 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEX: A Benchmark for Evaluating Robustness of Fairness in Large Language Models
Mar 25, 2025



Recent advancements in Large Language Models (LLMs) have significantly enhanced interactions between users and models. These advancements concurrently underscore the need for rigorous safety evaluations due to the manifestation of social biases, which can lead to harmful societal impacts. Despite these concerns, existing benchmarks may overlook the intrinsic weaknesses of LLMs, which can generate biased responses even with simple adversarial instructions. To address this critical gap, we introduce a new benchmark, Fairness Benchmark in LLM under Extreme Scenarios (FLEX), designed to test whether LLMs can sustain fairness even when exposed to prompts constructed to induce bias. To thoroughly evaluate the robustness of LLMs, we integrate prompts that amplify potential biases into the fairness assessment. Comparative experiments between FLEX and existing benchmarks demonstrate that traditional evaluations may underestimate the inherent risks in models. This highlights the need for more stringent LLM evaluation benchmarks to guarantee safety and fairness.
CoME: An Unlearning-based Approach to Conflict-free Model Editing
Feb 20, 2025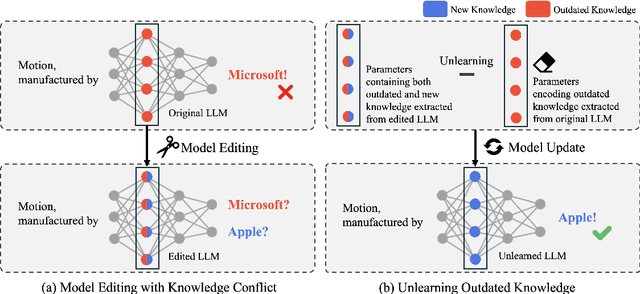


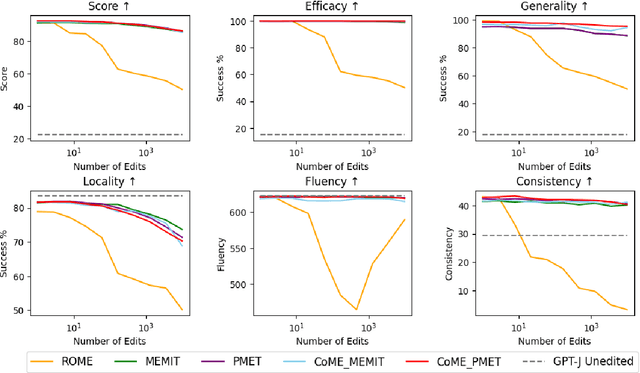
Large language models (LLMs) often retain outdated or incorrect information from pre-training, which undermines their reliability. While model editing methods have been developed to address such errors without full re-training, they frequently suffer from knowledge conflicts, where outdated information interferes with new knowledge. In this work, we propose Conflict-free Model Editing (CoME), a novel framework that enhances the accuracy of knowledge updates in LLMs by selectively removing outdated knowledge. CoME leverages unlearning to mitigate knowledge interference, allowing new information to be integrated without compromising relevant linguistic features. Through experiments on GPT-J and LLaMA-3 using Counterfact and ZsRE datasets, we demonstrate that CoME improves both editing accuracy and model reliability when applied to existing editing methods. Our results highlight that the targeted removal of outdated knowledge is crucial for enhancing model editing effectiveness and maintaining the model's generative performance.
Alternative Speech: Complementary Method to Counter-Narrative for Better Discourse
Jan 26, 2024We introduce the concept of "Alternative Speech" as a new way to directly combat hate speech and complement the limitations of counter-narrative. An alternative speech provides practical alternatives to hate speech in real-world scenarios by offering speech-level corrections to speakers while considering the surrounding context and promoting speakers to reform. Further, an alternative speech can combat hate speech alongside counter-narratives, offering a useful tool to address social issues such as racial discrimination and gender inequality. We propose the new concept and provide detailed guidelines for constructing the necessary dataset. Through discussion, we demonstrate that combining alternative speech and counter-narrative can be a more effective strategy for combating hate speech by complementing specificity and guiding capacity of counter-narrative. This paper presents another perspective for dealing with hate speech, offering viable remedies to complement the constraints of current approaches to mitigating harmful bias.
Knowledge Graph-Augmented Korean Generative Commonsense Reasoning
Jun 26, 2023

Generative commonsense reasoning refers to the task of generating acceptable and logical assumptions about everyday situations based on commonsense understanding. By utilizing an existing dataset such as Korean CommonGen, language generation models can learn commonsense reasoning specific to the Korean language. However, language models often fail to consider the relationships between concepts and the deep knowledge inherent to concepts. To address these limitations, we propose a method to utilize the Korean knowledge graph data for text generation. Our experimental result shows that the proposed method can enhance the efficiency of Korean commonsense inference, thereby underlining the significance of employing supplementary data.