 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Hierarchical Generative Modeling of Melodic Vocal Contours in Hindustani Classical Music
Aug 26, 2024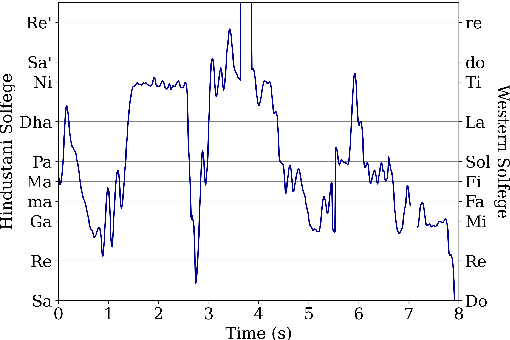
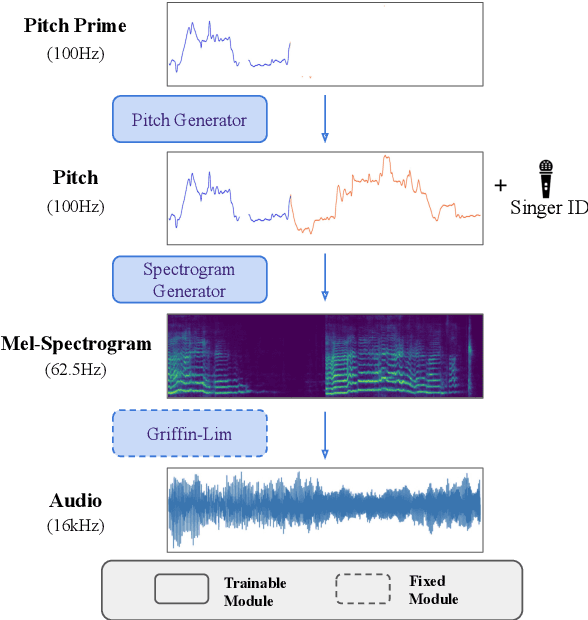
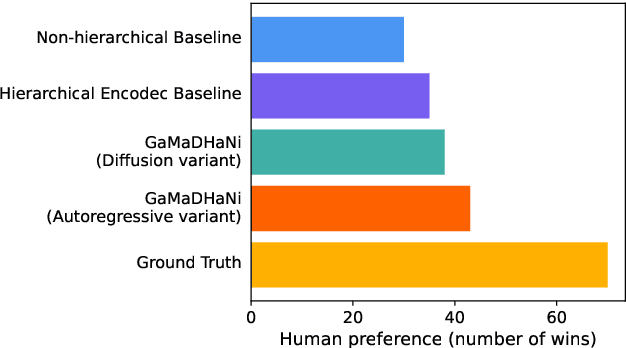
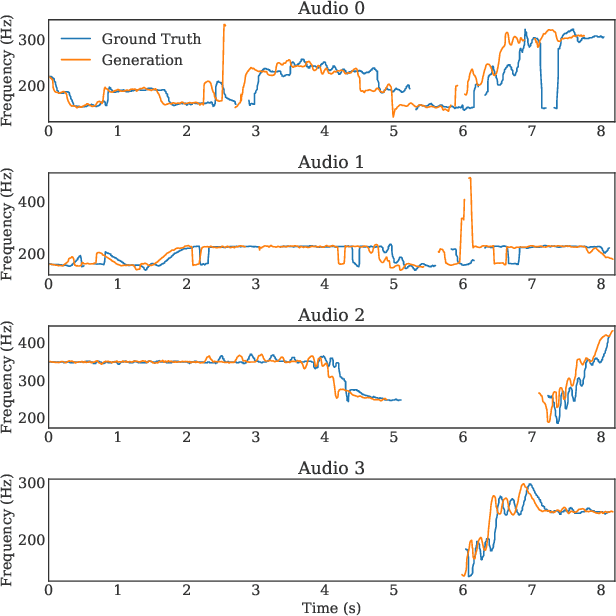
Hindustani music is a performance-driven oral tradition that exhibits the rendition of rich melodic patterns. In this paper, we focus on generative modeling of singers' vocal melodies extracted from audio recordings, as the voice is musically prominent within the tradition. Prior generative work in Hindustani music models melodies as coarse discrete symbols which fails to capture the rich expressive melodic intricacies of singing. Thus, we propose to use a finely quantized pitch contour, as an intermediate representation for hierarchical audio modeling. We propose GaMaDHaNi, a modular two-level hierarchy, consisting of a generative model on pitch contours, and a pitch contour to audio synthesis model. We compare our approach to non-hierarchical audio models and hierarchical models that use a self-supervised intermediate representation, through a listening test and qualitative analysis. We also evaluate audio model's ability to faithfully represent the pitch contour input using Pearson correlation coefficient. By using pitch contours as an intermediate representation, we show that our model may be better equipped to listen and respond to musicians in a human-AI collaborative setting by highlighting two potential interaction use cases (1) primed generation, and (2) coarse pitch conditioning.
SingSong: Generating musical accompaniments from singing
Jan 30, 2023
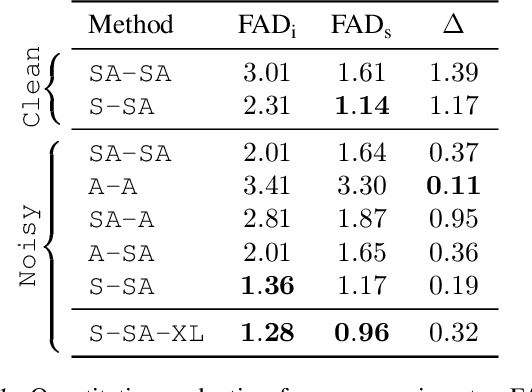
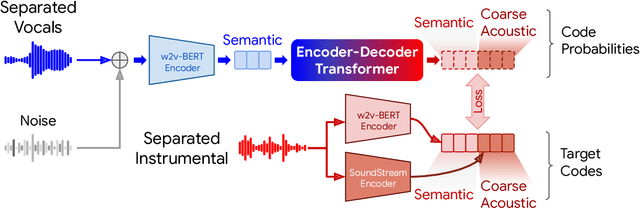
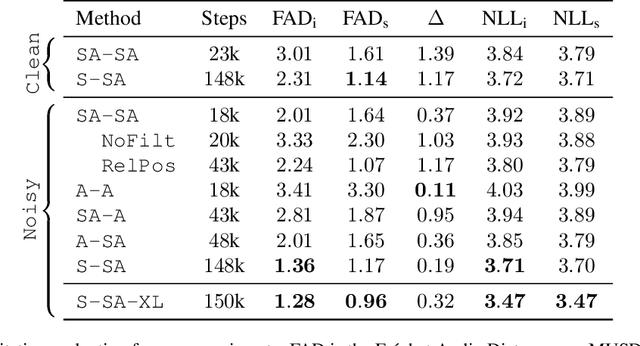
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at https://g.co/magenta/singsong
MusicLM: Generating Music From Text
Jan 26, 2023



We introduce MusicLM, a model generating high-fidelity music from text descriptions such as "a calming violin melody backed by a distorted guitar riff". MusicLM casts the process of conditional music generation as a hierarchical sequence-to-sequence modeling task, and it generates music at 24 kHz that remains consistent over several minutes. Our experiments show that MusicLM outperforms previous systems both in audio quality and adherence to the text description. Moreover, we demonstrate that MusicLM can be conditioned on both text and a melody in that it can transform whistled and hummed melodies according to the style described in a text caption. To support future research, we publicly release MusicCaps, a dataset composed of 5.5k music-text pairs, with rich text descriptions provided by human experts.
Streamable Neural Audio Synthesis With Non-Causal Convolutions
Apr 14, 2022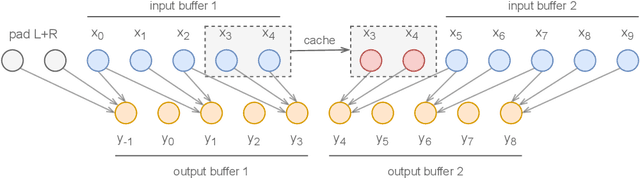
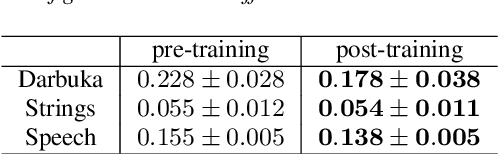
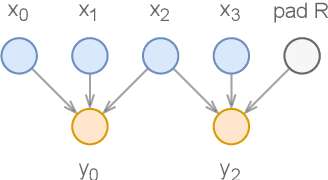
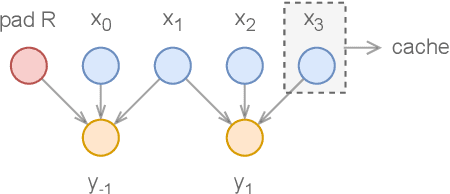
Deep learning models are mostly used in an offline inference fashion. However, this strongly limits the use of these models inside audio generation setups, as most creative workflows are based on real-time digital signal processing. Although approaches based on recurrent networks can be naturally adapted to this buffer-based computation, the use of convolutions still poses some serious challenges. To tackle this issue, the use of causal streaming convolutions have been proposed. However, this requires specific complexified training and can impact the resulting audio quality. In this paper, we introduce a new method allowing to produce non-causal streaming models. This allows to make any convolutional model compatible with real-time buffer-based processing. As our method is based on a post-training reconfiguration of the model, we show that it is able to transform models trained without causal constraints into a streaming model. We show how our method can be adapted to fit complex architectures with parallel branches. To evaluate our method, we apply it on the recent RAVE model, which provides high-quality real-time audio synthesis. We test our approach on multiple music and speech datasets and show that it is faster than overlap-add methods, while having no impact on the generation quality. Finally, we introduce two open-source implementation of our work as Max/MSP and PureData externals, and as a VST audio plugin. This allows to endow traditional digital audio workstation with real-time neural audio synthesis on a laptop CPU.
RAVE: A variational autoencoder for fast and high-quality neural audio synthesis
Nov 09, 2021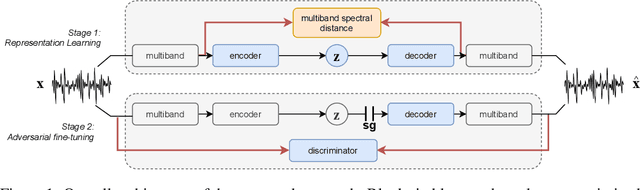
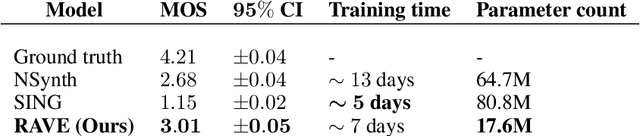
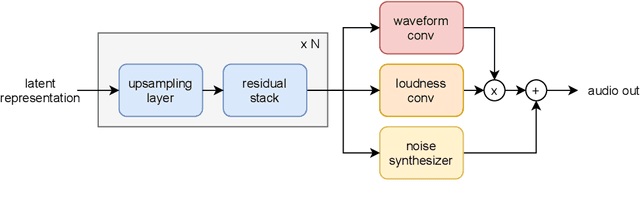

Deep generative models applied to audio have improved by a large margin the state-of-the-art in many speech and music related tasks. However, as raw waveform modelling remains an inherently difficult task, audio generative models are either computationally intensive, rely on low sampling rates, are complicated to control or restrict the nature of possible signals. Among those models, Variational AutoEncoders (VAE) give control over the generation by exposing latent variables, although they usually suffer from low synthesis quality. In this paper, we introduce a Realtime Audio Variational autoEncoder (RAVE) allowing both fast and high-quality audio waveform synthesis. We introduce a novel two-stage training procedure, namely representation learning and adversarial fine-tuning. We show that using a post-training analysis of the latent space allows a direct control between the reconstruction fidelity and the representation compactness. By leveraging a multi-band decomposition of the raw waveform, we show that our model is the first able to generate 48kHz audio signals, while simultaneously running 20 times faster than real-time on a standard laptop CPU. We evaluate synthesis quality using both quantitative and qualitative subjective experiments and show the superiority of our approach compared to existing models. Finally, we present applications of our model for timbre transfer and signal compression. All of our source code and audio examples are publicly available.
Timbre latent space: exploration and creative aspects
Aug 17, 2020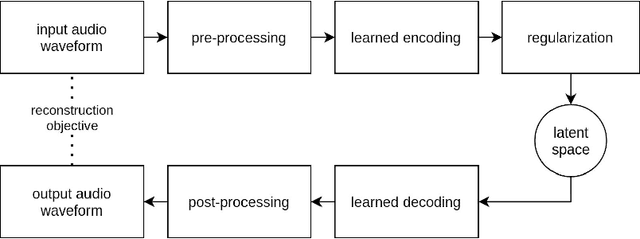
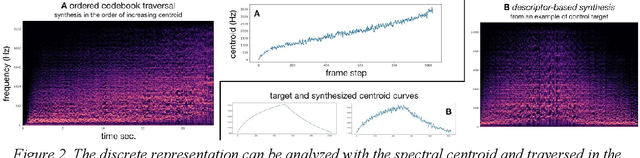
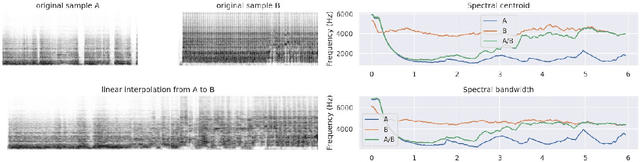
Recent studies show the ability of unsupervised models to learn invertible audio representations using Auto-Encoders. They enable high-quality sound synthesis but a limited control since the latent spaces do not disentangle timbre properties. The emergence of disentangled representations was studied in Variational Auto-Encoders (VAEs), and has been applied to audio. Using an additional perceptual regularization can align such latent representation with the previously established multi-dimensional timbre spaces, while allowing continuous inference and synthesis. Alternatively, some specific sound attributes can be learned as control variables while unsupervised dimensions account for the remaining features. New possibilities for timbre manipulations are enabled with generative neural networks, although the exploration and the creative use of their representations remain little. The following experiments are led in cooperation with two composers and propose new creative directions to explore latent sound synthesis of musical timbres, using specifically designed interfaces (Max/MSP, Pure Data) or mappings for descriptor-based synthesis.
Diet deep generative audio models with structured lottery
Jul 31, 2020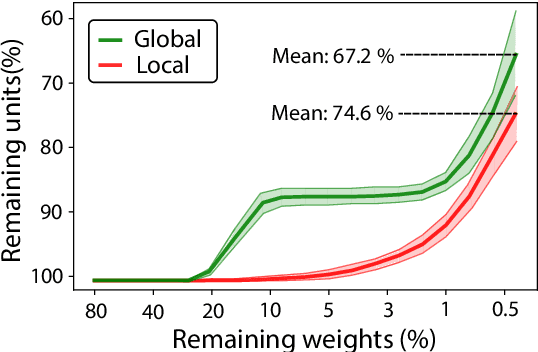
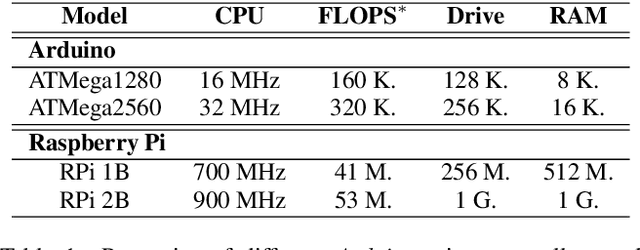
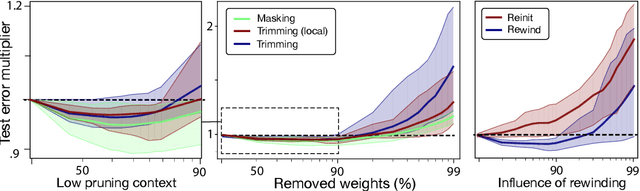
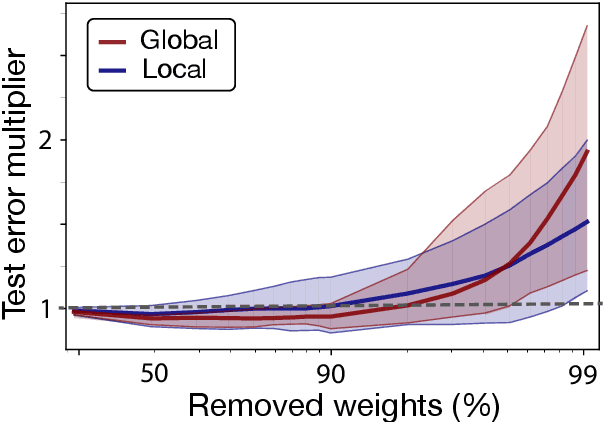
Deep learning models have provided extremely successful solutions in most audio application fields. However, the high accuracy of these models comes at the expense of a tremendous computation cost. This aspect is almost always overlooked in evaluating the quality of proposed models. However, models should not be evaluated without taking into account their complexity. This aspect is especially critical in audio applications, which heavily relies on specialized embedded hardware with real-time constraints. In this paper, we build on recent observations that deep models are highly overparameterized, by studying the lottery ticket hypothesis on deep generative audio models. This hypothesis states that extremely efficient small sub-networks exist in deep models and would provide higher accuracy than larger models if trained in isolation. However, lottery tickets are found by relying on unstructured masking, which means that resulting models do not provide any gain in either disk size or inference time. Instead, we develop here a method aimed at performing structured trimming. We show that this requires to rely on global selection and introduce a specific criterion based on mutual information. First, we confirm the surprising result that smaller models provide higher accuracy than their large counterparts. We further show that we can remove up to 95% of the model weights without significant degradation in accuracy. Hence, we can obtain very light models for generative audio across popular methods such as Wavenet, SING or DDSP, that are up to 100 times smaller with commensurate accuracy. We study the theoretical bounds for embedding these models on Raspberry Pi and Arduino, and show that we can obtain generative models on CPU with equivalent quality as large GPU models. Finally, we discuss the possibility of implementing deep generative audio models on embedded platforms.
Assisted Sound Sample Generation with Musical Conditioning in Adversarial Auto-Encoders
Apr 12, 2019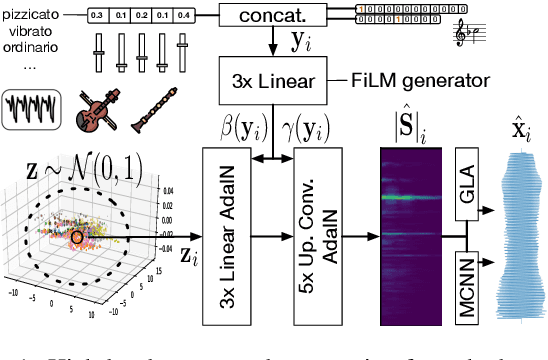
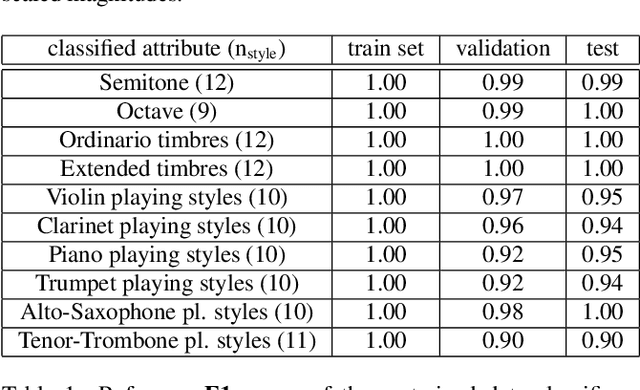
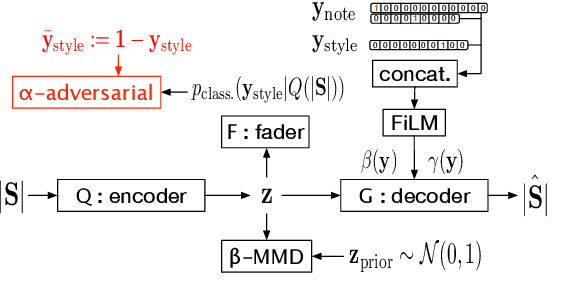
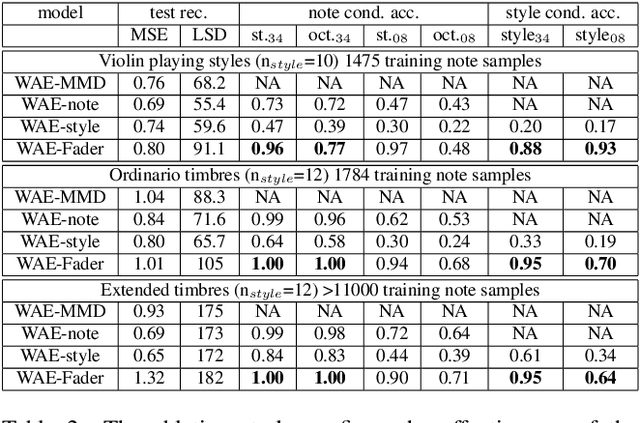
Generative models have thrived in computer vision, enabling unprecedented image processes. Yet the results in audio remain less advanced. Our project targets real-time sound synthesis from a reduced set of high-level parameters, including semantic controls that can be adapted to different sound libraries and specific tags. These generative variables should allow expressive modulations of target musical qualities and continuously mix into new styles. To this extent we train AEs on an orchestral database of individual note samples, along with their intrinsic attributes: note class, timbre domain and extended playing techniques. We condition the decoder for control over the rendered note attributes and use latent adversarial training for learning expressive style parameters that can ultimately be mixed. We evaluate both generative performances and latent representation. Our ablation study demonstrates the effectiveness of the musical conditioning mechanisms. The proposed model generates notes as magnitude spectrograms from any probabilistic latent code samples, with expressive control of orchestral timbres and playing styles. Its training data subsets can directly be visualized in the 3D latent representation. Waveform rendering can be done offline with GLA. In order to allow real-time interactions, we fine-tune the decoder with a pretrained MCNN and embed the full waveform generation pipeline in a plugin. Moreover the encoder could be used to process new input samples, after manipulating their latent attribute representation, the decoder can generate sample variations as an audio effect would. Our solution remains rather fast to train, it can directly be applied to other sound domains, including an user's libraries with custom sound tags that could be mapped to specific generative controls. As a result, it fosters creativity and intuitive audio style experimentations.