 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
FLAM: Frame-Wise Language-Audio Modeling
May 08, 2025Recent multi-modal audio-language models (ALMs) excel at text-audio retrieval but struggle with frame-wise audio understanding. Prior works use temporal-aware labels or unsupervised training to improve frame-wise capabilities, but they still lack fine-grained labeling capability to pinpoint when an event occurs. While traditional sound event detection models can precisely localize events, they are limited to pre-defined categories, making them ineffective for real-world scenarios with out-of-distribution events. In this work, we introduce FLAM, an open-vocabulary contrastive audio-language model capable of localizing specific sound events. FLAM employs a memory-efficient and calibrated frame-wise objective with logit adjustment to address spurious correlations, such as event dependencies and label imbalances during training. To enable frame-wise supervision, we leverage a large-scale dataset with diverse audio events, LLM-generated captions and simulation. Experimental results and case studies demonstrate that FLAM significantly improves the open-vocabulary localization capability while maintaining strong performance in global retrieval and downstream tasks.
ReaLJam: Real-Time Human-AI Music Jamming with Reinforcement Learning-Tuned Transformers
Feb 28, 2025Recent advances in generative artificial intelligence (AI) have created models capable of high-quality musical content generation. However, little consideration is given to how to use these models for real-time or cooperative jamming musical applications because of crucial required features: low latency, the ability to communicate planned actions, and the ability to adapt to user input in real-time. To support these needs, we introduce ReaLJam, an interface and protocol for live musical jamming sessions between a human and a Transformer-based AI agent trained with reinforcement learning. We enable real-time interactions using the concept of anticipation, where the agent continually predicts how the performance will unfold and visually conveys its plan to the user. We conduct a user study where experienced musicians jam in real-time with the agent through ReaLJam. Our results demonstrate that ReaLJam enables enjoyable and musically interesting sessions, and we uncover important takeaways for future work.
Hierarchical Generative Modeling of Melodic Vocal Contours in Hindustani Classical Music
Aug 26, 2024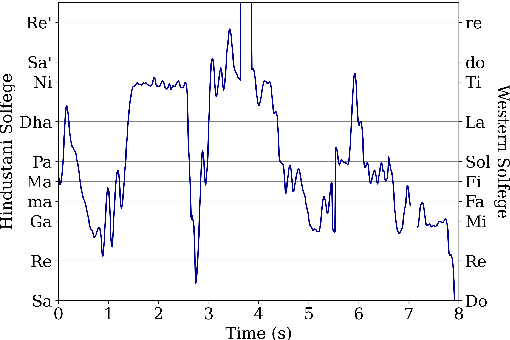
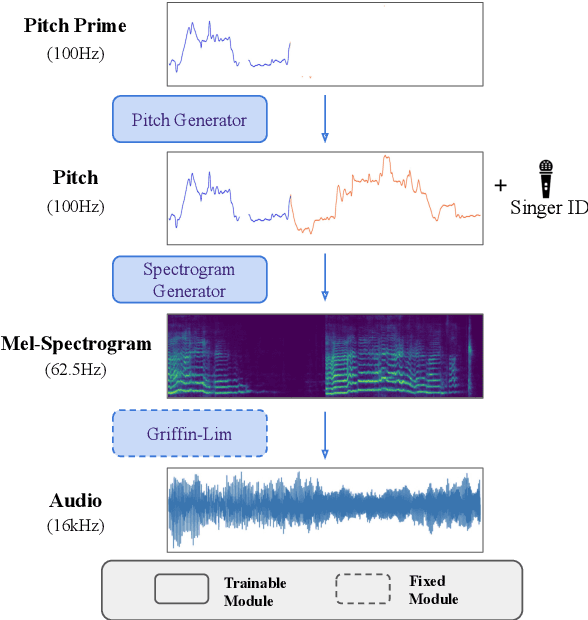
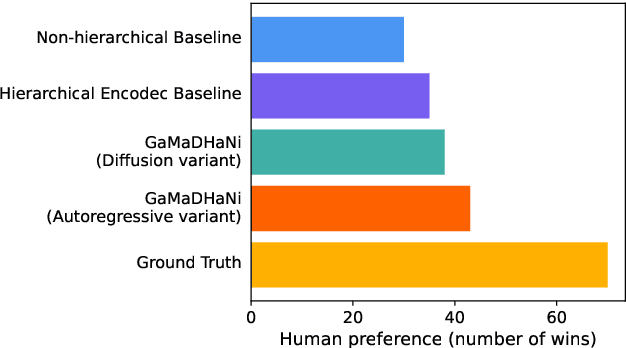
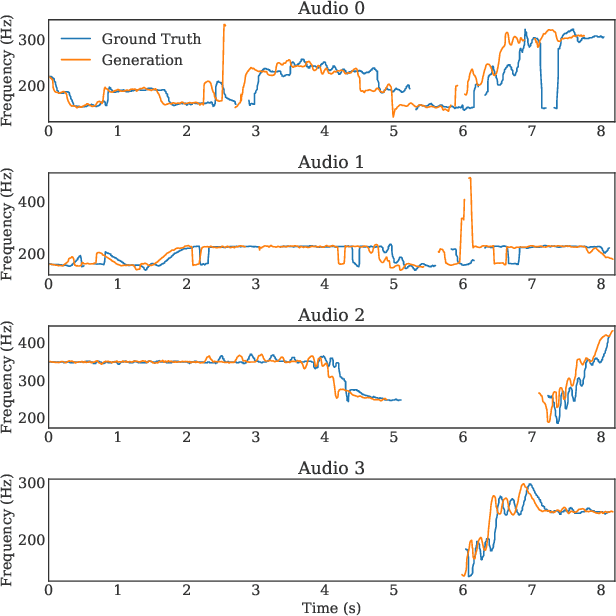
Hindustani music is a performance-driven oral tradition that exhibits the rendition of rich melodic patterns. In this paper, we focus on generative modeling of singers' vocal melodies extracted from audio recordings, as the voice is musically prominent within the tradition. Prior generative work in Hindustani music models melodies as coarse discrete symbols which fails to capture the rich expressive melodic intricacies of singing. Thus, we propose to use a finely quantized pitch contour, as an intermediate representation for hierarchical audio modeling. We propose GaMaDHaNi, a modular two-level hierarchy, consisting of a generative model on pitch contours, and a pitch contour to audio synthesis model. We compare our approach to non-hierarchical audio models and hierarchical models that use a self-supervised intermediate representation, through a listening test and qualitative analysis. We also evaluate audio model's ability to faithfully represent the pitch contour input using Pearson correlation coefficient. By using pitch contours as an intermediate representation, we show that our model may be better equipped to listen and respond to musicians in a human-AI collaborative setting by highlighting two potential interaction use cases (1) primed generation, and (2) coarse pitch conditioning.
The Song Describer Dataset: a Corpus of Audio Captions for Music-and-Language Evaluation
Nov 22, 2023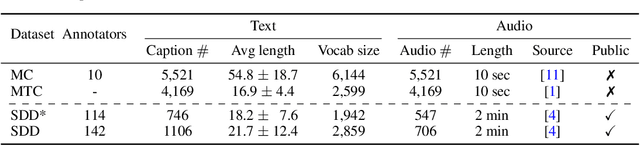


We introduce the Song Describer dataset (SDD), a new crowdsourced corpus of high-quality audio-caption pairs, designed for the evaluation of music-and-language models. The dataset consists of 1.1k human-written natural language descriptions of 706 music recordings, all publicly accessible and released under Creative Common licenses. To showcase the use of our dataset, we benchmark popular models on three key music-and-language tasks (music captioning, text-to-music generation and music-language retrieval). Our experiments highlight the importance of cross-dataset evaluation and offer insights into how researchers can use SDD to gain a broader understanding of model performance.
MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies
Aug 03, 2023



Diffusion models have shown promising results in cross-modal generation tasks, including text-to-image and text-to-audio generation. However, generating music, as a special type of audio, presents unique challenges due to limited availability of music data and sensitive issues related to copyright and plagiarism. In this paper, to tackle these challenges, we first construct a state-of-the-art text-to-music model, MusicLDM, that adapts Stable Diffusion and AudioLDM architectures to the music domain. We achieve this by retraining the contrastive language-audio pretraining model (CLAP) and the Hifi-GAN vocoder, as components of MusicLDM, on a collection of music data samples. Then, to address the limitations of training data and to avoid plagiarism, we leverage a beat tracking model and propose two different mixup strategies for data augmentation: beat-synchronous audio mixup and beat-synchronous latent mixup, which recombine training audio directly or via a latent embeddings space, respectively. Such mixup strategies encourage the model to interpolate between musical training samples and generate new music within the convex hull of the training data, making the generated music more diverse while still staying faithful to the corresponding style. In addition to popular evaluation metrics, we design several new evaluation metrics based on CLAP score to demonstrate that our proposed MusicLDM and beat-synchronous mixup strategies improve both the quality and novelty of generated music, as well as the correspondence between input text and generated music.
Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
Nov 12, 2022Contrastive learning has shown remarkable success in the field of multimodal representation learning. In this paper, we propose a pipeline of contrastive language-audio pretraining to develop an audio representation by combining audio data with natural language descriptions. To accomplish this target, we first release LAION-Audio-630K, a large collection of 633,526 audio-text pairs from different data sources. Second, we construct a contrastive language-audio pretraining model by considering different audio encoders and text encoders. We incorporate the feature fusion mechanism and keyword-to-caption augmentation into the model design to further enable the model to process audio inputs of variable lengths and enhance the performance. Third, we perform comprehensive experiments to evaluate our model across three tasks: text-to-audio retrieval, zero-shot audio classification, and supervised audio classification. The results demonstrate that our model achieves superior performance in text-to-audio retrieval task. In audio classification tasks, the model achieves state-of-the-art performance in the zero-shot setting and is able to obtain performance comparable to models' results in the non-zero-shot setting. LAION-Audio-630K and the proposed model are both available to the public.
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022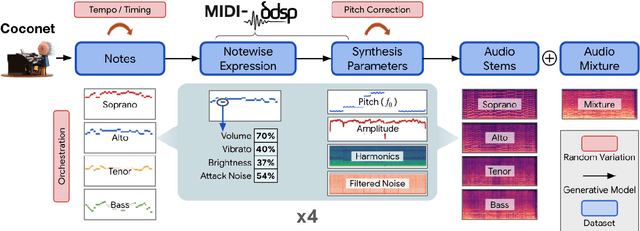
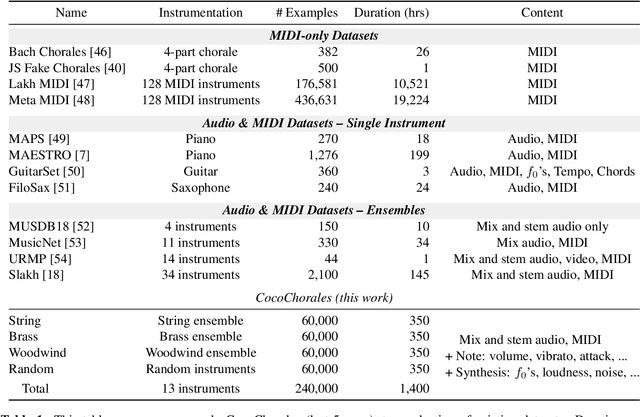
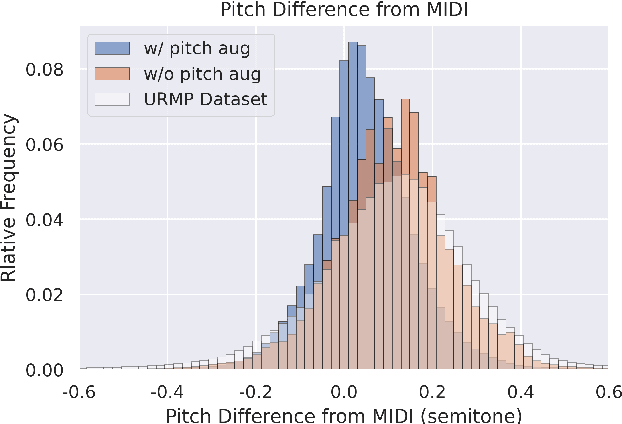
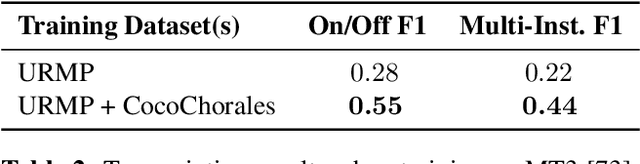
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling
Dec 17, 2021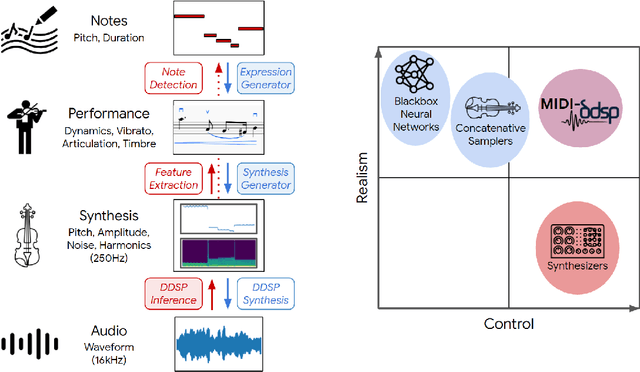
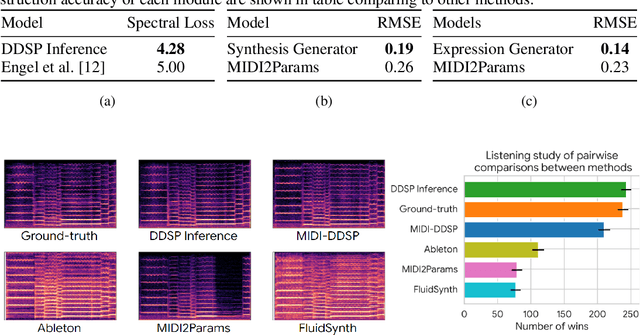
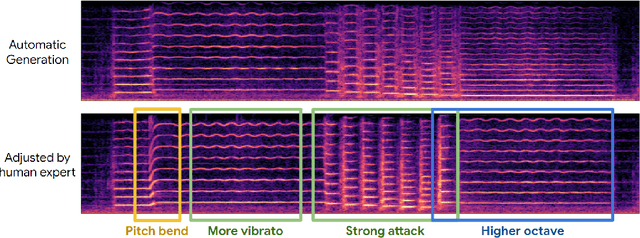
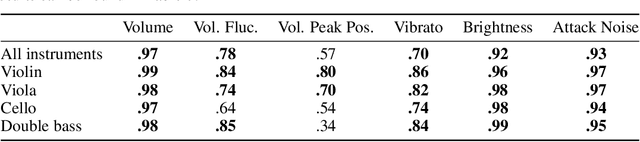
Musical expression requires control of both what notes are played, and how they are performed. Conventional audio synthesizers provide detailed expressive controls, but at the cost of realism. Black-box neural audio synthesis and concatenative samplers can produce realistic audio, but have few mechanisms for control. In this work, we introduce MIDI-DDSP a hierarchical model of musical instruments that enables both realistic neural audio synthesis and detailed user control. Starting from interpretable Differentiable Digital Signal Processing (DDSP) synthesis parameters, we infer musical notes and high-level properties of their expressive performance (such as timbre, vibrato, dynamics, and articulation). This creates a 3-level hierarchy (notes, performance, synthesis) that affords individuals the option to intervene at each level, or utilize trained priors (performance given notes, synthesis given performance) for creative assistance. Through quantitative experiments and listening tests, we demonstrate that this hierarchy can reconstruct high-fidelity audio, accurately predict performance attributes for a note sequence, independently manipulate the attributes of a given performance, and as a complete system, generate realistic audio from a novel note sequence. By utilizing an interpretable hierarchy, with multiple levels of granularity, MIDI-DDSP opens the door to assistive tools to empower individuals across a diverse range of musical experience.
An Encoder-Decoder Based Audio Captioning System With Transfer and Reinforcement Learning
Aug 05, 2021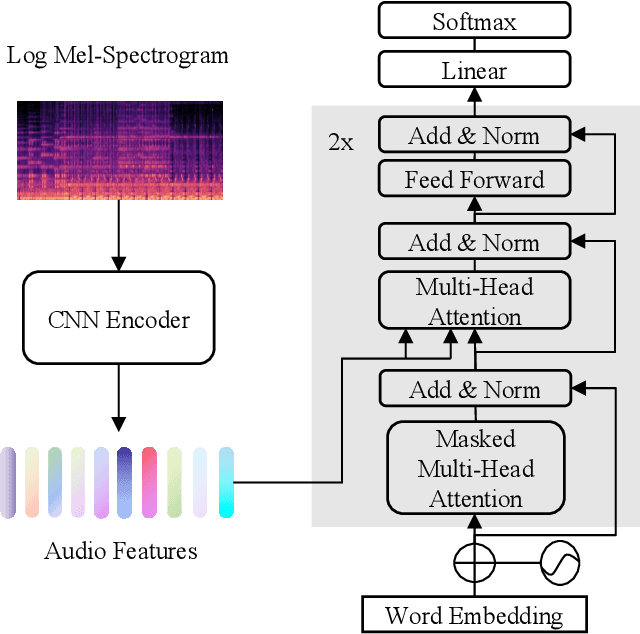
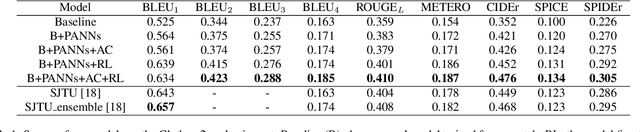


Automated audio captioning aims to use natural language to describe the content of audio data. This paper presents an audio captioning system with an encoder-decoder architecture, where the decoder predicts words based on audio features extracted by the encoder. To improve the proposed system, transfer learning from either an upstream audio-related task or a large in-domain dataset is introduced to mitigate the problem induced by data scarcity. Besides, evaluation metrics are incorporated into the optimization of the model with reinforcement learning, which helps address the problem of ``exposure bias'' induced by ``teacher forcing'' training strategy and the mismatch between the evaluation metrics and the loss function. The resulting system was ranked 3rd in DCASE 2021 Task 6. Ablation studies are carried out to investigate how much each element in the proposed system can contribute to final performance. The results show that the proposed techniques significantly improve the scores of the evaluation metrics, however, reinforcement learning may impact adversely on the quality of the generated captions.