 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMATRIX: Mask Track Alignment for Interaction-aware Video Generation
Oct 08, 2025



Video DiTs have advanced video generation, yet they still struggle to model multi-instance or subject-object interactions. This raises a key question: How do these models internally represent interactions? To answer this, we curate MATRIX-11K, a video dataset with interaction-aware captions and multi-instance mask tracks. Using this dataset, we conduct a systematic analysis that formalizes two perspectives of video DiTs: semantic grounding, via video-to-text attention, which evaluates whether noun and verb tokens capture instances and their relations; and semantic propagation, via video-to-video attention, which assesses whether instance bindings persist across frames. We find both effects concentrate in a small subset of interaction-dominant layers. Motivated by this, we introduce MATRIX, a simple and effective regularization that aligns attention in specific layers of video DiTs with multi-instance mask tracks from the MATRIX-11K dataset, enhancing both grounding and propagation. We further propose InterGenEval, an evaluation protocol for interaction-aware video generation. In experiments, MATRIX improves both interaction fidelity and semantic alignment while reducing drift and hallucination. Extensive ablations validate our design choices. Codes and weights will be released.
Multi-Granularity Video Object Segmentation
Dec 03, 2024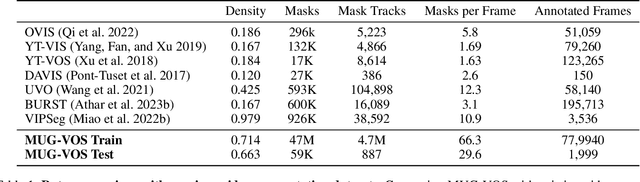
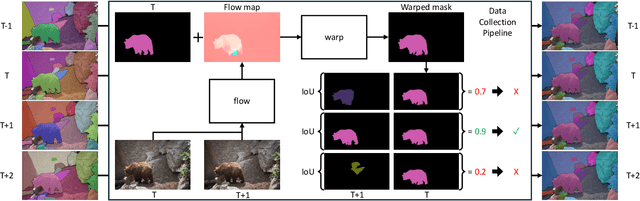


Current benchmarks for video segmentation are limited to annotating only salient objects (i.e., foreground instances). Despite their impressive architectural designs, previous works trained on these benchmarks have struggled to adapt to real-world scenarios. Thus, developing a new video segmentation dataset aimed at tracking multi-granularity segmentation target in the video scene is necessary. In this work, we aim to generate multi-granularity video segmentation dataset that is annotated for both salient and non-salient masks. To achieve this, we propose a large-scale, densely annotated multi-granularity video object segmentation (MUG-VOS) dataset that includes various types and granularities of mask annotations. We automatically collected a training set that assists in tracking both salient and non-salient objects, and we also curated a human-annotated test set for reliable evaluation. In addition, we present memory-based mask propagation model (MMPM), trained and evaluated on MUG-VOS dataset, which leads to the best performance among the existing video object segmentation methods and Segment SAM-based video segmentation methods. Project page is available at https://cvlab-kaist.github.io/MUG-VOS.
Referring Video Object Segmentation via Language-aligned Track Selection
Dec 02, 2024Referring Video Object Segmentation (RVOS) seeks to segment objects throughout a video based on natural language expressions. While existing methods have made strides in vision-language alignment, they often overlook the importance of robust video object tracking, where inconsistent mask tracks can disrupt vision-language alignment, leading to suboptimal performance. In this work, we present Selection by Object Language Alignment (SOLA), a novel framework that reformulates RVOS into two sub-problems, track generation and track selection. In track generation, we leverage a vision foundation model, Segment Anything Model 2 (SAM2), which generates consistent mask tracks across frames, producing reliable candidates for both foreground and background objects. For track selection, we propose a light yet effective selection module that aligns visual and textual features while modeling object appearance and motion within video sequences. This design enables precise motion modeling and alignment of the vision language. Our approach achieves state-of-the-art performance on the challenging MeViS dataset and demonstrates superior results in zero-shot settings on the Ref-Youtube-VOS and Ref-DAVIS datasets. Furthermore, SOLA exhibits strong generalization and robustness in corrupted settings, such as those with added Gaussian noise or motion blur. Our project page is available at https://cvlab-kaist.github.io/SOLA
Self-Evolving Neural Radiance Fields
Dec 05, 2023Recently, neural radiance field (NeRF) has shown remarkable performance in novel view synthesis and 3D reconstruction. However, it still requires abundant high-quality images, limiting its applicability in real-world scenarios. To overcome this limitation, recent works have focused on training NeRF only with sparse viewpoints by giving additional regularizations, often called few-shot NeRF. We observe that due to the under-constrained nature of the task, solely using additional regularization is not enough to prevent the model from overfitting to sparse viewpoints. In this paper, we propose a novel framework, dubbed Self-Evolving Neural Radiance Fields (SE-NeRF), that applies a self-training framework to NeRF to address these problems. We formulate few-shot NeRF into a teacher-student framework to guide the network to learn a more robust representation of the scene by training the student with additional pseudo labels generated from the teacher. By distilling ray-level pseudo labels using distinct distillation schemes for reliable and unreliable rays obtained with our novel reliability estimation method, we enable NeRF to learn a more accurate and robust geometry of the 3D scene. We show and evaluate that applying our self-training framework to existing models improves the quality of the rendered images and achieves state-of-the-art performance in multiple settings.
PSIque: Next Sequence Prediction of Satellite Images using a Convolutional Sequence-to-Sequence Network
Nov 30, 2017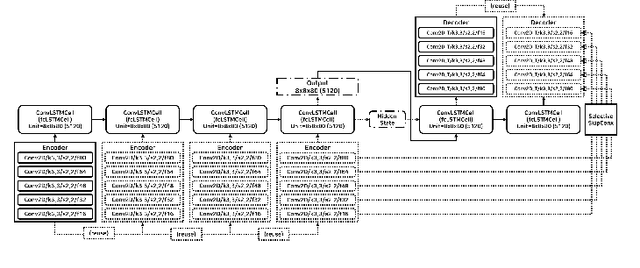

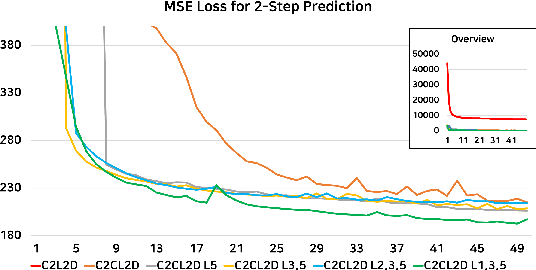
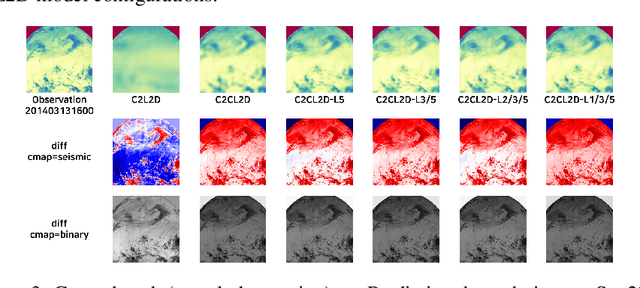
Predicting unseen weather phenomena is an important issue for disaster management. In this paper, we suggest a model for a convolutional sequence-to-sequence autoencoder for predicting undiscovered weather situations from previous satellite images. We also propose a symmetric skip connection between encoder and decoder modules to produce more comprehensive image predictions. To examine our model performance, we conducted experiments for each suggested model to predict future satellite images from historical satellite images. A specific combination of skip connection and sequence-to-sequence autoencoder was able to generate closest prediction from the ground truth image.
DeepRain: ConvLSTM Network for Precipitation Prediction using Multichannel Radar Data
Nov 07, 2017
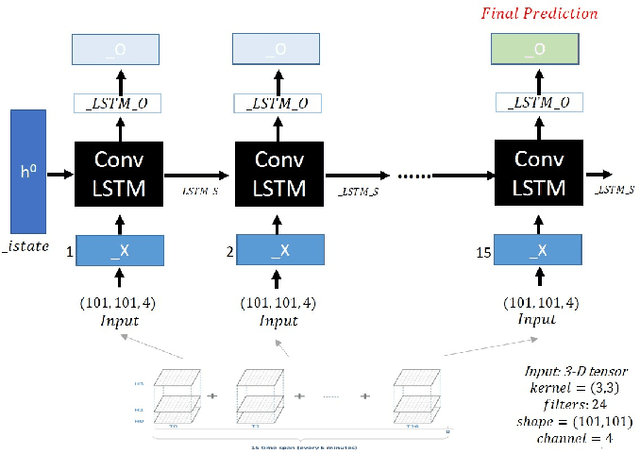


Accurate rainfall forecasting is critical because it has a great impact on people's social and economic activities. Recent trends on various literatures show that Deep Learning (Neural Network) is a promising methodology to tackle many challenging tasks. In this study, we introduce a brand-new data-driven precipitation prediction model called DeepRain. This model predicts the amount of rainfall from weather radar data, which is three-dimensional and four-channel data, using convolutional LSTM (ConvLSTM). ConvLSTM is a variant of LSTM (Long Short-Term Memory) containing a convolution operation inside the LSTM cell. For the experiment, we used radar reflectivity data for a two-year period whose input is in a time series format in units of 6 min divided into 15 records. The output is the predicted rainfall information for the input data. Experimental results show that two-stacked ConvLSTM reduced RMSE by 23.0% compared to linear regression.
GlobeNet: Convolutional Neural Networks for Typhoon Eye Tracking from Remote Sensing Imagery
Aug 11, 2017


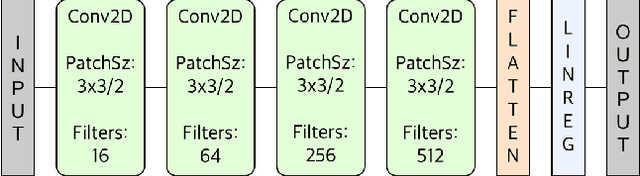
Advances in remote sensing technologies have made it possible to use high-resolution visual data for weather observation and forecasting tasks. We propose the use of multi-layer neural networks for understanding complex atmospheric dynamics based on multichannel satellite images. The capability of our model was evaluated by using a linear regression task for single typhoon coordinates prediction. A specific combination of models and different activation policies enabled us to obtain an interesting prediction result in the northeastern hemisphere (ENH).