 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Track Any Points from Human Motion
Jul 08, 2025



Human motion, with its inherent complexities, such as non-rigid deformations, articulated movements, clothing distortions, and frequent occlusions caused by limbs or other individuals, provides a rich and challenging source of supervision that is crucial for training robust and generalizable point trackers. Despite the suitability of human motion, acquiring extensive training data for point tracking remains difficult due to laborious manual annotation. Our proposed pipeline, AnthroTAP, addresses this by proposing an automated pipeline to generate pseudo-labeled training data, leveraging the Skinned Multi-Person Linear (SMPL) model. We first fit the SMPL model to detected humans in video frames, project the resulting 3D mesh vertices onto 2D image planes to generate pseudo-trajectories, handle occlusions using ray-casting, and filter out unreliable tracks based on optical flow consistency. A point tracking model trained on AnthroTAP annotated dataset achieves state-of-the-art performance on the TAP-Vid benchmark, surpassing other models trained on real videos while using 10,000 times less data and only 1 day in 4 GPUs, compared to 256 GPUs used in recent state-of-the-art.
Exploring Temporally-Aware Features for Point Tracking
Jan 21, 2025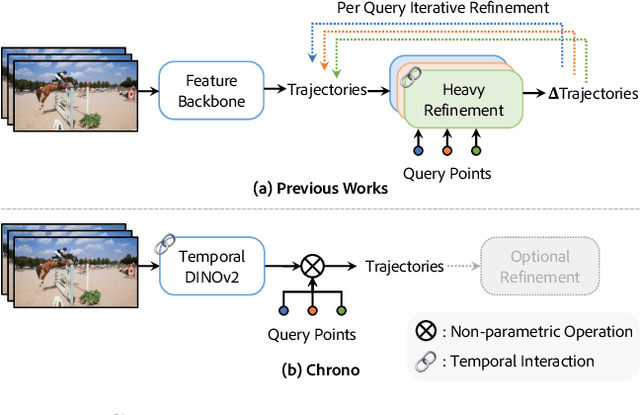
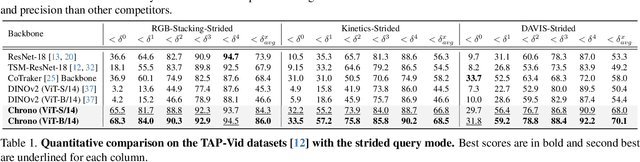


Point tracking in videos is a fundamental task with applications in robotics, video editing, and more. While many vision tasks benefit from pre-trained feature backbones to improve generalizability, point tracking has primarily relied on simpler backbones trained from scratch on synthetic data, which may limit robustness in real-world scenarios. Additionally, point tracking requires temporal awareness to ensure coherence across frames, but using temporally-aware features is still underexplored. Most current methods often employ a two-stage process: an initial coarse prediction followed by a refinement stage to inject temporal information and correct errors from the coarse stage. These approach, however, is computationally expensive and potentially redundant if the feature backbone itself captures sufficient temporal information. In this work, we introduce Chrono, a feature backbone specifically designed for point tracking with built-in temporal awareness. Leveraging pre-trained representations from self-supervised learner DINOv2 and enhanced with a temporal adapter, Chrono effectively captures long-term temporal context, enabling precise prediction even without the refinement stage. Experimental results demonstrate that Chrono achieves state-of-the-art performance in a refiner-free setting on the TAP-Vid-DAVIS and TAP-Vid-Kinetics datasets, among common feature backbones used in point tracking as well as DINOv2, with exceptional efficiency. Project page: https://cvlab-kaist.github.io/Chrono/
Pose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
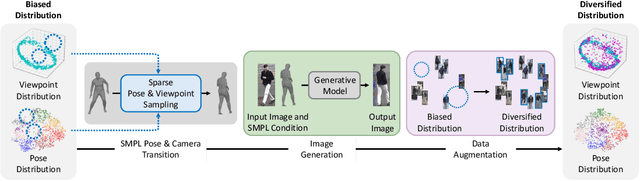
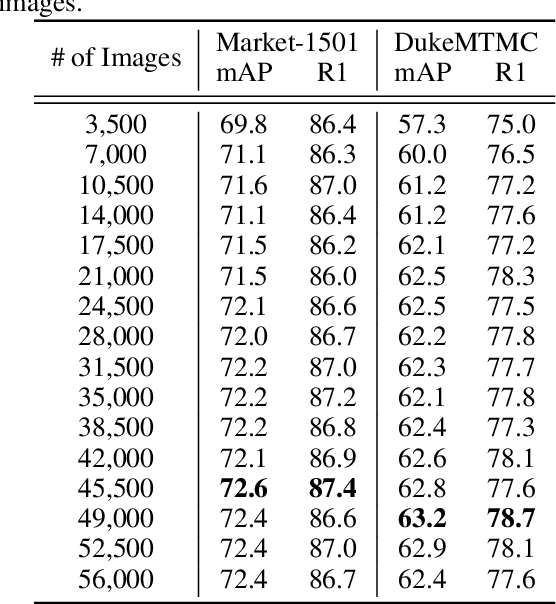
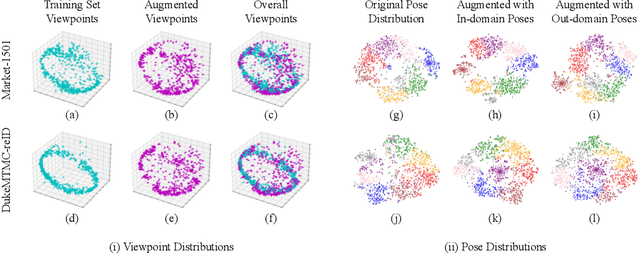
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
Retrieval-Augmented Score Distillation for Text-to-3D Generation
Feb 05, 2024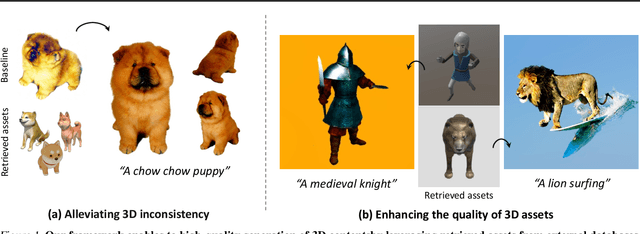
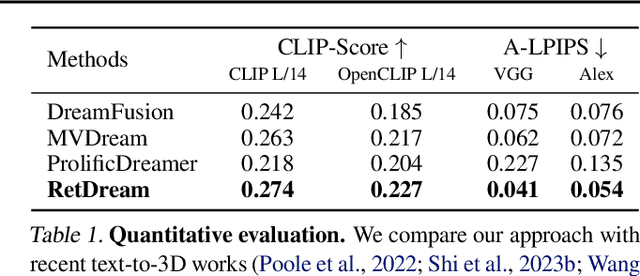
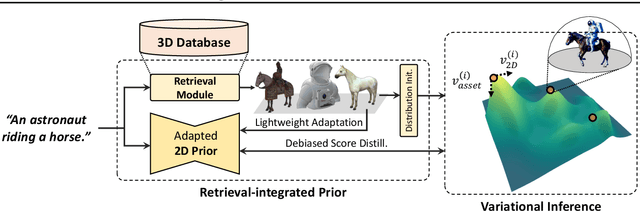

Text-to-3D generation has achieved significant success by incorporating powerful 2D diffusion models, but insufficient 3D prior knowledge also leads to the inconsistency of 3D geometry. Recently, since large-scale multi-view datasets have been released, fine-tuning the diffusion model on the multi-view datasets becomes a mainstream to solve the 3D inconsistency problem. However, it has confronted with fundamental difficulties regarding the limited quality and diversity of 3D data, compared with 2D data. To sidestep these trade-offs, we explore a retrieval-augmented approach tailored for score distillation, dubbed RetDream. We postulate that both expressiveness of 2D diffusion models and geometric consistency of 3D assets can be fully leveraged by employing the semantically relevant assets directly within the optimization process. To this end, we introduce novel framework for retrieval-based quality enhancement in text-to-3D generation. We leverage the retrieved asset to incorporate its geometric prior in the variational objective and adapt the diffusion model's 2D prior toward view consistency, achieving drastic improvements in both geometry and fidelity of generated scenes. We conduct extensive experiments to demonstrate that RetDream exhibits superior quality with increased geometric consistency. Project page is available at https://ku-cvlab.github.io/RetDream/.