 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRIT: Graph-Based Automatic Data Synthesis to Enhance Cross-Modal Multi-Hop Reasoning
Apr 02, 2026Real-world reasoning often requires combining information across modalities, connecting textual context with visual cues in a multi-hop process. Yet, most multimodal benchmarks fail to capture this ability: they typically rely on single images or set of images, where answers can be inferred from a single modality alone. This limitation is mirrored in the training data, where interleaved image-text content rarely enforces complementary, multi-hop reasoning. As a result, Vision-Language Models (VLMs) frequently hallucinate and produce reasoning traces poorly grounded in visual evidence. To address this gap, we introduce CRIT, a new dataset and benchmark built with a graph-based automatic pipeline for generating complex cross-modal reasoning tasks. CRIT consists of diverse domains ranging from natural images, videos, and text-rich sources, and includes a manually verified test set for reliable evaluation. Experiments on this benchmark reveal that even state-of-the-art models struggle on such reasoning tasks. Models trained on CRIT show significant gains in cross-modal multi-hop reasoning, including strong improvements on SPIQA and other standard multimodal benchmarks.
Direct Diffusion Score Preference Optimization via Stepwise Contrastive Policy-Pair Supervision
Dec 29, 2025Diffusion models have achieved impressive results in generative tasks such as text-to-image synthesis, yet they often struggle to fully align outputs with nuanced user intent and maintain consistent aesthetic quality. Existing preference-based training methods like Diffusion Direct Preference Optimization help address these issues but rely on costly and potentially noisy human-labeled datasets. In this work, we introduce Direct Diffusion Score Preference Optimization (DDSPO), which directly derives per-timestep supervision from winning and losing policies when such policies are available. Unlike prior methods that operate solely on final samples, DDSPO provides dense, transition-level signals across the denoising trajectory. In practice, we avoid reliance on labeled data by automatically generating preference signals using a pretrained reference model: we contrast its outputs when conditioned on original prompts versus semantically degraded variants. This practical strategy enables effective score-space preference supervision without explicit reward modeling or manual annotations. Empirical results demonstrate that DDSPO improves text-image alignment and visual quality, outperforming or matching existing preference-based methods while requiring significantly less supervision. Our implementation is available at: https://dohyun-as.github.io/DDSPO
DialNav: Multi-turn Dialog Navigation with a Remote Guide
Sep 16, 2025We introduce DialNav, a novel collaborative embodied dialog task, where a navigation agent (Navigator) and a remote guide (Guide) engage in multi-turn dialog to reach a goal location. Unlike prior work, DialNav aims for holistic evaluation and requires the Guide to infer the Navigator's location, making communication essential for task success. To support this task, we collect and release the Remote Assistance in Navigation (RAIN) dataset, human-human dialog paired with navigation trajectories in photorealistic environments. We design a comprehensive benchmark to evaluate both navigation and dialog, and conduct extensive experiments analyzing the impact of different Navigator and Guide models. We highlight key challenges and publicly release the dataset, code, and evaluation framework to foster future research in embodied dialog.
Bridging Audio and Vision: Zero-Shot Audiovisual Segmentation by Connecting Pretrained Models
Jun 06, 2025Audiovisual segmentation (AVS) aims to identify visual regions corresponding to sound sources, playing a vital role in video understanding, surveillance, and human-computer interaction. Traditional AVS methods depend on large-scale pixel-level annotations, which are costly and time-consuming to obtain. To address this, we propose a novel zero-shot AVS framework that eliminates task-specific training by leveraging multiple pretrained models. Our approach integrates audio, vision, and text representations to bridge modality gaps, enabling precise sound source segmentation without AVS-specific annotations. We systematically explore different strategies for connecting pretrained models and evaluate their efficacy across multiple datasets. Experimental results demonstrate that our framework achieves state-of-the-art zero-shot AVS performance, highlighting the effectiveness of multimodal model integration for finegrained audiovisual segmentation.
ReSCORE: Label-free Iterative Retriever Training for Multi-hop Question Answering with Relevance-Consistency Supervision
May 27, 2025Multi-hop question answering (MHQA) involves reasoning across multiple documents to answer complex questions. Dense retrievers typically outperform sparse methods like BM25 by leveraging semantic embeddings; however, they require labeled query-document pairs for fine-tuning. This poses a significant challenge in MHQA due to the high variability of queries (reformulated) questions throughout the reasoning steps. To overcome this limitation, we introduce Retriever Supervision with Consistency and Relevance (ReSCORE), a novel method for training dense retrievers for MHQA without labeled documents. ReSCORE leverages large language models to capture each documents relevance to the question and consistency with the correct answer and use them to train a retriever within an iterative question-answering framework. Experiments on three MHQA benchmarks demonstrate the effectiveness of ReSCORE, with significant improvements in retrieval, and in turn, the state-of-the-art MHQA performance. Our implementation is available at: https://leeds1219.github.io/ReSCORE.
Random Conditioning with Distillation for Data-Efficient Diffusion Model Compression
Apr 02, 2025Diffusion models generate high-quality images through progressive denoising but are computationally intensive due to large model sizes and repeated sampling. Knowledge distillation, which transfers knowledge from a complex teacher to a simpler student model, has been widely studied in recognition tasks, particularly for transferring concepts unseen during student training. However, its application to diffusion models remains underexplored, especially in enabling student models to generate concepts not covered by the training images. In this work, we propose Random Conditioning, a novel approach that pairs noised images with randomly selected text conditions to enable efficient, image-free knowledge distillation. By leveraging this technique, we show that the student can generate concepts unseen in the training images. When applied to conditional diffusion model distillation, our method allows the student to explore the condition space without generating condition-specific images, resulting in notable improvements in both generation quality and efficiency. This promotes resource-efficient deployment of generative diffusion models, broadening their accessibility for both research and real-world applications. Code, models, and datasets are available at https://dohyun-as.github.io/Random-Conditioning .
Spectral-Adaptive Modulation Networks for Visual Perception
Mar 31, 2025Recent studies have shown that 2D convolution and self-attention exhibit distinct spectral behaviors, and optimizing their spectral properties can enhance vision model performance. However, theoretical analyses remain limited in explaining why 2D convolution is more effective in high-pass filtering than self-attention and why larger kernels favor shape bias, akin to self-attention. In this paper, we employ graph spectral analysis to theoretically simulate and compare the frequency responses of 2D convolution and self-attention within a unified framework. Our results corroborate previous empirical findings and reveal that node connectivity, modulated by window size, is a key factor in shaping spectral functions. Leveraging this insight, we introduce a \textit{spectral-adaptive modulation} (SPAM) mixer, which processes visual features in a spectral-adaptive manner using multi-scale convolutional kernels and a spectral re-scaling mechanism to refine spectral components. Based on SPAM, we develop SPANetV2 as a novel vision backbone. Extensive experiments demonstrate that SPANetV2 outperforms state-of-the-art models across multiple vision tasks, including ImageNet-1K classification, COCO object detection, and ADE20K semantic segmentation.
LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
Feb 10, 2025



While large language models (LLMs) excel in generating coherent and contextually rich outputs, their capacity to efficiently handle long-form contexts is limited by fixed-length position embeddings. Additionally, the computational cost of processing long sequences increases quadratically, making it challenging to extend context length. To address these challenges, we propose Long-form Context Injection with Recurrent Compression (LCIRC), a method that enables the efficient processing long-form sequences beyond the model's length limit through recurrent compression without retraining the entire model. We further introduce query dependent context modeling, which selectively compresses query-relevant information, ensuring that the model retains the most pertinent content. Our empirical results demonstrate that Query Dependent LCIRC (QD-LCIRC) significantly improves LLM's ability to manage extended contexts, making it well-suited for tasks that require both comprehensive context understanding and query relevance.
Multi-Granularity Video Object Segmentation
Dec 03, 2024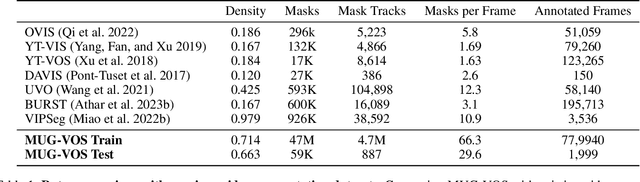
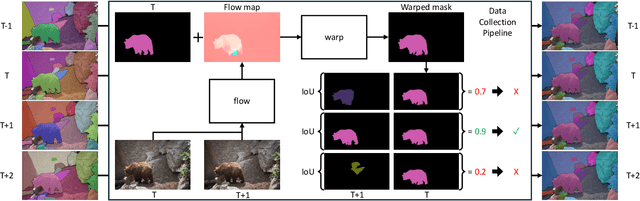


Current benchmarks for video segmentation are limited to annotating only salient objects (i.e., foreground instances). Despite their impressive architectural designs, previous works trained on these benchmarks have struggled to adapt to real-world scenarios. Thus, developing a new video segmentation dataset aimed at tracking multi-granularity segmentation target in the video scene is necessary. In this work, we aim to generate multi-granularity video segmentation dataset that is annotated for both salient and non-salient masks. To achieve this, we propose a large-scale, densely annotated multi-granularity video object segmentation (MUG-VOS) dataset that includes various types and granularities of mask annotations. We automatically collected a training set that assists in tracking both salient and non-salient objects, and we also curated a human-annotated test set for reliable evaluation. In addition, we present memory-based mask propagation model (MMPM), trained and evaluated on MUG-VOS dataset, which leads to the best performance among the existing video object segmentation methods and Segment SAM-based video segmentation methods. Project page is available at https://cvlab-kaist.github.io/MUG-VOS.
Towards Open-Vocabulary Semantic Segmentation Without Semantic Labels
Sep 30, 2024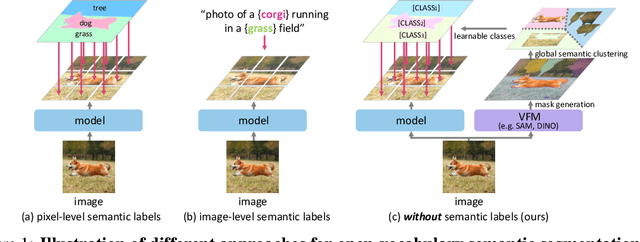
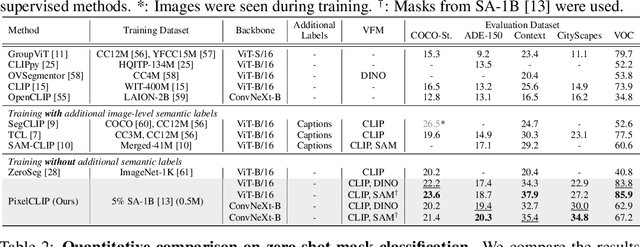

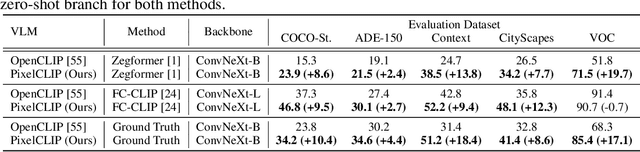
Large-scale vision-language models like CLIP have demonstrated impressive open-vocabulary capabilities for image-level tasks, excelling in recognizing what objects are present. However, they struggle with pixel-level recognition tasks like semantic segmentation, which additionally require understanding where the objects are located. In this work, we propose a novel method, PixelCLIP, to adapt the CLIP image encoder for pixel-level understanding by guiding the model on where, which is achieved using unlabeled images and masks generated from vision foundation models such as SAM and DINO. To address the challenges of leveraging masks without semantic labels, we devise an online clustering algorithm using learnable class names to acquire general semantic concepts. PixelCLIP shows significant performance improvements over CLIP and competitive results compared to caption-supervised methods in open-vocabulary semantic segmentation. Project page is available at https://cvlab-kaist.github.io/PixelCLIP