methods, such as DUSt3R, originally designed for static 3D scene reconstruction. Although these methods provide an elegant and powerful solution in static settings, they struggle in the presence of dynamic motions that disrupt alignment based solely on camera poses. To overcome this, we propose D^2USt3R that regresses 4D pointmaps that simultaneiously capture both static and dynamic 3D scene geometry in a feed-forward manner. By explicitly incorporating both spatial and temporal aspects, our approach successfully encapsulates spatio-temporal dense correspondence to the proposed 4D pointmaps, enhancing downstream tasks. Extensive experimental evaluations demonstrate that our proposed approach consistently achieves superior reconstruction performance across various datasets featuring complex motions.
Cross-View Completion Models are Zero-shot Correspondence Estimators
Dec 12, 2024In this work, we explore new perspectives on cross-view completion learning by drawing an analogy to self-supervised correspondence learning. Through our analysis, we demonstrate that the cross-attention map within cross-view completion models captures correspondence more effectively than other correlations derived from encoder or decoder features. We verify the effectiveness of the cross-attention map by evaluating on both zero-shot matching and learning-based geometric matching and multi-frame depth estimation. Project page is available at https://cvlab-kaist.github.io/ZeroCo/.
PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting
Oct 29, 2024We consider the problem of novel view synthesis from unposed images in a single feed-forward. Our framework capitalizes on fast speed, scalability, and high-quality 3D reconstruction and view synthesis capabilities of 3DGS, where we further extend it to offer a practical solution that relaxes common assumptions such as dense image views, accurate camera poses, and substantial image overlaps. We achieve this through identifying and addressing unique challenges arising from the use of pixel-aligned 3DGS: misaligned 3D Gaussians across different views induce noisy or sparse gradients that destabilize training and hinder convergence, especially when above assumptions are not met. To mitigate this, we employ pre-trained monocular depth estimation and visual correspondence models to achieve coarse alignments of 3D Gaussians. We then introduce lightweight, learnable modules to refine depth and pose estimates from the coarse alignments, improving the quality of 3D reconstruction and novel view synthesis. Furthermore, the refined estimates are leveraged to estimate geometry confidence scores, which assess the reliability of 3D Gaussian centers and condition the prediction of Gaussian parameters accordingly. Extensive evaluations on large-scale real-world datasets demonstrate that PF3plat sets a new state-of-the-art across all benchmarks, supported by comprehensive ablation studies validating our design choices.
Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Sep 30, 2024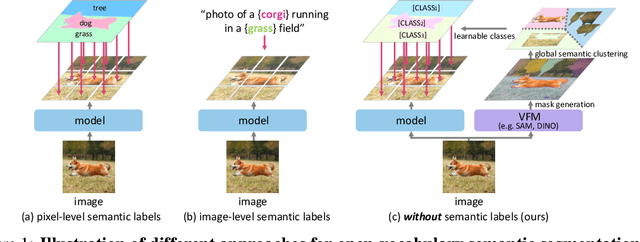
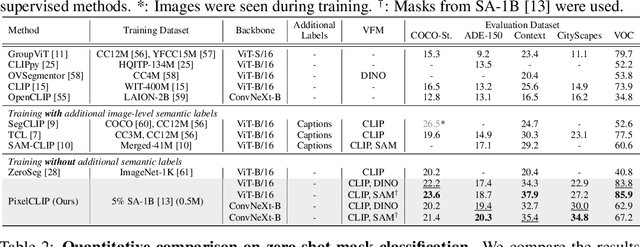

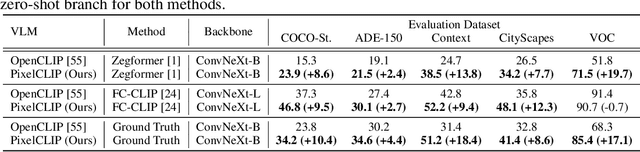
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP
Unifying Feature and Cost Aggregation with Transformers for Semantic and Visual Correspondence
Mar 17, 2024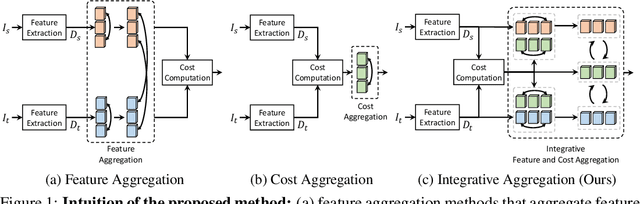
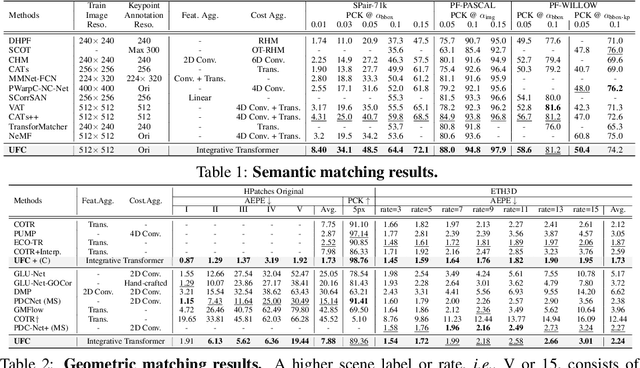


This paper introduces a Transformer-based integrative feature and cost aggregation network designed for dense matching tasks. In the context of dense matching, many works benefit from one of two forms of aggregation: feature aggregation, which pertains to the alignment of similar features, or cost aggregation, a procedure aimed at instilling coherence in the flow estimates across neighboring pixels. In this work, we first show that feature aggregation and cost aggregation exhibit distinct characteristics and reveal the potential for substantial benefits stemming from the judicious use of both aggregation processes. We then introduce a simple yet effective architecture that harnesses self- and cross-attention mechanisms to show that our approach unifies feature aggregation and cost aggregation and effectively harnesses the strengths of both techniques. Within the proposed attention layers, the features and cost volume both complement each other, and the attention layers are interleaved through a coarse-to-fine design to further promote accurate correspondence estimation. Finally at inference, our network produces multi-scale predictions, computes their confidence scores, and selects the most confident flow for final prediction. Our framework is evaluated on standard benchmarks for semantic matching, and also applied to geometric matching, where we show that our approach achieves significant improvements compared to existing methods.
Unifying Correspondence, Pose and NeRF for Pose-Free Novel View Synthesis from Stereo Pairs
Dec 12, 2023



This work delves into the task of pose-free novel view synthesis from stereo pairs, a challenging and pioneering task in 3D vision. Our innovative framework, unlike any before, seamlessly integrates 2D correspondence matching, camera pose estimation, and NeRF rendering, fostering a synergistic enhancement of these tasks. We achieve this through designing an architecture that utilizes a shared representation, which serves as a foundation for enhanced 3D geometry understanding. Capitalizing on the inherent interplay between the tasks, our unified framework is trained end-to-end with the proposed training strategy to improve overall model accuracy. Through extensive evaluations across diverse indoor and outdoor scenes from two real-world datasets, we demonstrate that our approach achieves substantial improvement over previous methodologies, especially in scenarios characterized by extreme viewpoint changes and the absence of accurate camera poses.