 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReFinE: Streamlining UI Mockup Iteration with Research Findings
Apr 06, 2026Although HCI research papers offer valuable design insights, designers often struggle to apply them in design workflows due to difficulties in finding relevant literature, understanding technical jargon, the lack of contextualization, and limited actionability. To address these challenges, we present ReFinE, a Figma plugin that supports real-time design iteration by surfacing contextualized insights from research papers. ReFinE identifies and synthesizes design implications from HCI literature relevant to the mockup's design context, and tailors this research evidence to a specific design mockup by providing actionable visual guidance on how to update the mockup. To assess the system's effectiveness, we conducted a technical evaluation and a user study. Results show that ReFinE effectively synthesizes and contextualizes design implications, reducing cognitive load and improving designers' ability to integrate research evidence into UI mockups. This work contributes to bridging the gap between research and design practice by presenting a tool for embedding scholarly insights into the UI design process.
Interrogating Design Homogenization in Web Vibe Coding
Mar 13, 2026Generative AI is known for its tendency to homogenize, often reproducing dominant style conventions found in training data. However, it remains unclear how these homogenizing effects extend to complex structural tasks like web design. As lay creators increasingly turn to LLMs to 'vibe-code' websites -- prompting for aesthetic and functional goals rather than writing code -- they may inadvertently narrow the diversity of their designs, and limit creative expression throughout the internet. In this paper, we interrogate the possibility of design homogenization in web vibe coding. We first characterize the vibe coding lifecycle, pinpointing stages where homogenization risks may arise. We then conduct a sociotechnical risk analysis unpacking the potential harms of web vibe coding and their interaction with design homogenization. We identify that the push for frictionless generation can exacerbate homogenization and its harms. Finally, we propose a mitigation framework centered on the idea of productive friction. Through case studies at the micro, meso, and macro levels, we show how centering productive friction can empower creators to challenge default outputs and preserve diverse expression in AI-mediated web design.
Letting Tutor Personas "Speak Up" for LLMs: Learning Steering Vectors from Dialogue via Preference Optimization
Feb 07, 2026With the emergence of large language models (LLMs) as a powerful class of generative artificial intelligence (AI), their use in tutoring has become increasingly prominent. Prior works on LLM-based tutoring typically learn a single tutor policy and do not capture the diversity of tutoring styles. In real-world tutor-student interactions, pedagogical intent is realized through adaptive instructional strategies, with tutors varying the level of scaffolding, instructional directiveness, feedback, and affective support in response to learners' needs. These differences can all impact dialogue dynamics and student engagement. In this paper, we explore how tutor personas embedded in human tutor-student dialogues can be used to guide LLM behavior without relying on explicitly prompted instructions. We modify Bidirectional Preference Optimization (BiPO) to learn a steering vector, an activation-space direction that steers model responses towards certain tutor personas. We find that this steering vector captures tutor-specific variation across dialogue contexts, improving semantic alignment with ground-truth tutor utterances and increasing preference-based evaluations, while largely preserving lexical similarity. Analysis of the learned directional coefficients further reveals interpretable structure across tutors, corresponding to consistent differences in tutoring behavior. These results demonstrate that activation steering offers an effective and interpretable way for controlling tutor-specific variation in LLMs using signals derived directly from human dialogue data.
Simulated Students in Tutoring Dialogues: Substance or Illusion?
Jan 07, 2026Advances in large language models (LLMs) enable many new innovations in education. However, evaluating the effectiveness of new technology requires real students, which is time-consuming and hard to scale up. Therefore, many recent works on LLM-powered tutoring solutions have used simulated students for both training and evaluation, often via simple prompting. Surprisingly, little work has been done to ensure or even measure the quality of simulated students. In this work, we formally define the student simulation task, propose a set of evaluation metrics that span linguistic, behavioral, and cognitive aspects, and benchmark a wide range of student simulation methods on these metrics. We experiment on a real-world math tutoring dialogue dataset, where both automated and human evaluation results show that prompting strategies for student simulation perform poorly; supervised fine-tuning and preference optimization yield much better but still limited performance, motivating future work on this challenging task.
Comparison of Optimised Geometric Deep Learning Architectures, over Varying Toxicological Assay Data Environments
Jul 22, 2025Geometric deep learning is an emerging technique in Artificial Intelligence (AI) driven cheminformatics, however the unique implications of different Graph Neural Network (GNN) architectures are poorly explored, for this space. This study compared performances of Graph Convolutional Networks (GCNs), Graph Attention Networks (GATs) and Graph Isomorphism Networks (GINs), applied to 7 different toxicological assay datasets of varying data abundance and endpoint, to perform binary classification of assay activation. Following pre-processing of molecular graphs, enforcement of class-balance and stratification of all datasets across 5 folds, Bayesian optimisations were carried out, for each GNN applied to each assay dataset (resulting in 21 unique Bayesian optimisations). Optimised GNNs performed at Area Under the Curve (AUC) scores ranging from 0.728-0.849 (averaged across all folds), naturally varying between specific assays and GNNs. GINs were found to consistently outperform GCNs and GATs, for the top 5 of 7 most data-abundant toxicological assays. GATs however significantly outperformed over the remaining 2 most data-scarce assays. This indicates that GINs are a more optimal architecture for data-abundant environments, whereas GATs are a more optimal architecture for data-scarce environments. Subsequent analysis of the explored higher-dimensional hyperparameter spaces, as well as optimised hyperparameter states, found that GCNs and GATs reached measurably closer optimised states with each other, compared to GINs, further indicating the unique nature of GINs as a GNN algorithm.
Fine-Tuning and Prompt Engineering of LLMs, for the Creation of Multi-Agent AI for Addressing Sustainable Protein Production Challenges
Jun 25, 2025



The global demand for sustainable protein sources has accelerated the need for intelligent tools that can rapidly process and synthesise domain-specific scientific knowledge. In this study, we present a proof-of-concept multi-agent Artificial Intelligence (AI) framework designed to support sustainable protein production research, with an initial focus on microbial protein sources. Our Retrieval-Augmented Generation (RAG)-oriented system consists of two GPT-based LLM agents: (1) a literature search agent that retrieves relevant scientific literature on microbial protein production for a specified microbial strain, and (2) an information extraction agent that processes the retrieved content to extract relevant biological and chemical information. Two parallel methodologies, fine-tuning and prompt engineering, were explored for agent optimisation. Both methods demonstrated effectiveness at improving the performance of the information extraction agent in terms of transformer-based cosine similarity scores between obtained and ideal outputs. Mean cosine similarity scores were increased by up to 25%, while universally reaching mean scores of $\geq 0.89$ against ideal output text. Fine-tuning overall improved the mean scores to a greater extent (consistently of $\geq 0.94$) compared to prompt engineering, although lower statistical uncertainties were observed with the latter approach. A user interface was developed and published for enabling the use of the multi-agent AI system, alongside preliminary exploration of additional chemical safety-based search capabilities
Safeguarding Privacy of Retrieval Data against Membership Inference Attacks: Is This Query Too Close to Home?
May 28, 2025



Retrieval-augmented generation (RAG) mitigates the hallucination problem in large language models (LLMs) and has proven effective for specific, personalized applications. However, passing private retrieved documents directly to LLMs introduces vulnerability to membership inference attacks (MIAs), which try to determine whether the target datum exists in the private external database or not. Based on the insight that MIA queries typically exhibit high similarity to only one target document, we introduce Mirabel, a similarity-based MIA detection framework designed for the RAG system. With the proposed Mirabel, we show that simple detect-and-hide strategies can successfully obfuscate attackers, maintain data utility, and remain system-agnostic. We experimentally prove its detection and defense against various state-of-the-art MIA methods and its adaptability to existing private RAG systems.
From Text to Visuals: Using LLMs to Generate Math Diagrams with Vector Graphics
Mar 10, 2025

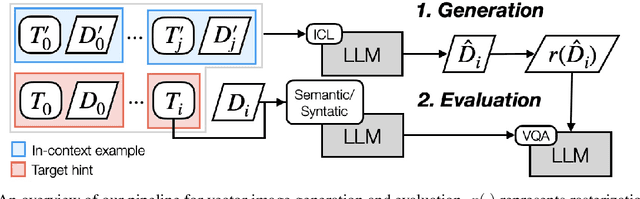

Advances in large language models (LLMs) offer new possibilities for enhancing math education by automating support for both teachers and students. While prior work has focused on generating math problems and high-quality distractors, the role of visualization in math learning remains under-explored. Diagrams are essential for mathematical thinking and problem-solving, yet manually creating them is time-consuming and requires domain-specific expertise, limiting scalability. Recent research on using LLMs to generate Scalable Vector Graphics (SVG) presents a promising approach to automating diagram creation. Unlike pixel-based images, SVGs represent geometric figures using XML, allowing seamless scaling and adaptability. Educational platforms such as Khan Academy and IXL already use SVGs to display math problems and hints. In this paper, we explore the use of LLMs to generate math-related diagrams that accompany textual hints via intermediate SVG representations. We address three research questions: (1) how to automatically generate math diagrams in problem-solving hints and evaluate their quality, (2) whether SVG is an effective intermediate representation for math diagrams, and (3) what prompting strategies and formats are required for LLMs to generate accurate SVG-based diagrams. Our contributions include defining the task of automatically generating SVG-based diagrams for math hints, developing an LLM prompting-based pipeline, and identifying key strategies for improving diagram generation. Additionally, we introduce a Visual Question Answering-based evaluation setup and conduct ablation studies to assess different pipeline variations. By automating the math diagram creation, we aim to provide students and teachers with accurate, conceptually relevant visual aids that enhance problem-solving and learning experiences.
Training LLM-based Tutors to Improve Student Learning Outcomes in Dialogues
Mar 09, 2025



Generative artificial intelligence (AI) has the potential to scale up personalized tutoring through large language models (LLMs). Recent AI tutors are adapted for the tutoring task by training or prompting LLMs to follow effective pedagogical principles, though they are not trained to maximize student learning throughout the course of a dialogue. Therefore, they may engage with students in a suboptimal way. We address this limitation by introducing an approach to train LLMs to generate tutor utterances that maximize the likelihood of student correctness, while still encouraging the model to follow good pedagogical practice. Specifically, we generate a set of candidate tutor utterances and score them using (1) an LLM-based student model to predict the chance of correct student responses and (2) a pedagogical rubric evaluated by GPT-4o. We then use the resulting data to train an open-source LLM, Llama 3.1 8B, using direct preference optimization. We show that tutor utterances generated by our model lead to significantly higher chances of correct student responses while maintaining the pedagogical quality of GPT-4o. We also conduct qualitative analyses and a human evaluation to demonstrate that our model generates high quality tutor utterances.
CoME: An Unlearning-based Approach to Conflict-free Model Editing
Feb 20, 2025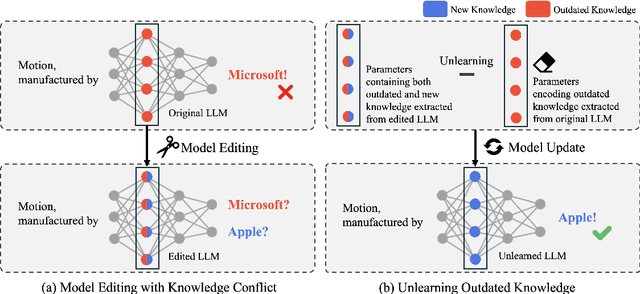


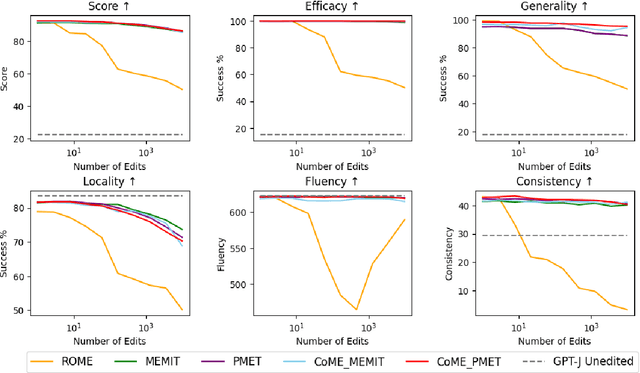
Large language models (LLMs) often retain outdated or incorrect information from pre-training, which undermines their reliability. While model editing methods have been developed to address such errors without full re-training, they frequently suffer from knowledge conflicts, where outdated information interferes with new knowledge. In this work, we propose Conflict-free Model Editing (CoME), a novel framework that enhances the accuracy of knowledge updates in LLMs by selectively removing outdated knowledge. CoME leverages unlearning to mitigate knowledge interference, allowing new information to be integrated without compromising relevant linguistic features. Through experiments on GPT-J and LLaMA-3 using Counterfact and ZsRE datasets, we demonstrate that CoME improves both editing accuracy and model reliability when applied to existing editing methods. Our results highlight that the targeted removal of outdated knowledge is crucial for enhancing model editing effectiveness and maintaining the model's generative performance.