 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned Novel View Image and Geometry Synthesis via Cross-modal Attention Instillation
Jun 13, 2025We introduce a diffusion-based framework that performs aligned novel view image and geometry generation via a warping-and-inpainting methodology. Unlike prior methods that require dense posed images or pose-embedded generative models limited to in-domain views, our method leverages off-the-shelf geometry predictors to predict partial geometries viewed from reference images, and formulates novel-view synthesis as an inpainting task for both image and geometry. To ensure accurate alignment between generated images and geometry, we propose cross-modal attention distillation, where attention maps from the image diffusion branch are injected into a parallel geometry diffusion branch during both training and inference. This multi-task approach achieves synergistic effects, facilitating geometrically robust image synthesis as well as well-defined geometry prediction. We further introduce proximity-based mesh conditioning to integrate depth and normal cues, interpolating between point cloud and filtering erroneously predicted geometry from influencing the generation process. Empirically, our method achieves high-fidelity extrapolative view synthesis on both image and geometry across a range of unseen scenes, delivers competitive reconstruction quality under interpolation settings, and produces geometrically aligned colored point clouds for comprehensive 3D completion. Project page is available at https://cvlab-kaist.github.io/MoAI.
Geometry-Aware Score Distillation via 3D Consistent Noising and Gradient Consistency Modeling
Jun 24, 2024



Score distillation sampling (SDS), the methodology in which the score from pretrained 2D diffusion models is distilled into 3D representation, has recently brought significant advancements in text-to-3D generation task. However, this approach is still confronted with critical geometric inconsistency problems such as the Janus problem. Starting from a hypothesis that such inconsistency problems may be induced by multiview inconsistencies between 2D scores predicted from various viewpoints, we introduce GSD, a simple and general plug-and-play framework for incorporating 3D consistency and therefore geometry awareness into the SDS process. Our methodology is composed of three components: 3D consistent noising, designed to produce 3D consistent noise maps that perfectly follow the standard Gaussian distribution, geometry-based gradient warping for identifying correspondences between predicted gradients of different viewpoints, and novel gradient consistency loss to optimize the scene geometry toward producing more consistent gradients. We demonstrate that our method significantly improves performance, successfully addressing the geometric inconsistency problems in text-to-3D generation task with minimal computation cost and being compatible with existing score distillation-based models. Our project page is available at https://ku-cvlab.github.io/GSD/.
Pose-Diversified Augmentation with Diffusion Model for Person Re-Identification
Jun 23, 2024
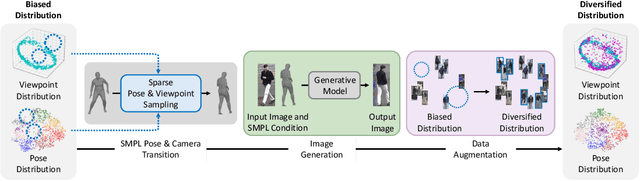
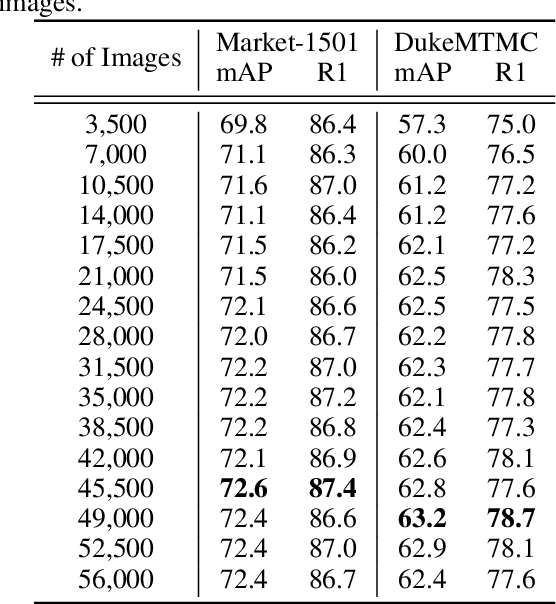
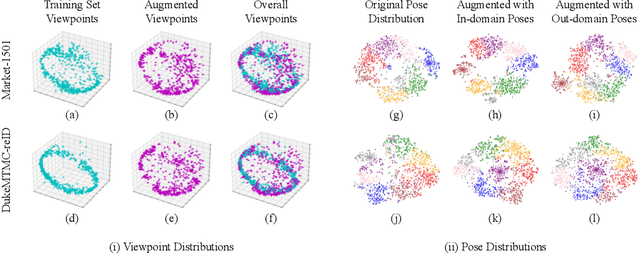
Person re-identification (Re-ID) often faces challenges due to variations in human poses and camera viewpoints, which significantly affect the appearance of individuals across images. Existing datasets frequently lack diversity and scalability in these aspects, hindering the generalization of Re-ID models to new camera systems. Previous methods have attempted to address these issues through data augmentation; however, they rely on human poses already present in the training dataset, failing to effectively reduce the human pose bias in the dataset. We propose Diff-ID, a novel data augmentation approach that incorporates sparse and underrepresented human pose and camera viewpoint examples into the training data, addressing the limited diversity in the original training data distribution. Our objective is to augment a training dataset that enables existing Re-ID models to learn features unbiased by human pose and camera viewpoint variations. To achieve this, we leverage the knowledge of pre-trained large-scale diffusion models. Using the SMPL model, we simultaneously capture both the desired human poses and camera viewpoints, enabling realistic human rendering. The depth information provided by the SMPL model indirectly conveys the camera viewpoints. By conditioning the diffusion model on both the human pose and camera viewpoint concurrently through the SMPL model, we generate realistic images with diverse human poses and camera viewpoints. Qualitative results demonstrate the effectiveness of our method in addressing human pose bias and enhancing the generalizability of Re-ID models compared to other data augmentation-based Re-ID approaches. The performance gains achieved by training Re-ID models on our offline augmented dataset highlight the potential of our proposed framework in improving the scalability and generalizability of person Re-ID models.
Self-Evolving Neural Radiance Fields
Dec 05, 2023Recently, neural radiance field (NeRF) has shown remarkable performance in novel view synthesis and 3D reconstruction. However, it still requires abundant high-quality images, limiting its applicability in real-world scenarios. To overcome this limitation, recent works have focused on training NeRF only with sparse viewpoints by giving additional regularizations, often called few-shot NeRF. We observe that due to the under-constrained nature of the task, solely using additional regularization is not enough to prevent the model from overfitting to sparse viewpoints. In this paper, we propose a novel framework, dubbed Self-Evolving Neural Radiance Fields (SE-NeRF), that applies a self-training framework to NeRF to address these problems. We formulate few-shot NeRF into a teacher-student framework to guide the network to learn a more robust representation of the scene by training the student with additional pseudo labels generated from the teacher. By distilling ray-level pseudo labels using distinct distillation schemes for reliable and unreliable rays obtained with our novel reliability estimation method, we enable NeRF to learn a more accurate and robust geometry of the 3D scene. We show and evaluate that applying our self-training framework to existing models improves the quality of the rendered images and achieves state-of-the-art performance in multiple settings.
DäRF: Boosting Radiance Fields from Sparse Inputs with Monocular Depth Adaptation
May 30, 2023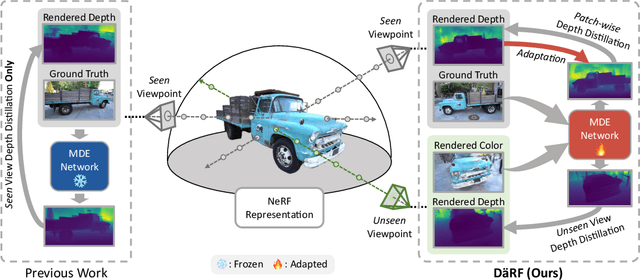
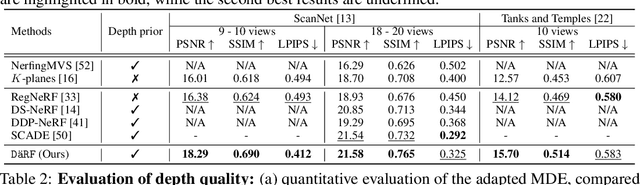

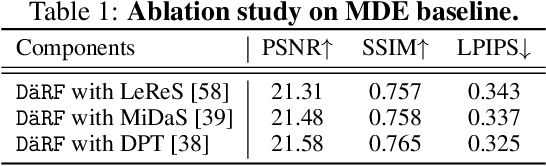
Neural radiance fields (NeRF) shows powerful performance in novel view synthesis and 3D geometry reconstruction, but it suffers from critical performance degradation when the number of known viewpoints is drastically reduced. Existing works attempt to overcome this problem by employing external priors, but their success is limited to certain types of scenes or datasets. Employing monocular depth estimation (MDE) networks, pretrained on large-scale RGB-D datasets, with powerful generalization capability would be a key to solving this problem: however, using MDE in conjunction with NeRF comes with a new set of challenges due to various ambiguity problems exhibited by monocular depths. In this light, we propose a novel framework, dubbed D\"aRF, that achieves robust NeRF reconstruction with a handful of real-world images by combining the strengths of NeRF and monocular depth estimation through online complementary training. Our framework imposes the MDE network's powerful geometry prior to NeRF representation at both seen and unseen viewpoints to enhance its robustness and coherence. In addition, we overcome the ambiguity problems of monocular depths through patch-wise scale-shift fitting and geometry distillation, which adapts the MDE network to produce depths aligned accurately with NeRF geometry. Experiments show our framework achieves state-of-the-art results both quantitatively and qualitatively, demonstrating consistent and reliable performance in both indoor and outdoor real-world datasets. Project page is available at https://ku-cvlab.github.io/DaRF/.
Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
Mar 16, 2023
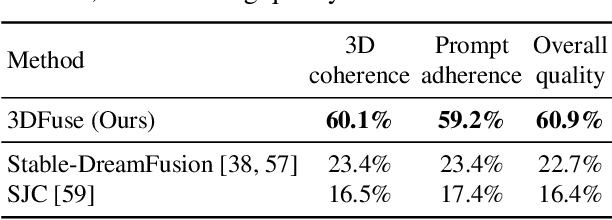
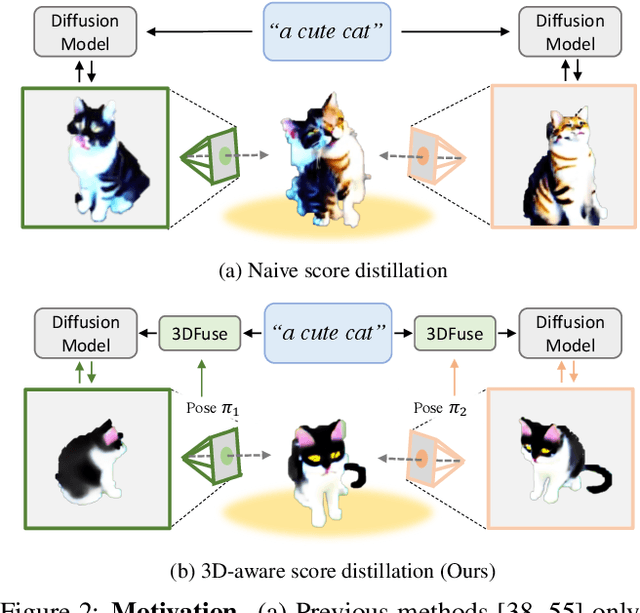
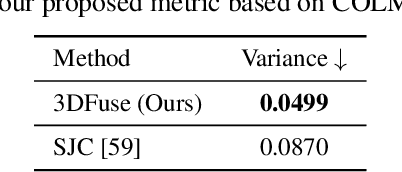
Text-to-3D generation has shown rapid progress in recent days with the advent of score distillation, a methodology of using pretrained text-to-2D diffusion models to optimize neural radiance field (NeRF) in the zero-shot setting. However, the lack of 3D awareness in the 2D diffusion models destabilizes score distillation-based methods from reconstructing a plausible 3D scene. To address this issue, we propose 3DFuse, a novel framework that incorporates 3D awareness into pretrained 2D diffusion models, enhancing the robustness and 3D consistency of score distillation-based methods. We realize this by first constructing a coarse 3D structure of a given text prompt and then utilizing projected, view-specific depth map as a condition for the diffusion model. Additionally, we introduce a training strategy that enables the 2D diffusion model learns to handle the errors and sparsity within the coarse 3D structure for robust generation, as well as a method for ensuring semantic consistency throughout all viewpoints of the scene. Our framework surpasses the limitations of prior arts, and has significant implications for 3D consistent generation of 2D diffusion models.