 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusionBrowser: Interactive Diffusion Previews via Multi-Branch Decoders
Dec 15, 2025
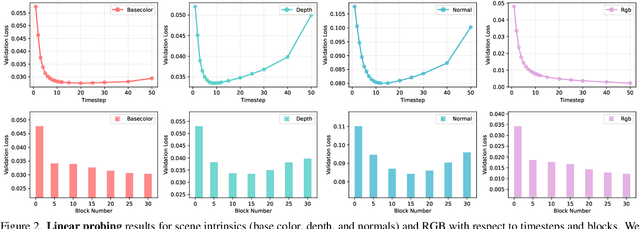


Video diffusion models have revolutionized generative video synthesis, but they are imprecise, slow, and can be opaque during generation -- keeping users in the dark for a prolonged period. In this work, we propose DiffusionBrowser, a model-agnostic, lightweight decoder framework that allows users to interactively generate previews at any point (timestep or transformer block) during the denoising process. Our model can generate multi-modal preview representations that include RGB and scene intrinsics at more than 4$\times$ real-time speed (less than 1 second for a 4-second video) that convey consistent appearance and motion to the final video. With the trained decoder, we show that it is possible to interactively guide the generation at intermediate noise steps via stochasticity reinjection and modal steering, unlocking a new control capability. Moreover, we systematically probe the model using the learned decoders, revealing how scene, object, and other details are composed and assembled during the otherwise black-box denoising process.
TAG:Tangential Amplifying Guidance for Hallucination-Resistant Diffusion Sampling
Oct 06, 2025Recent diffusion models achieve the state-of-the-art performance in image generation, but often suffer from semantic inconsistencies or hallucinations. While various inference-time guidance methods can enhance generation, they often operate indirectly by relying on external signals or architectural modifications, which introduces additional computational overhead. In this paper, we propose Tangential Amplifying Guidance (TAG), a more efficient and direct guidance method that operates solely on trajectory signals without modifying the underlying diffusion model. TAG leverages an intermediate sample as a projection basis and amplifies the tangential components of the estimated scores with respect to this basis to correct the sampling trajectory. We formalize this guidance process by leveraging a first-order Taylor expansion, which demonstrates that amplifying the tangential component steers the state toward higher-probability regions, thereby reducing inconsistencies and enhancing sample quality. TAG is a plug-and-play, architecture-agnostic module that improves diffusion sampling fidelity with minimal computational addition, offering a new perspective on diffusion guidance.
Fine-Grained Perturbation Guidance via Attention Head Selection
Jun 12, 2025Recent guidance methods in diffusion models steer reverse sampling by perturbing the model to construct an implicit weak model and guide generation away from it. Among these approaches, attention perturbation has demonstrated strong empirical performance in unconditional scenarios where classifier-free guidance is not applicable. However, existing attention perturbation methods lack principled approaches for determining where perturbations should be applied, particularly in Diffusion Transformer (DiT) architectures where quality-relevant computations are distributed across layers. In this paper, we investigate the granularity of attention perturbations, ranging from the layer level down to individual attention heads, and discover that specific heads govern distinct visual concepts such as structure, style, and texture quality. Building on this insight, we propose "HeadHunter", a systematic framework for iteratively selecting attention heads that align with user-centric objectives, enabling fine-grained control over generation quality and visual attributes. In addition, we introduce SoftPAG, which linearly interpolates each selected head's attention map toward an identity matrix, providing a continuous knob to tune perturbation strength and suppress artifacts. Our approach not only mitigates the oversmoothing issues of existing layer-level perturbation but also enables targeted manipulation of specific visual styles through compositional head selection. We validate our method on modern large-scale DiT-based text-to-image models including Stable Diffusion 3 and FLUX.1, demonstrating superior performance in both general quality enhancement and style-specific guidance. Our work provides the first head-level analysis of attention perturbation in diffusion models, uncovering interpretable specialization within attention layers and enabling practical design of effective perturbation strategies.
MusicInfuser: Making Video Diffusion Listen and Dance
Mar 18, 2025We introduce MusicInfuser, an approach for generating high-quality dance videos that are synchronized to a specified music track. Rather than attempting to design and train a new multimodal audio-video model, we show how existing video diffusion models can be adapted to align with musical inputs by introducing lightweight music-video cross-attention and a low-rank adapter. Unlike prior work requiring motion capture data, our approach fine-tunes only on dance videos. MusicInfuser achieves high-quality music-driven video generation while preserving the flexibility and generative capabilities of the underlying models. We introduce an evaluation framework using Video-LLMs to assess multiple dimensions of dance generation quality. The project page and code are available at https://susunghong.github.io/MusicInfuser.
Perturb-and-Revise: Flexible 3D Editing with Generative Trajectories
Dec 06, 2024The fields of 3D reconstruction and text-based 3D editing have advanced significantly with the evolution of text-based diffusion models. While existing 3D editing methods excel at modifying color, texture, and style, they struggle with extensive geometric or appearance changes, thus limiting their applications. We propose Perturb-and-Revise, which makes possible a variety of NeRF editing. First, we perturb the NeRF parameters with random initializations to create a versatile initialization. We automatically determine the perturbation magnitude through analysis of the local loss landscape. Then, we revise the edited NeRF via generative trajectories. Combined with the generative process, we impose identity-preserving gradients to refine the edited NeRF. Extensive experiments demonstrate that Perturb-and-Revise facilitates flexible, effective, and consistent editing of color, appearance, and geometry in 3D. For 360{\deg} results, please visit our project page: https://susunghong.github.io/Perturb-and-Revise.
Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling
Nov 27, 2024



Diffusion models have emerged as a powerful tool for generating high-quality images, videos, and 3D content. While sampling guidance techniques like CFG improve quality, they reduce diversity and motion. Autoguidance mitigates these issues but demands extra weak model training, limiting its practicality for large-scale models. In this work, we introduce Spatiotemporal Skip Guidance (STG), a simple training-free sampling guidance method for enhancing transformer-based video diffusion models. STG employs an implicit weak model via self-perturbation, avoiding the need for external models or additional training. By selectively skipping spatiotemporal layers, STG produces an aligned, degraded version of the original model to boost sample quality without compromising diversity or dynamic degree. Our contributions include: (1) introducing STG as an efficient, high-performing guidance technique for video diffusion models, (2) eliminating the need for auxiliary models by simulating a weak model through layer skipping, and (3) ensuring quality-enhanced guidance without compromising sample diversity or dynamics unlike CFG. For additional results, visit https://junhahyung.github.io/STGuidance.
Smoothed Energy Guidance: Guiding Diffusion Models with Reduced Energy Curvature of Attention
Aug 01, 2024



Conditional diffusion models have shown remarkable success in visual content generation, producing high-quality samples across various domains, largely due to classifier-free guidance (CFG). Recent attempts to extend guidance to unconditional models have relied on heuristic techniques, resulting in suboptimal generation quality and unintended effects. In this work, we propose Smoothed Energy Guidance (SEG), a novel training- and condition-free approach that leverages the energy-based perspective of the self-attention mechanism to enhance image generation. By defining the energy of self-attention, we introduce a method to reduce the curvature of the energy landscape of attention and use the output as the unconditional prediction. Practically, we control the curvature of the energy landscape by adjusting the Gaussian kernel parameter while keeping the guidance scale parameter fixed. Additionally, we present a query blurring method that is equivalent to blurring the entire attention weights without incurring quadratic complexity in the number of tokens. In our experiments, SEG achieves a Pareto improvement in both quality and the reduction of side effects. The code is available at \url{https://github.com/SusungHong/SEG-SDXL}.
Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting
Jun 18, 2024



3D reconstruction from multi-view images is one of the fundamental challenges in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising technique capable of real-time rendering with high-quality 3D reconstruction. This method utilizes 3D Gaussian representation and tile-based splatting techniques, bypassing the expensive neural field querying. Despite its potential, 3DGS encounters challenges, including needle-like artifacts, suboptimal geometries, and inaccurate normals, due to the Gaussians converging into anisotropic Gaussians with one dominant variance. We propose using effective rank analysis to examine the shape statistics of 3D Gaussian primitives, and identify the Gaussians indeed converge into needle-like shapes with the effective rank 1. To address this, we introduce effective rank as a regularization, which constrains the structure of the Gaussians. Our new regularization method enhances normal and geometry reconstruction while reducing needle-like artifacts. The approach can be integrated as an add-on module to other 3DGS variants, improving their quality without compromising visual fidelity.
Retrieval-Augmented Score Distillation for Text-to-3D Generation
Feb 05, 2024Text-to-3D generation has achieved significant success by incorporating powerful 2D diffusion models, but insufficient 3D prior knowledge also leads to the inconsistency of 3D geometry. Recently, since large-scale multi-view datasets have been released, fine-tuning the diffusion model on the multi-view datasets becomes a mainstream to solve the 3D inconsistency problem. However, it has confronted with fundamental difficulties regarding the limited quality and diversity of 3D data, compared with 2D data. To sidestep these trade-offs, we explore a retrieval-augmented approach tailored for score distillation, dubbed RetDream. We postulate that both expressiveness of 2D diffusion models and geometric consistency of 3D assets can be fully leveraged by employing the semantically relevant assets directly within the optimization process. To this end, we introduce novel framework for retrieval-based quality enhancement in text-to-3D generation. We leverage the retrieved asset to incorporate its geometric prior in the variational objective and adapt the diffusion model's 2D prior toward view consistency, achieving drastic improvements in both geometry and fidelity of generated scenes. We conduct extensive experiments to demonstrate that RetDream exhibits superior quality with increased geometric consistency. Project page is available at https://ku-cvlab.github.io/RetDream/.
Large Language Models are Frame-level Directors for Zero-shot Text-to-Video Generation
May 23, 2023
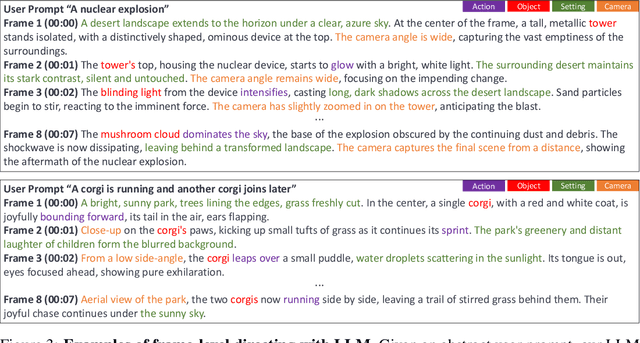
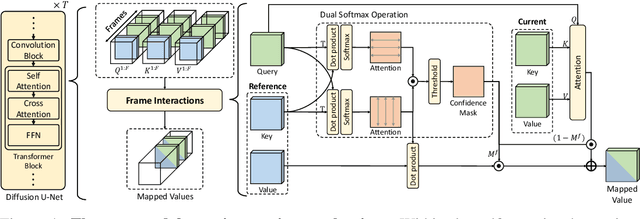
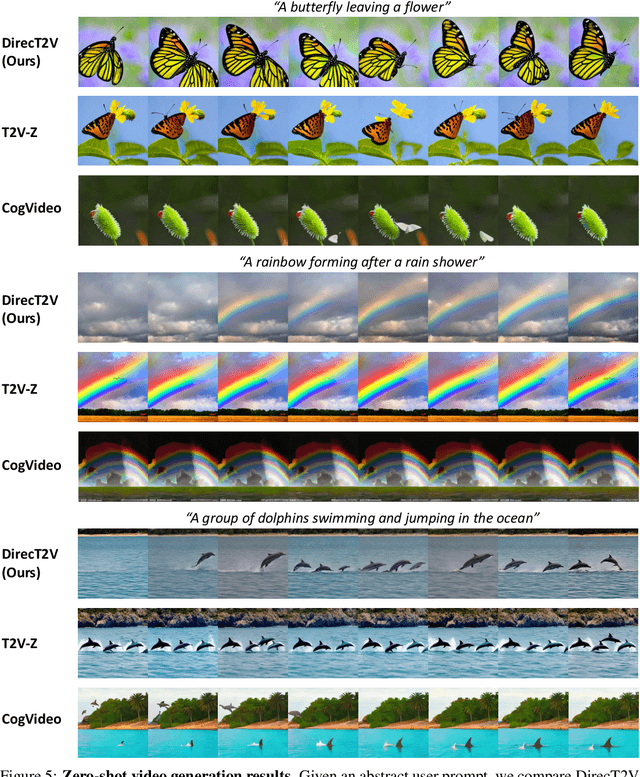
In the paradigm of AI-generated content (AIGC), there has been increasing attention in extending pre-trained text-to-image (T2I) models to text-to-video (T2V) generation. Despite their effectiveness, these frameworks face challenges in maintaining consistent narratives and handling rapid shifts in scene composition or object placement from a single user prompt. This paper introduces a new framework, dubbed DirecT2V, which leverages instruction-tuned large language models (LLMs) to generate frame-by-frame descriptions from a single abstract user prompt. DirecT2V utilizes LLM directors to divide user inputs into separate prompts for each frame, enabling the inclusion of time-varying content and facilitating consistent video generation. To maintain temporal consistency and prevent object collapse, we propose a novel value mapping method and dual-softmax filtering. Extensive experimental results validate the effectiveness of the DirecT2V framework in producing visually coherent and consistent videos from abstract user prompts, addressing the challenges of zero-shot video generation.