 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation
Paper and Code

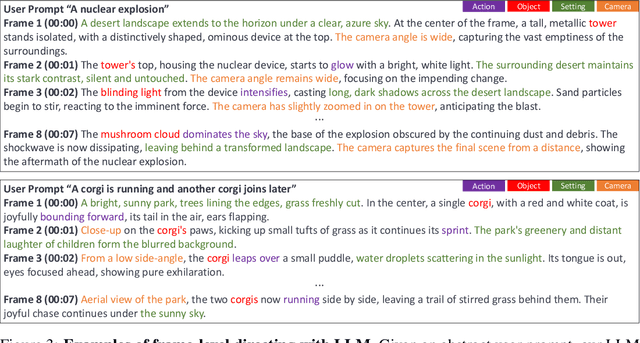
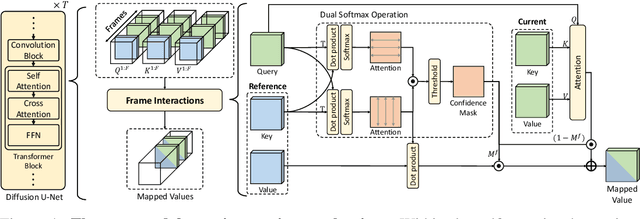
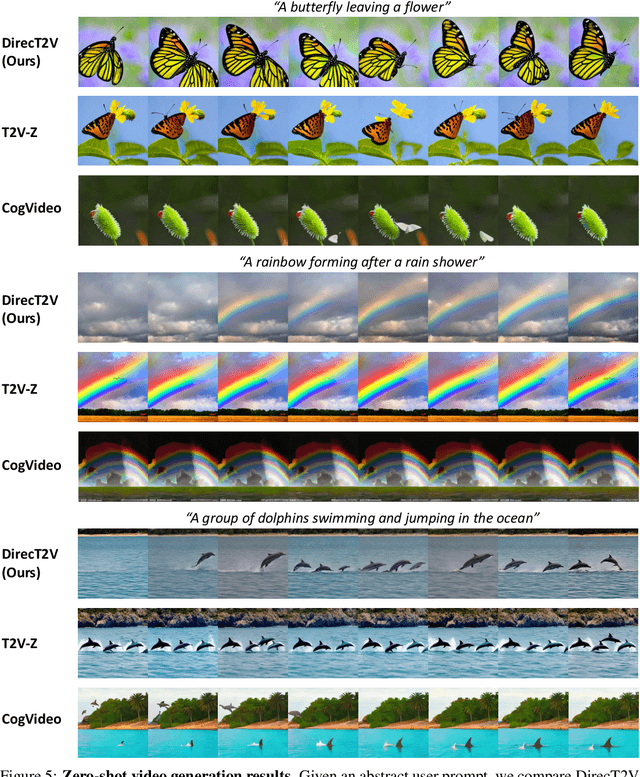
In the paradigm of AI-generated content (AIGC), there has been increasing attention in extending pre-trained text-to-image (T2I) models to text-to-video (T2V) generation. Despite their effectiveness, these frameworks face challenges in maintaining consistent narratives and handling rapid shifts in scene composition or object placement from a single user prompt. This paper introduces a new framework, dubbed DirecT2V, which leverages instruction-tuned large language models (LLMs) to generate frame-by-frame descriptions from a single abstract user prompt. DirecT2V utilizes LLM directors to divide user inputs into separate prompts for each frame, enabling the inclusion of time-varying content and facilitating consistent video generation. To maintain temporal consistency and prevent object collapse, we propose a novel value mapping method and dual-softmax filtering. Extensive experimental results validate the effectiveness of the DirecT2V framework in producing visually coherent and consistent videos from abstract user prompts, addressing the challenges of zero-shot video generation.