 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Track Any Points from Human Motion
Jul 08, 2025



Human motion, with its inherent complexities, such as non-rigid deformations, articulated movements, clothing distortions, and frequent occlusions caused by limbs or other individuals, provides a rich and challenging source of supervision that is crucial for training robust and generalizable point trackers. Despite the suitability of human motion, acquiring extensive training data for point tracking remains difficult due to laborious manual annotation. Our proposed pipeline, AnthroTAP, addresses this by proposing an automated pipeline to generate pseudo-labeled training data, leveraging the Skinned Multi-Person Linear (SMPL) model. We first fit the SMPL model to detected humans in video frames, project the resulting 3D mesh vertices onto 2D image planes to generate pseudo-trajectories, handle occlusions using ray-casting, and filter out unreliable tracks based on optical flow consistency. A point tracking model trained on AnthroTAP annotated dataset achieves state-of-the-art performance on the TAP-Vid benchmark, surpassing other models trained on real videos while using 10,000 times less data and only 1 day in 4 GPUs, compared to 256 GPUs used in recent state-of-the-art.
Seurat: From Moving Points to Depth
Apr 20, 2025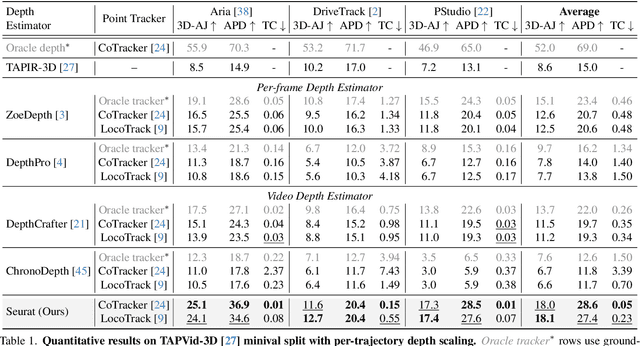
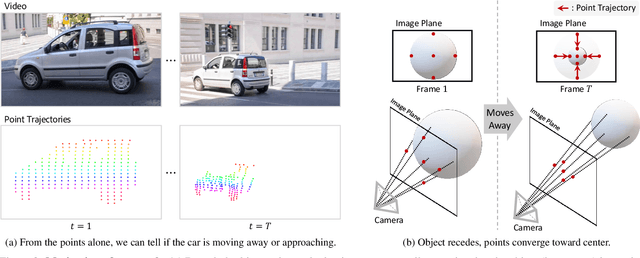
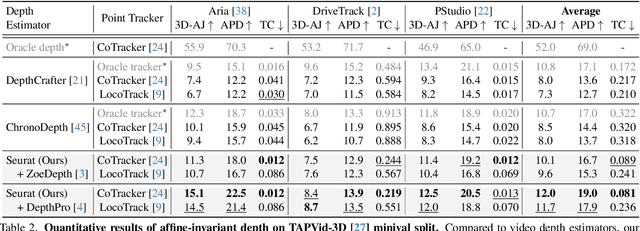
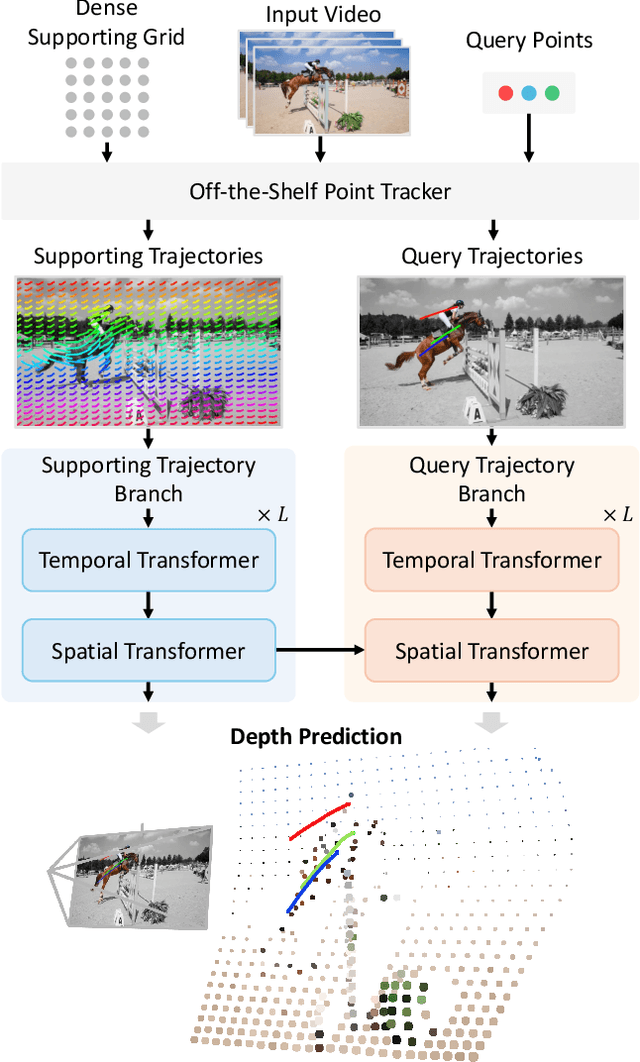
Accurate depth estimation from monocular videos remains challenging due to ambiguities inherent in single-view geometry, as crucial depth cues like stereopsis are absent. However, humans often perceive relative depth intuitively by observing variations in the size and spacing of objects as they move. Inspired by this, we propose a novel method that infers relative depth by examining the spatial relationships and temporal evolution of a set of tracked 2D trajectories. Specifically, we use off-the-shelf point tracking models to capture 2D trajectories. Then, our approach employs spatial and temporal transformers to process these trajectories and directly infer depth changes over time. Evaluated on the TAPVid-3D benchmark, our method demonstrates robust zero-shot performance, generalizing effectively from synthetic to real-world datasets. Results indicate that our approach achieves temporally smooth, high-accuracy depth predictions across diverse domains.
Exploring Temporally-Aware Features for Point Tracking
Jan 21, 2025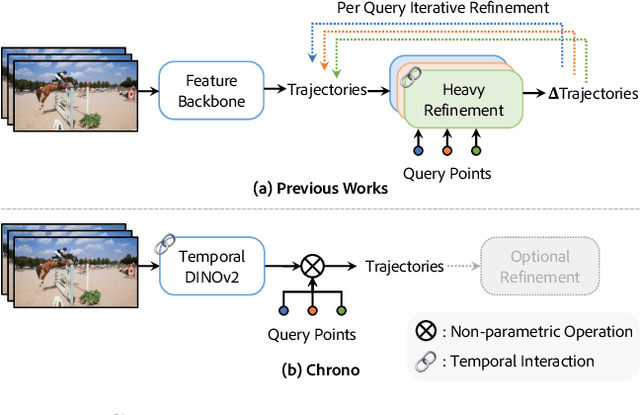
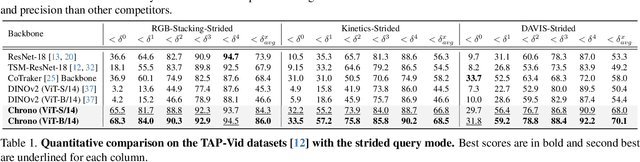


Point tracking in videos is a fundamental task with applications in robotics, video editing, and more. While many vision tasks benefit from pre-trained feature backbones to improve generalizability, point tracking has primarily relied on simpler backbones trained from scratch on synthetic data, which may limit robustness in real-world scenarios. Additionally, point tracking requires temporal awareness to ensure coherence across frames, but using temporally-aware features is still underexplored. Most current methods often employ a two-stage process: an initial coarse prediction followed by a refinement stage to inject temporal information and correct errors from the coarse stage. These approach, however, is computationally expensive and potentially redundant if the feature backbone itself captures sufficient temporal information. In this work, we introduce Chrono, a feature backbone specifically designed for point tracking with built-in temporal awareness. Leveraging pre-trained representations from self-supervised learner DINOv2 and enhanced with a temporal adapter, Chrono effectively captures long-term temporal context, enabling precise prediction even without the refinement stage. Experimental results demonstrate that Chrono achieves state-of-the-art performance in a refiner-free setting on the TAP-Vid-DAVIS and TAP-Vid-Kinetics datasets, among common feature backbones used in point tracking as well as DINOv2, with exceptional efficiency. Project page: https://cvlab-kaist.github.io/Chrono/
Multi-Granularity Video Object Segmentation
Dec 03, 2024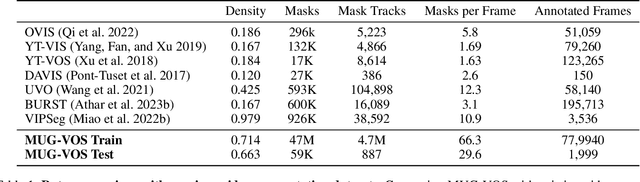
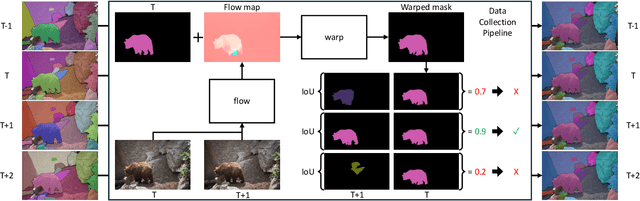


Current benchmarks for video segmentation are limited to annotating only salient objects (i.e., foreground instances). Despite their impressive architectural designs, previous works trained on these benchmarks have struggled to adapt to real-world scenarios. Thus, developing a new video segmentation dataset aimed at tracking multi-granularity segmentation target in the video scene is necessary. In this work, we aim to generate multi-granularity video segmentation dataset that is annotated for both salient and non-salient masks. To achieve this, we propose a large-scale, densely annotated multi-granularity video object segmentation (MUG-VOS) dataset that includes various types and granularities of mask annotations. We automatically collected a training set that assists in tracking both salient and non-salient objects, and we also curated a human-annotated test set for reliable evaluation. In addition, we present memory-based mask propagation model (MMPM), trained and evaluated on MUG-VOS dataset, which leads to the best performance among the existing video object segmentation methods and Segment SAM-based video segmentation methods. Project page is available at https://cvlab-kaist.github.io/MUG-VOS.
Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Sep 30, 2024
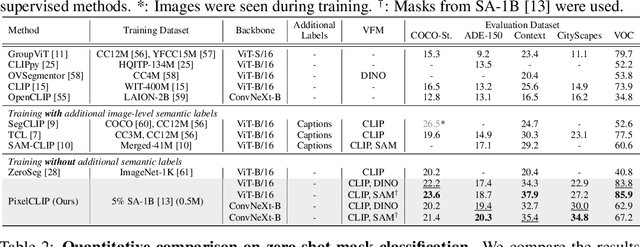

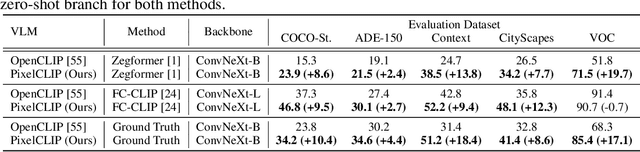
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP
Local All-Pair Correspondence for Point Tracking
Jul 22, 2024We introduce LocoTrack, a highly accurate and efficient model designed for the task of tracking any point (TAP) across video sequences. Previous approaches in this task often rely on local 2D correlation maps to establish correspondences from a point in the query image to a local region in the target image, which often struggle with homogeneous regions or repetitive features, leading to matching ambiguities. LocoTrack overcomes this challenge with a novel approach that utilizes all-pair correspondences across regions, i.e., local 4D correlation, to establish precise correspondences, with bidirectional correspondence and matching smoothness significantly enhancing robustness against ambiguities. We also incorporate a lightweight correlation encoder to enhance computational efficiency, and a compact Transformer architecture to integrate long-term temporal information. LocoTrack achieves unmatched accuracy on all TAP-Vid benchmarks and operates at a speed almost 6 times faster than the current state-of-the-art.
Pose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
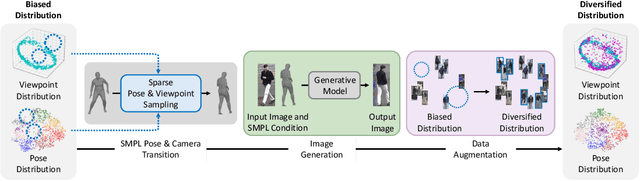
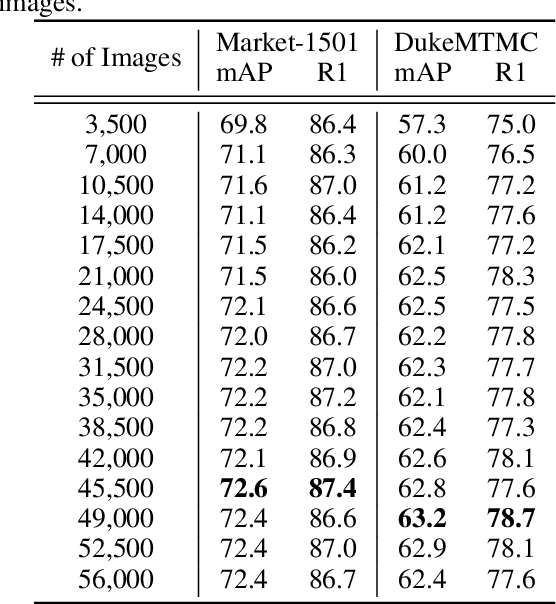
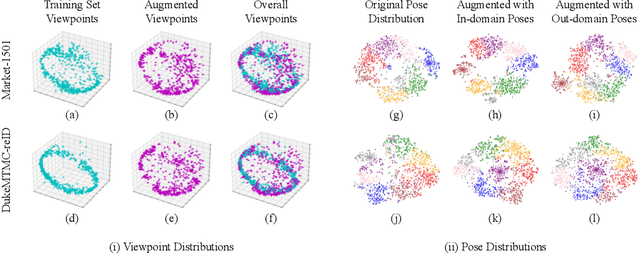
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
Unifying Feature and Cost Aggregation with Transformers for Semantic and Visual Correspondence
Mar 17, 2024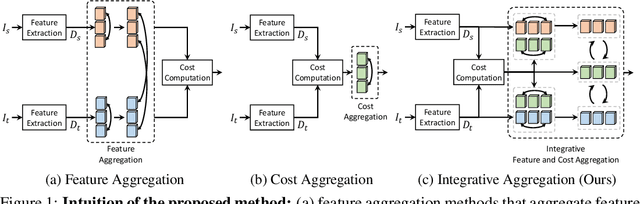
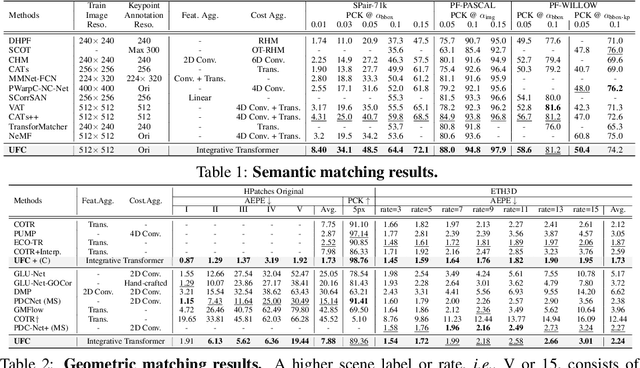


This paper introduces a Transformer-based integrative feature and cost aggregation network designed for dense matching tasks. In the context of dense matching, many works benefit from one of two forms of aggregation: feature aggregation, which pertains to the alignment of similar features, or cost aggregation, a procedure aimed at instilling coherence in the flow estimates across neighboring pixels. In this work, we first show that feature aggregation and cost aggregation exhibit distinct characteristics and reveal the potential for substantial benefits stemming from the judicious use of both aggregation processes. We then introduce a simple yet effective architecture that harnesses self- and cross-attention mechanisms to show that our approach unifies feature aggregation and cost aggregation and effectively harnesses the strengths of both techniques. Within the proposed attention layers, the features and cost volume both complement each other, and the attention layers are interleaved through a coarse-to-fine design to further promote accurate correspondence estimation. Finally at inference, our network produces multi-scale predictions, computes their confidence scores, and selects the most confident flow for final prediction. Our framework is evaluated on standard benchmarks for semantic matching, and also applied to geometric matching, where we show that our approach achieves significant improvements compared to existing methods.
DäRF: Boosting Radiance Fields from Sparse Inputs with Monocular Depth Adaptation
May 30, 2023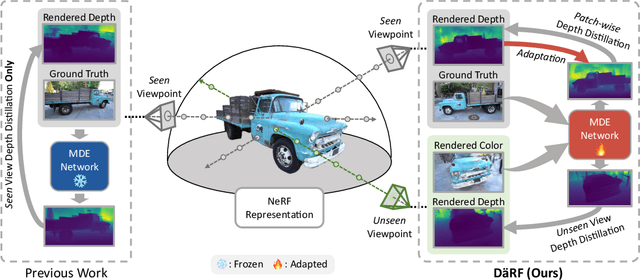
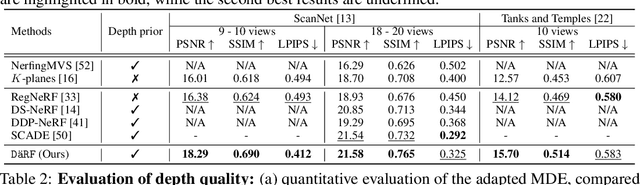

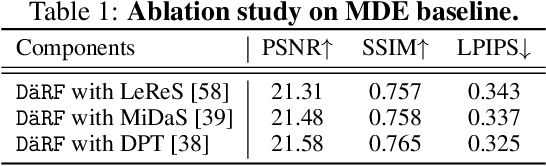
Neural radiance fields (NeRF) shows powerful performance in novel view synthesis and 3D geometry reconstruction, but it suffers from critical performance degradation when the number of known viewpoints is drastically reduced. Existing works attempt to overcome this problem by employing external priors, but their success is limited to certain types of scenes or datasets. Employing monocular depth estimation (MDE) networks, pretrained on large-scale RGB-D datasets, with powerful generalization capability would be a key to solving this problem: however, using MDE in conjunction with NeRF comes with a new set of challenges due to various ambiguity problems exhibited by monocular depths. In this light, we propose a novel framework, dubbed D\"aRF, that achieves robust NeRF reconstruction with a handful of real-world images by combining the strengths of NeRF and monocular depth estimation through online complementary training. Our framework imposes the MDE network's powerful geometry prior to NeRF representation at both seen and unseen viewpoints to enhance its robustness and coherence. In addition, we overcome the ambiguity problems of monocular depths through patch-wise scale-shift fitting and geometry distillation, which adapts the MDE network to produce depths aligned accurately with NeRF geometry. Experiments show our framework achieves state-of-the-art results both quantitatively and qualitatively, demonstrating consistent and reliable performance in both indoor and outdoor real-world datasets. Project page is available at https://ku-cvlab.github.io/DaRF/.
CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation
Mar 21, 2023Existing works on open-vocabulary semantic segmentation have utilized large-scale vision-language models, such as CLIP, to leverage their exceptional open-vocabulary recognition capabilities. However, the problem of transferring these capabilities learned from image-level supervision to the pixel-level task of segmentation and addressing arbitrary unseen categories at inference makes this task challenging. To address these issues, we aim to attentively relate objects within an image to given categories by leveraging relational information among class categories and visual semantics through aggregation, while also adapting the CLIP representations to the pixel-level task. However, we observe that direct optimization of the CLIP embeddings can harm its open-vocabulary capabilities. In this regard, we propose an alternative approach to optimize the image-text similarity map, i.e. the cost map, using a novel cost aggregation-based method. Our framework, namely CAT-Seg, achieves state-of-the-art performance across all benchmarks. We provide extensive ablation studies to validate our choices. Project page: https://ku-cvlab.github.io/CAT-Seg/.