 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLetting Tutor Personas "Speak Up" for LLMs: Learning Steering Vectors from Dialogue via Preference Optimization
Feb 07, 2026With the emergence of large language models (LLMs) as a powerful class of generative artificial intelligence (AI), their use in tutoring has become increasingly prominent. Prior works on LLM-based tutoring typically learn a single tutor policy and do not capture the diversity of tutoring styles. In real-world tutor-student interactions, pedagogical intent is realized through adaptive instructional strategies, with tutors varying the level of scaffolding, instructional directiveness, feedback, and affective support in response to learners' needs. These differences can all impact dialogue dynamics and student engagement. In this paper, we explore how tutor personas embedded in human tutor-student dialogues can be used to guide LLM behavior without relying on explicitly prompted instructions. We modify Bidirectional Preference Optimization (BiPO) to learn a steering vector, an activation-space direction that steers model responses towards certain tutor personas. We find that this steering vector captures tutor-specific variation across dialogue contexts, improving semantic alignment with ground-truth tutor utterances and increasing preference-based evaluations, while largely preserving lexical similarity. Analysis of the learned directional coefficients further reveals interpretable structure across tutors, corresponding to consistent differences in tutoring behavior. These results demonstrate that activation steering offers an effective and interpretable way for controlling tutor-specific variation in LLMs using signals derived directly from human dialogue data.
Simulated Students in Tutoring Dialogues: Substance or Illusion?
Jan 07, 2026Advances in large language models (LLMs) enable many new innovations in education. However, evaluating the effectiveness of new technology requires real students, which is time-consuming and hard to scale up. Therefore, many recent works on LLM-powered tutoring solutions have used simulated students for both training and evaluation, often via simple prompting. Surprisingly, little work has been done to ensure or even measure the quality of simulated students. In this work, we formally define the student simulation task, propose a set of evaluation metrics that span linguistic, behavioral, and cognitive aspects, and benchmark a wide range of student simulation methods on these metrics. We experiment on a real-world math tutoring dialogue dataset, where both automated and human evaluation results show that prompting strategies for student simulation perform poorly; supervised fine-tuning and preference optimization yield much better but still limited performance, motivating future work on this challenging task.
Exploring LLMs for Predicting Tutor Strategy and Student Outcomes in Dialogues
Jul 09, 2025Tutoring dialogues have gained significant attention in recent years, given the prominence of online learning and the emerging tutoring abilities of artificial intelligence (AI) agents powered by large language models (LLMs). Recent studies have shown that the strategies used by tutors can have significant effects on student outcomes, necessitating methods to predict how tutors will behave and how their actions impact students. However, few works have studied predicting tutor strategy in dialogues. Therefore, in this work we investigate the ability of modern LLMs, particularly Llama 3 and GPT-4o, to predict both future tutor moves and student outcomes in dialogues, using two math tutoring dialogue datasets. We find that even state-of-the-art LLMs struggle to predict future tutor strategy while tutor strategy is highly indicative of student outcomes, outlining a need for more powerful methods to approach this task.
Adaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
LookAlike: Consistent Distractor Generation in Math MCQs
May 03, 2025



Large language models (LLMs) are increasingly used to generate distractors for multiple-choice questions (MCQs), especially in domains like math education. However, existing approaches are limited in ensuring that the generated distractors are consistent with common student errors. We propose LookAlike, a method that improves error-distractor consistency via preference optimization. Our two main innovations are: (a) mining synthetic preference pairs from model inconsistencies, and (b) alternating supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to stabilize training. Unlike prior work that relies on heuristics or manually annotated preference data, LookAlike uses its own generation inconsistencies as dispreferred samples, thus enabling scalable and stable training. Evaluated on a real-world dataset of 1,400+ math MCQs, LookAlike achieves 51.6% accuracy in distractor generation and 57.2% in error generation under LLM-as-a-judge evaluation, outperforming an existing state-of-the-art method (45.6% / 47.7%). These improvements highlight the effectiveness of preference-based regularization and inconsistency mining for generating consistent math MCQ distractors at scale.
Training LLM-based Tutors to Improve Student Learning Outcomes in Dialogues
Mar 09, 2025



Generative artificial intelligence (AI) has the potential to scale up personalized tutoring through large language models (LLMs). Recent AI tutors are adapted for the tutoring task by training or prompting LLMs to follow effective pedagogical principles, though they are not trained to maximize student learning throughout the course of a dialogue. Therefore, they may engage with students in a suboptimal way. We address this limitation by introducing an approach to train LLMs to generate tutor utterances that maximize the likelihood of student correctness, while still encouraging the model to follow good pedagogical practice. Specifically, we generate a set of candidate tutor utterances and score them using (1) an LLM-based student model to predict the chance of correct student responses and (2) a pedagogical rubric evaluated by GPT-4o. We then use the resulting data to train an open-source LLM, Llama 3.1 8B, using direct preference optimization. We show that tutor utterances generated by our model lead to significantly higher chances of correct student responses while maintaining the pedagogical quality of GPT-4o. We also conduct qualitative analyses and a human evaluation to demonstrate that our model generates high quality tutor utterances.
ReaLJam: Real-Time Human-AI Music Jamming with Reinforcement Learning-Tuned Transformers
Feb 28, 2025Recent advances in generative artificial intelligence (AI) have created models capable of high-quality musical content generation. However, little consideration is given to how to use these models for real-time or cooperative jamming musical applications because of crucial required features: low latency, the ability to communicate planned actions, and the ability to adapt to user input in real-time. To support these needs, we introduce ReaLJam, an interface and protocol for live musical jamming sessions between a human and a Transformer-based AI agent trained with reinforcement learning. We enable real-time interactions using the concept of anticipation, where the agent continually predicts how the performance will unfold and visually conveys its plan to the user. We conduct a user study where experienced musicians jam in real-time with the agent through ReaLJam. Our results demonstrate that ReaLJam enables enjoyable and musically interesting sessions, and we uncover important takeaways for future work.
Evaluating GPT-4 at Grading Handwritten Solutions in Math Exams
Nov 07, 2024

Recent advances in generative artificial intelligence (AI) have shown promise in accurately grading open-ended student responses. However, few prior works have explored grading handwritten responses due to a lack of data and the challenge of combining visual and textual information. In this work, we leverage state-of-the-art multi-modal AI models, in particular GPT-4o, to automatically grade handwritten responses to college-level math exams. Using real student responses to questions in a probability theory exam, we evaluate GPT-4o's alignment with ground-truth scores from human graders using various prompting techniques. We find that while providing rubrics improves alignment, the model's overall accuracy is still too low for real-world settings, showing there is significant room for growth in this task.
Exploring Knowledge Tracing in Tutor-Student Dialogues
Sep 24, 2024


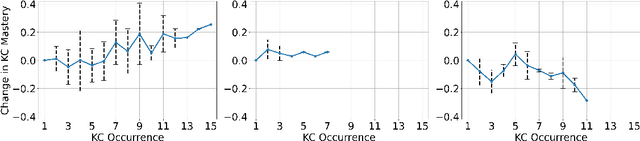
Recent advances in large language models (LLMs) have led to the development of artificial intelligence (AI)-powered tutoring chatbots, showing promise in providing broad access to high-quality personalized education. Existing works have primarily studied how to make LLMs follow tutoring principles but not how to model student behavior in dialogues. However, analyzing student dialogue turns can serve as a formative assessment, since open-ended student discourse may indicate their knowledge levels and reveal specific misconceptions. In this work, we present a first attempt at performing knowledge tracing (KT) in tutor-student dialogues. We propose LLM prompting methods to identify the knowledge components/skills involved in each dialogue turn and diagnose whether the student responds correctly to the tutor, and verify the LLM's effectiveness via an expert human evaluation. We then apply a range of KT methods on the resulting labeled data to track student knowledge levels over an entire dialogue. We conduct experiments on two tutoring dialogue datasets, and show that a novel yet simple LLM-based method, LLMKT, significantly outperforms existing KT methods in predicting student response correctness in dialogues. We perform extensive qualitative analyses to highlight the challenges in dialogue KT and outline multiple avenues for future work.
DiVERT: Distractor Generation with Variational Errors Represented as Text for Math Multiple-choice Questions
Jun 27, 2024



High-quality distractors are crucial to both the assessment and pedagogical value of multiple-choice questions (MCQs), where manually crafting ones that anticipate knowledge deficiencies or misconceptions among real students is difficult. Meanwhile, automated distractor generation, even with the help of large language models (LLMs), remains challenging for subjects like math. It is crucial to not only identify plausible distractors but also understand the error behind them. In this paper, we introduce DiVERT (Distractor Generation with Variational Errors Represented as Text), a novel variational approach that learns an interpretable representation of errors behind distractors in math MCQs. Through experiments on a real-world math MCQ dataset with 1,434 questions used by hundreds of thousands of students, we show that DiVERT, despite using a base open-source LLM with 7B parameters, outperforms state-of-the-art approaches using GPT-4o on downstream distractor generation. We also conduct a human evaluation with math educators and find that DiVERT leads to error labels that are of comparable quality to human-authored ones.