 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmanic: Towards Step-wise Evaluation of Multi-hop Reasoning in Large Language Models
Mar 17, 2026Reasoning-focused large language models (LLMs) have advanced in many NLP tasks, yet their evaluation remains challenging: final answers alone do not expose the intermediate reasoning steps, making it difficult to determine whether a model truly reasons correctly and where failures occur, while existing multi-hop QA benchmarks lack step-level annotations for diagnosing reasoning failures. To address this gap, we propose Omanic, an open-domain multi-hop QA resource that provides decomposed sub-questions and intermediate answers as structural annotations for analyzing reasoning processes. It contains 10,296 machine-generated training examples (OmanicSynth) and 967 expert-reviewed human-annotated evaluation examples (OmanicBench). Systematic evaluations show that state-of-the-art LLMs achieve only 73.11% multiple-choice accuracy on OmanicBench, confirming its high difficulty. Stepwise analysis reveals that CoT's performance hinges on factual completeness, with its gains diminishing under knowledge gaps and errors amplifying in later hops. Additionally, supervised fine-tuning on OmanicSynth brings substantial transfer gains (7.41 average points) across six reasoning and math benchmarks, validating the dataset's quality and further supporting the effectiveness of OmanicSynth as supervision for reasoning-capability transfer. We release the data at https://huggingface.co/datasets/li-lab/Omanic and the code at https://github.com/XiaojieGu/Omanic.
LANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal
Jan 08, 2026Dense retrieval in multilingual settings often searches over mixed-language collections, yet multilingual embeddings encode language identity alongside semantics. This language signal can inflate similarity for same-language pairs and crowd out relevant evidence written in other languages. We propose LANGSAE EDITING, a post-hoc sparse autoencoder trained on pooled embeddings that enables controllable removal of language-identity signal directly in vector space. The method identifies language-associated latent units using cross-language activation statistics, suppresses these units at inference time, and reconstructs embeddings in the original dimensionality, making it compatible with existing vector databases without retraining the base encoder or re-encoding raw text. Experiments across multiple languages show consistent improvements in ranking quality and cross-language coverage, with especially strong gains for script-distinct languages.
From Ambiguity to Accuracy: The Transformative Effect of Coreference Resolution on Retrieval-Augmented Generation systems
Jul 10, 2025Retrieval-Augmented Generation (RAG) has emerged as a crucial framework in natural language processing (NLP), improving factual consistency and reducing hallucinations by integrating external document retrieval with large language models (LLMs). However, the effectiveness of RAG is often hindered by coreferential complexity in retrieved documents, introducing ambiguity that disrupts in-context learning. In this study, we systematically investigate how entity coreference affects both document retrieval and generative performance in RAG-based systems, focusing on retrieval relevance, contextual understanding, and overall response quality. We demonstrate that coreference resolution enhances retrieval effectiveness and improves question-answering (QA) performance. Through comparative analysis of different pooling strategies in retrieval tasks, we find that mean pooling demonstrates superior context capturing ability after applying coreference resolution. In QA tasks, we discover that smaller models benefit more from the disambiguation process, likely due to their limited inherent capacity for handling referential ambiguity. With these findings, this study aims to provide a deeper understanding of the challenges posed by coreferential complexity in RAG, providing guidance for improving retrieval and generation in knowledge-intensive AI applications.
MIRAGE: A Metric-Intensive Benchmark for Retrieval-Augmented Generation Evaluation
Apr 23, 2025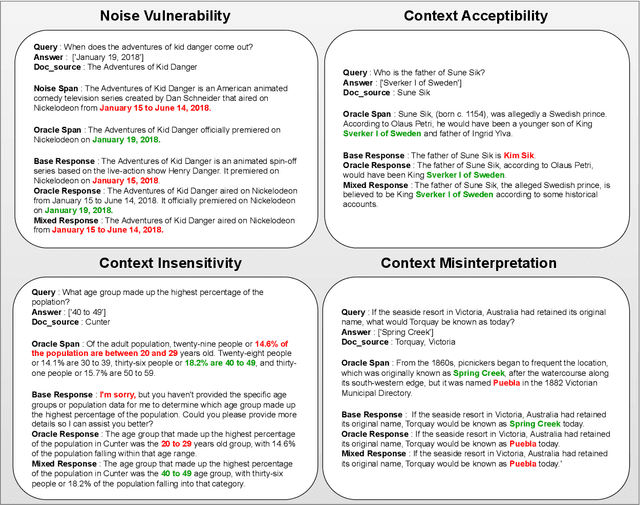
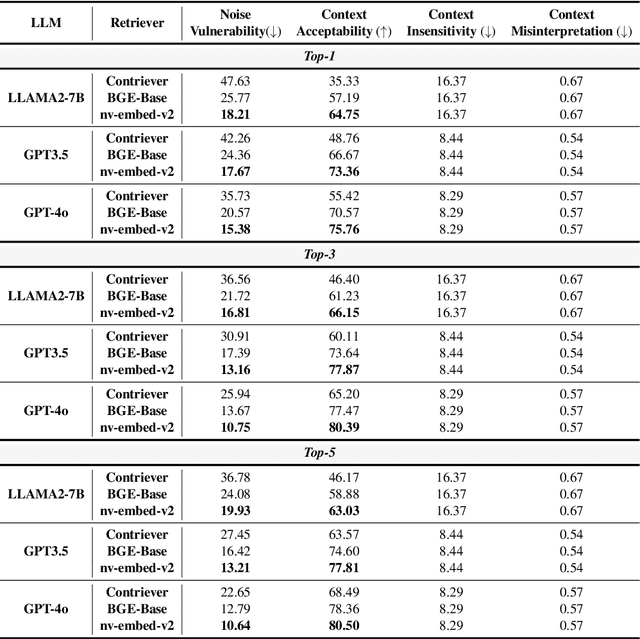
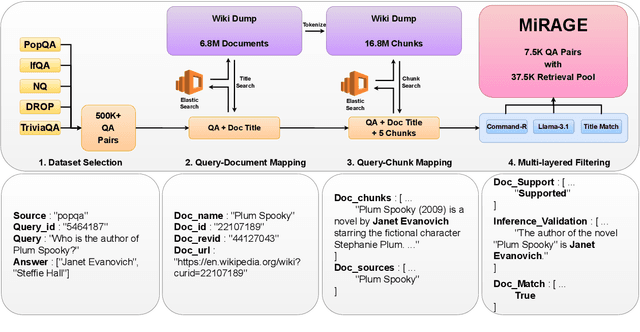
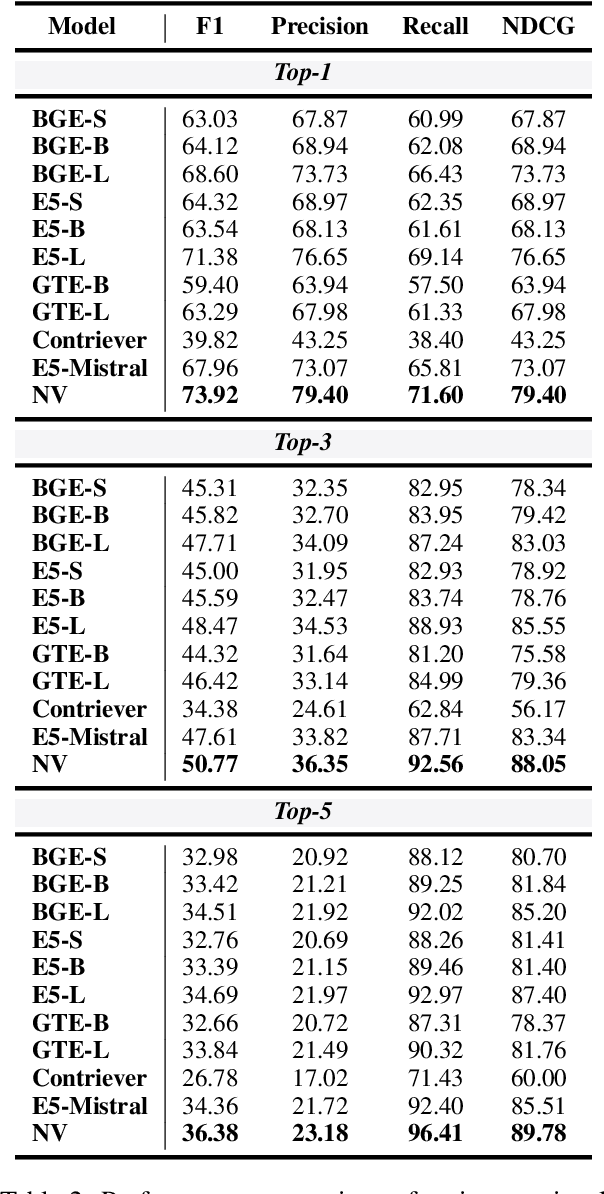
Retrieval-Augmented Generation (RAG) has gained prominence as an effective method for enhancing the generative capabilities of Large Language Models (LLMs) through the incorporation of external knowledge. However, the evaluation of RAG systems remains a challenge, due to the intricate interplay between retrieval and generation components. This limitation has resulted in a scarcity of benchmarks that facilitate a detailed, component-specific assessment. In this work, we present MIRAGE, a Question Answering dataset specifically designed for RAG evaluation. MIRAGE consists of 7,560 curated instances mapped to a retrieval pool of 37,800 entries, enabling an efficient and precise evaluation of both retrieval and generation tasks. We also introduce novel evaluation metrics aimed at measuring RAG adaptability, encompassing dimensions such as noise vulnerability, context acceptability, context insensitivity, and context misinterpretation. Through comprehensive experiments across various retriever-LLM configurations, we provide new insights into the optimal alignment of model pairs and the nuanced dynamics within RAG systems. The dataset and evaluation code are publicly available, allowing for seamless integration and customization in diverse research settings\footnote{The MIRAGE code and data are available at https://github.com/nlpai-lab/MIRAGE.
HealthGenie: Empowering Users with Healthy Dietary Guidance through Knowledge Graph and Large Language Models
Apr 20, 2025Seeking dietary guidance often requires navigating complex professional knowledge while accommodating individual health conditions. Knowledge Graphs (KGs) offer structured and interpretable nutritional information, whereas Large Language Models (LLMs) naturally facilitate conversational recommendation delivery. In this paper, we present HealthGenie, an interactive system that combines the strengths of LLMs and KGs to provide personalized dietary recommendations along with hierarchical information visualization for a quick and intuitive overview. Upon receiving a user query, HealthGenie performs query refinement and retrieves relevant information from a pre-built KG. The system then visualizes and highlights pertinent information, organized by defined categories, while offering detailed, explainable recommendation rationales. Users can further tailor these recommendations by adjusting preferences interactively. Our evaluation, comprising a within-subject comparative experiment and an open-ended discussion, demonstrates that HealthGenie effectively supports users in obtaining personalized dietary guidance based on their health conditions while reducing interaction effort and cognitive load. These findings highlight the potential of LLM-KG integration in supporting decision-making through explainable and visualized information. We examine the system's usefulness and effectiveness with an N=12 within-subject study and provide design considerations for future systems that integrate conversational LLM and KG.
Debate Only When Necessary: Adaptive Multiagent Collaboration for Efficient LLM Reasoning
Apr 07, 2025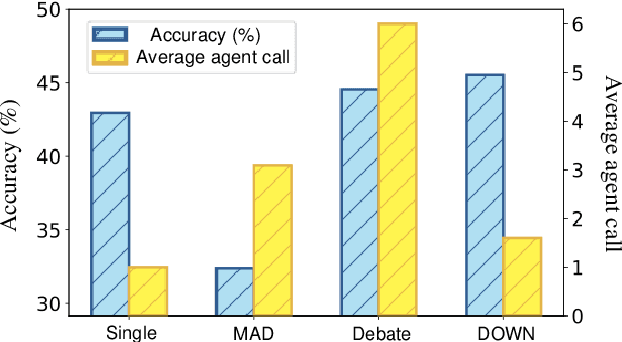
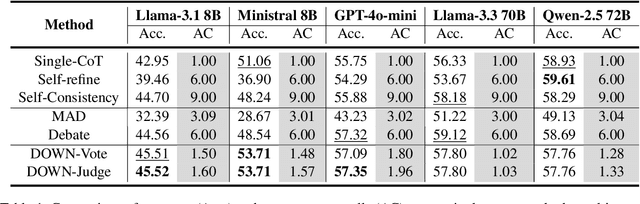
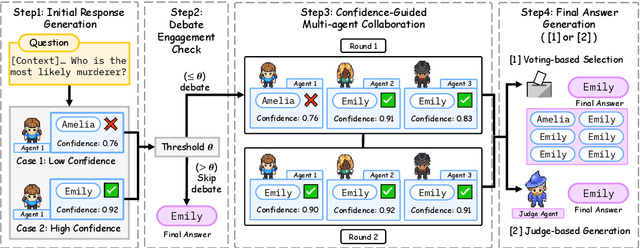
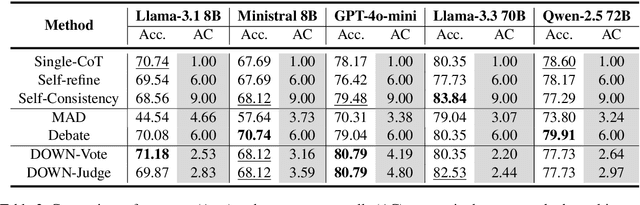
Multiagent collaboration has emerged as a promising framework for enhancing the reasoning capabilities of large language models (LLMs). While this approach improves reasoning capability, it incurs substantial computational overhead due to iterative agent interactions. Furthermore, engaging in debates for queries that do not necessitate collaboration amplifies the risk of error generation. To address these challenges, we propose Debate Only When Necessary (DOWN), an adaptive multiagent debate framework that selectively activates the debate process based on the confidence score of the agent's initial response. For queries where debate is triggered, agents refine their outputs using responses from participating agents and their confidence scores. Experimental results demonstrate that this mechanism significantly improves efficiency while maintaining or even surpassing the performance of existing multiagent debate systems. We also find that confidence-guided debate mitigates error propagation and enhances the selective incorporation of reliable responses. These results establish DOWN as an optimization strategy for efficient and effective multiagent reasoning, facilitating the practical deployment of LLM-based collaboration.
FLEX: A Benchmark for Evaluating Robustness of Fairness in Large Language Models
Mar 25, 2025



Recent advancements in Large Language Models (LLMs) have significantly enhanced interactions between users and models. These advancements concurrently underscore the need for rigorous safety evaluations due to the manifestation of social biases, which can lead to harmful societal impacts. Despite these concerns, existing benchmarks may overlook the intrinsic weaknesses of LLMs, which can generate biased responses even with simple adversarial instructions. To address this critical gap, we introduce a new benchmark, Fairness Benchmark in LLM under Extreme Scenarios (FLEX), designed to test whether LLMs can sustain fairness even when exposed to prompts constructed to induce bias. To thoroughly evaluate the robustness of LLMs, we integrate prompts that amplify potential biases into the fairness assessment. Comparative experiments between FLEX and existing benchmarks demonstrate that traditional evaluations may underestimate the inherent risks in models. This highlights the need for more stringent LLM evaluation benchmarks to guarantee safety and fairness.
Like Father, Like Son: Kinship-Aware Preference Mapping (KARMA) for Automatic Alignment in Large Language Models
Feb 26, 2025



Recent advancements in Large Language Model (LLM) alignment have sought to mitigate the cost of human annotations by leveraging pretrained models to generate preference data. However, existing methods often compare responses from models with substantially different capabilities, yielding superficial distinctions that fail to provide meaningful guidance on what constitutes a superior response. To address this limitation, we propose Kinship-Aware pReference MApping (KARMA), a novel framework that systematically pairs responses from models with comparable competencies. By constraining preference comparisons to outputs of similar complexity and quality, KARMA enhances the informativeness of preference data and improves the granularity of alignment signals. Empirical evaluations demonstrate that our kinship-aware approach leads to more consistent and interpretable alignment outcomes, ultimately facilitating a more principled and reliable pathway for aligning LLM behavior with human preferences.
CoME: An Unlearning-based Approach to Conflict-free Model Editing
Feb 20, 2025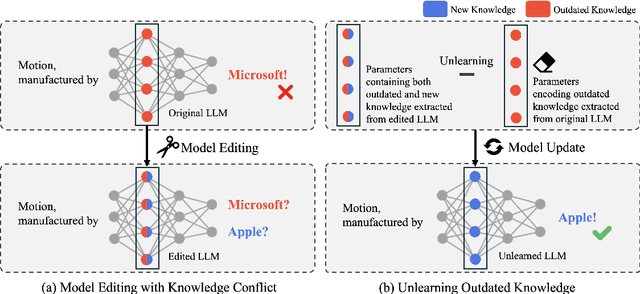


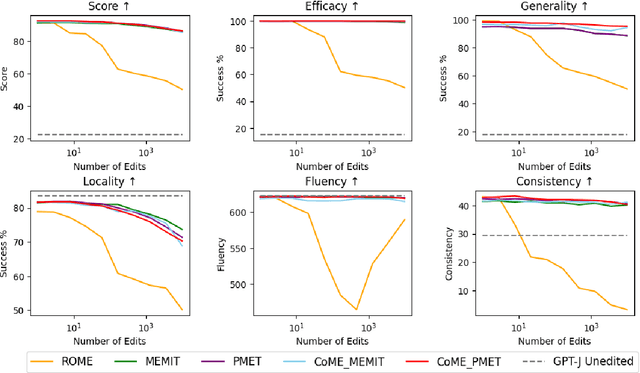
Large language models (LLMs) often retain outdated or incorrect information from pre-training, which undermines their reliability. While model editing methods have been developed to address such errors without full re-training, they frequently suffer from knowledge conflicts, where outdated information interferes with new knowledge. In this work, we propose Conflict-free Model Editing (CoME), a novel framework that enhances the accuracy of knowledge updates in LLMs by selectively removing outdated knowledge. CoME leverages unlearning to mitigate knowledge interference, allowing new information to be integrated without compromising relevant linguistic features. Through experiments on GPT-J and LLaMA-3 using Counterfact and ZsRE datasets, we demonstrate that CoME improves both editing accuracy and model reliability when applied to existing editing methods. Our results highlight that the targeted removal of outdated knowledge is crucial for enhancing model editing effectiveness and maintaining the model's generative performance.
LCIRC: A Recurrent Compression Approach for Efficient Long-form Context and Query Dependent Modeling in LLMs
Feb 10, 2025



While large language models (LLMs) excel in generating coherent and contextually rich outputs, their capacity to efficiently handle long-form contexts is limited by fixed-length position embeddings. Additionally, the computational cost of processing long sequences increases quadratically, making it challenging to extend context length. To address these challenges, we propose Long-form Context Injection with Recurrent Compression (LCIRC), a method that enables the efficient processing long-form sequences beyond the model's length limit through recurrent compression without retraining the entire model. We further introduce query dependent context modeling, which selectively compresses query-relevant information, ensuring that the model retains the most pertinent content. Our empirical results demonstrate that Query Dependent LCIRC (QD-LCIRC) significantly improves LLM's ability to manage extended contexts, making it well-suited for tasks that require both comprehensive context understanding and query relevance.