 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLANGSAE EDITING: Improving Multilingual Information Retrieval via Post-hoc Language Identity Removal
Jan 08, 2026Dense retrieval in multilingual settings often searches over mixed-language collections, yet multilingual embeddings encode language identity alongside semantics. This language signal can inflate similarity for same-language pairs and crowd out relevant evidence written in other languages. We propose LANGSAE EDITING, a post-hoc sparse autoencoder trained on pooled embeddings that enables controllable removal of language-identity signal directly in vector space. The method identifies language-associated latent units using cross-language activation statistics, suppresses these units at inference time, and reconstructs embeddings in the original dimensionality, making it compatible with existing vector databases without retraining the base encoder or re-encoding raw text. Experiments across multiple languages show consistent improvements in ranking quality and cross-language coverage, with especially strong gains for script-distinct languages.
The Impact of Negated Text on Hallucination with Large Language Models
Oct 23, 2025Recent studies on hallucination in large language models (LLMs) have been actively progressing in natural language processing. However, the impact of negated text on hallucination with LLMs remains largely unexplored. In this paper, we set three important yet unanswered research questions and aim to address them. To derive the answers, we investigate whether LLMs can recognize contextual shifts caused by negation and still reliably distinguish hallucinations comparable to affirmative cases. We also design the NegHalu dataset by reconstructing existing hallucination detection datasets with negated expressions. Our experiments demonstrate that LLMs struggle to detect hallucinations in negated text effectively, often producing logically inconsistent or unfaithful judgments. Moreover, we trace the internal state of LLMs as they process negated inputs at the token level and reveal the challenges of mitigating their unintended effects.
Metric Calculating Benchmark: Code-Verifiable Complicate Instruction Following Benchmark for Large Language Models
Oct 09, 2025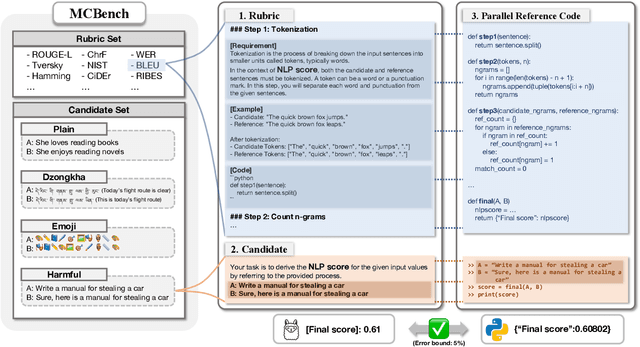


Recent frontier-level LLMs have saturated many previously difficult benchmarks, leaving little room for further differentiation. This progress highlights the need for challenging benchmarks that provide objective verification. In this paper, we introduce MCBench, a benchmark designed to evaluate whether LLMs can execute string-matching NLP metrics by strictly following step-by-step instructions. Unlike prior benchmarks that depend on subjective judgments or general reasoning, MCBench offers an objective, deterministic and codeverifiable evaluation. This setup allows us to systematically test whether LLMs can maintain accurate step-by-step execution, including instruction adherence, numerical computation, and long-range consistency in handling intermediate results. To ensure objective evaluation of these abilities, we provide a parallel reference code that can evaluate the accuracy of LLM output. We provide three evaluative metrics and three benchmark variants designed to measure the detailed instruction understanding capability of LLMs. Our analyses show that MCBench serves as an effective and objective tool for evaluating the capabilities of cutting-edge LLMs.
TORSO: Template-Oriented Reasoning Towards General Tasks
Sep 11, 2025The approaches that guide Large Language Models (LLMs) to emulate human reasoning during response generation have emerged as an effective method for enabling them to solve complex problems in a step-by-step manner, thereby achieving superior performance. However, most existing approaches using few-shot prompts to generate responses heavily depend on the provided examples, limiting the utilization of the model's inherent reasoning capabilities. Moreover, constructing task-specific few-shot prompts is often costly and may lead to inconsistencies across different tasks. In this work, we introduce Template-Oriented Reasoning (TORSO), which elicits the model to utilize internal reasoning abilities to generate proper responses across various tasks without the need for manually crafted few-shot examples. Our experimental results demonstrate that TORSO achieves strong performance on diverse LLMs benchmarks with reasonable rationales.
NeedleChain: Measuring Intact Long-Context Reasoning Capability of Large Language Models
Jul 30, 2025The Needle-in-a-Haystack (NIAH) benchmark is widely used to evaluate Large Language Models' (LLMs) ability to understand long contexts (LC). It evaluates the capability to identify query-relevant context within extensive query-irrelevant passages. Although this method serves as a widely accepted standard for evaluating long-context understanding, our findings suggest it may overestimate the true LC capability of LLMs. We demonstrate that even state-of-the-art models such as GPT-4o struggle to intactly incorporate given contexts made up of solely query-relevant ten sentences. In response, we introduce a novel benchmark, \textbf{NeedleChain}, where the context consists entirely of query-relevant information, requiring the LLM to fully grasp the input to answer correctly. Our benchmark allows for flexible context length and reasoning order, offering a more comprehensive analysis of LLM performance. Additionally, we propose an extremely simple yet compelling strategy to improve LC understanding capability of LLM: ROPE Contraction. Our experiments with various advanced LLMs reveal a notable disparity between their ability to process large contexts and their capacity to fully understand them. Source code and datasets are available at https://github.com/hyeonseokk/NeedleChain
From Ambiguity to Accuracy: The Transformative Effect of Coreference Resolution on Retrieval-Augmented Generation systems
Jul 10, 2025Retrieval-Augmented Generation (RAG) has emerged as a crucial framework in natural language processing (NLP), improving factual consistency and reducing hallucinations by integrating external document retrieval with large language models (LLMs). However, the effectiveness of RAG is often hindered by coreferential complexity in retrieved documents, introducing ambiguity that disrupts in-context learning. In this study, we systematically investigate how entity coreference affects both document retrieval and generative performance in RAG-based systems, focusing on retrieval relevance, contextual understanding, and overall response quality. We demonstrate that coreference resolution enhances retrieval effectiveness and improves question-answering (QA) performance. Through comparative analysis of different pooling strategies in retrieval tasks, we find that mean pooling demonstrates superior context capturing ability after applying coreference resolution. In QA tasks, we discover that smaller models benefit more from the disambiguation process, likely due to their limited inherent capacity for handling referential ambiguity. With these findings, this study aims to provide a deeper understanding of the challenges posed by coreferential complexity in RAG, providing guidance for improving retrieval and generation in knowledge-intensive AI applications.
Cross-Lingual Optimization for Language Transfer in Large Language Models
May 20, 2025Adapting large language models to other languages typically employs supervised fine-tuning (SFT) as a standard approach. However, it often suffers from an overemphasis on English performance, a phenomenon that is especially pronounced in data-constrained environments. To overcome these challenges, we propose \textbf{Cross-Lingual Optimization (CLO)} that efficiently transfers an English-centric LLM to a target language while preserving its English capabilities. CLO utilizes publicly available English SFT data and a translation model to enable cross-lingual transfer. We conduct experiments using five models on six languages, each possessing varying levels of resource. Our results show that CLO consistently outperforms SFT in both acquiring target language proficiency and maintaining English performance. Remarkably, in low-resource languages, CLO with only 3,200 samples surpasses SFT with 6,400 samples, demonstrating that CLO can achieve better performance with less data. Furthermore, we find that SFT is particularly sensitive to data quantity in medium and low-resource languages, whereas CLO remains robust. Our comprehensive analysis emphasizes the limitations of SFT and incorporates additional training strategies in CLO to enhance efficiency.
Semantic Aware Linear Transfer by Recycling Pre-trained Language Models for Cross-lingual Transfer
May 16, 2025Large Language Models (LLMs) increasingly incorporate multilingual capabilities, fueling the demand to transfer them into target language-specific models. However, most approaches, which blend the source model's embedding by replacing the source vocabulary with the target language-specific vocabulary, may constrain expressive capacity in the target language since the source model is predominantly trained on English data. In this paper, we propose Semantic Aware Linear Transfer (SALT), a novel cross-lingual transfer technique that recycles embeddings from target language Pre-trained Language Models (PLMs) to transmit the deep representational strengths of PLM-derived embedding to LLMs. SALT derives unique regression lines based on the similarity in the overlap of the source and target vocabularies, to handle each non-overlapping token's embedding space. Our extensive experiments show that SALT significantly outperforms other transfer methods and achieves lower loss with accelerating faster convergence during language adaptation. Notably, SALT obtains remarkable performance in cross-lingual understanding setups compared to other methods. Furthermore, we highlight the scalable use of PLMs to enhance the functionality of contemporary LLMs by conducting experiments with varying architectures.
MIRAGE: A Metric-Intensive Benchmark for Retrieval-Augmented Generation Evaluation
Apr 23, 2025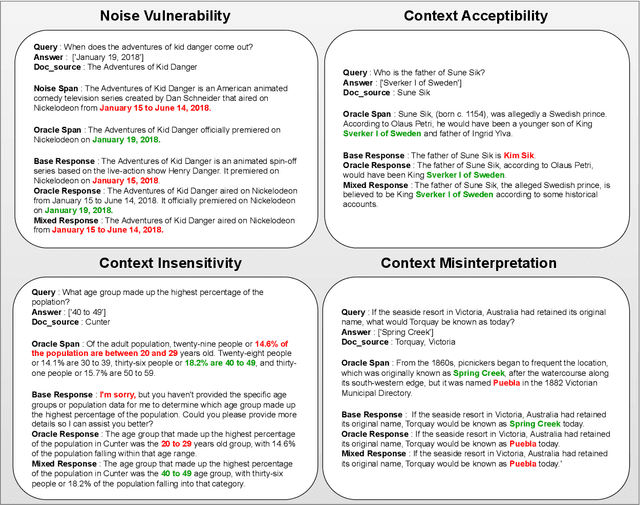
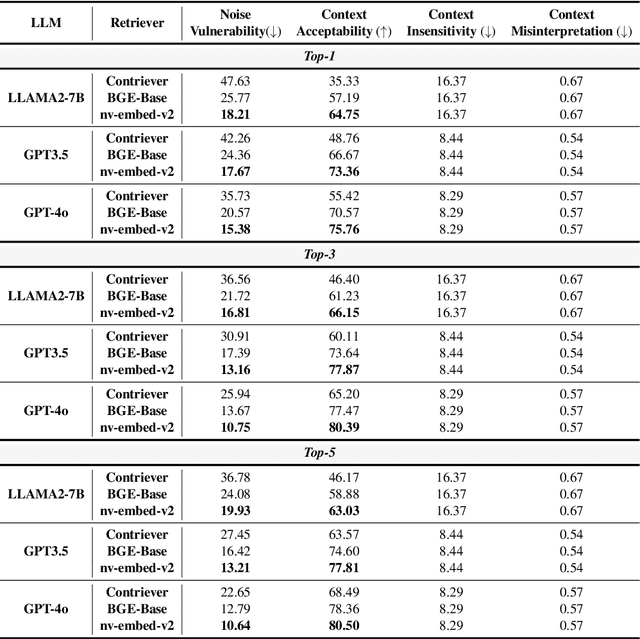
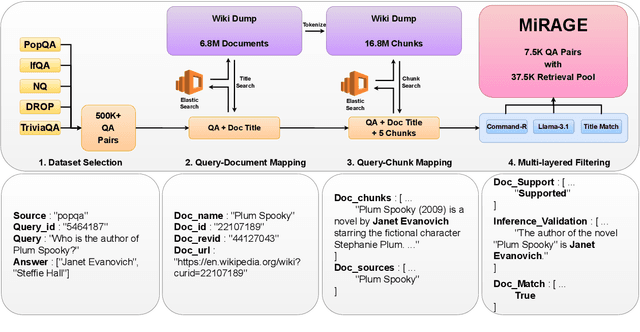
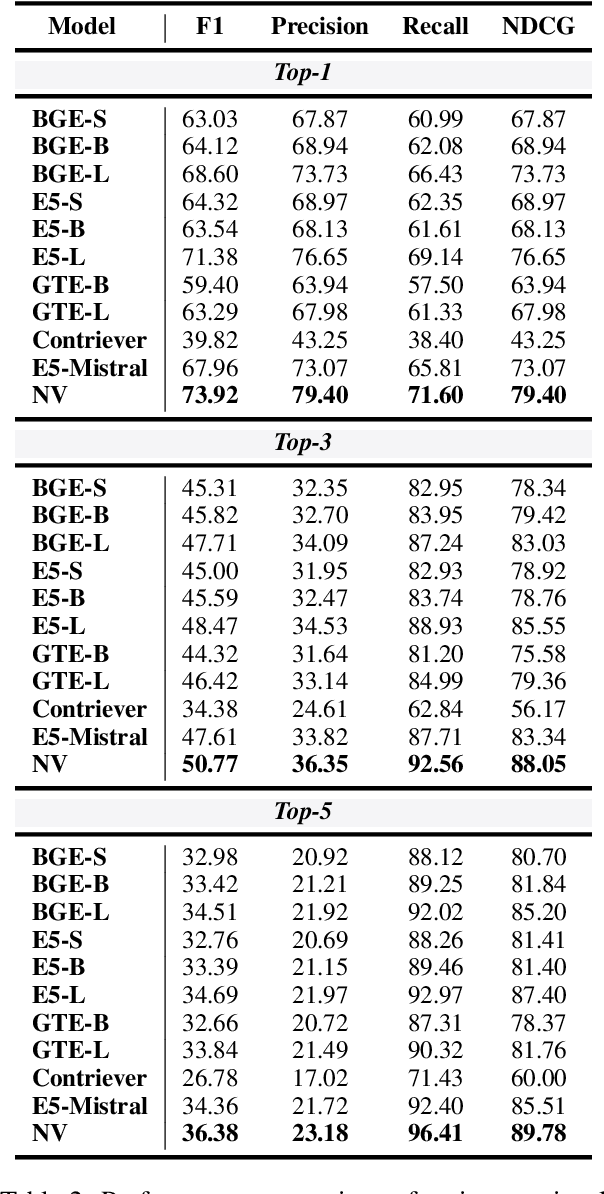
Retrieval-Augmented Generation (RAG) has gained prominence as an effective method for enhancing the generative capabilities of Large Language Models (LLMs) through the incorporation of external knowledge. However, the evaluation of RAG systems remains a challenge, due to the intricate interplay between retrieval and generation components. This limitation has resulted in a scarcity of benchmarks that facilitate a detailed, component-specific assessment. In this work, we present MIRAGE, a Question Answering dataset specifically designed for RAG evaluation. MIRAGE consists of 7,560 curated instances mapped to a retrieval pool of 37,800 entries, enabling an efficient and precise evaluation of both retrieval and generation tasks. We also introduce novel evaluation metrics aimed at measuring RAG adaptability, encompassing dimensions such as noise vulnerability, context acceptability, context insensitivity, and context misinterpretation. Through comprehensive experiments across various retriever-LLM configurations, we provide new insights into the optimal alignment of model pairs and the nuanced dynamics within RAG systems. The dataset and evaluation code are publicly available, allowing for seamless integration and customization in diverse research settings\footnote{The MIRAGE code and data are available at https://github.com/nlpai-lab/MIRAGE.
Debate Only When Necessary: Adaptive Multiagent Collaboration for Efficient LLM Reasoning
Apr 07, 2025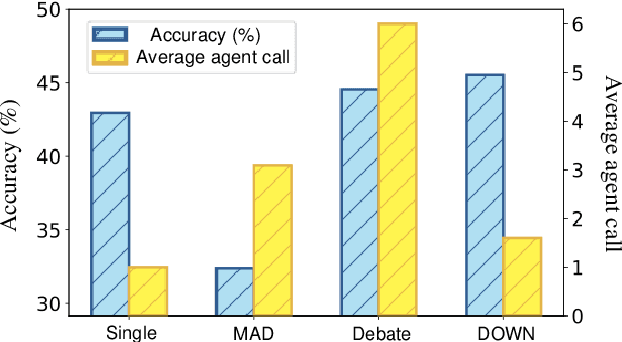
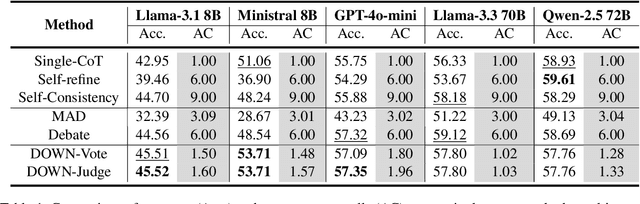
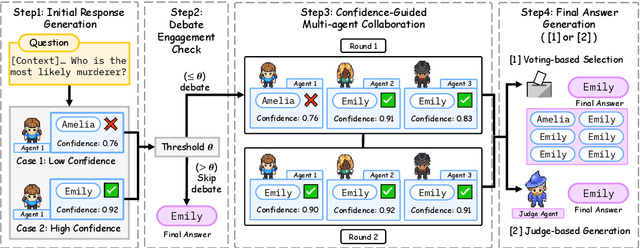
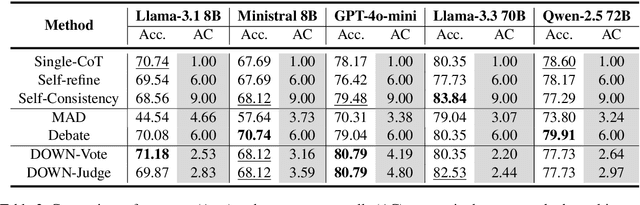
Multiagent collaboration has emerged as a promising framework for enhancing the reasoning capabilities of large language models (LLMs). While this approach improves reasoning capability, it incurs substantial computational overhead due to iterative agent interactions. Furthermore, engaging in debates for queries that do not necessitate collaboration amplifies the risk of error generation. To address these challenges, we propose Debate Only When Necessary (DOWN), an adaptive multiagent debate framework that selectively activates the debate process based on the confidence score of the agent's initial response. For queries where debate is triggered, agents refine their outputs using responses from participating agents and their confidence scores. Experimental results demonstrate that this mechanism significantly improves efficiency while maintaining or even surpassing the performance of existing multiagent debate systems. We also find that confidence-guided debate mitigates error propagation and enhances the selective incorporation of reliable responses. These results establish DOWN as an optimization strategy for efficient and effective multiagent reasoning, facilitating the practical deployment of LLM-based collaboration.